I am not really a fan of Dark Mode — I like my screens bright and shiny. But it’s October, and it’s sometimes fun to make things dark and spooky.
Some users of my Show Browser Version extension wanted it to better support Dark Mode– the default text colors didn’t work well when the browser frame was black. I landed a simple change to select bright text colors when the browser is in Dark Mode and called it done.
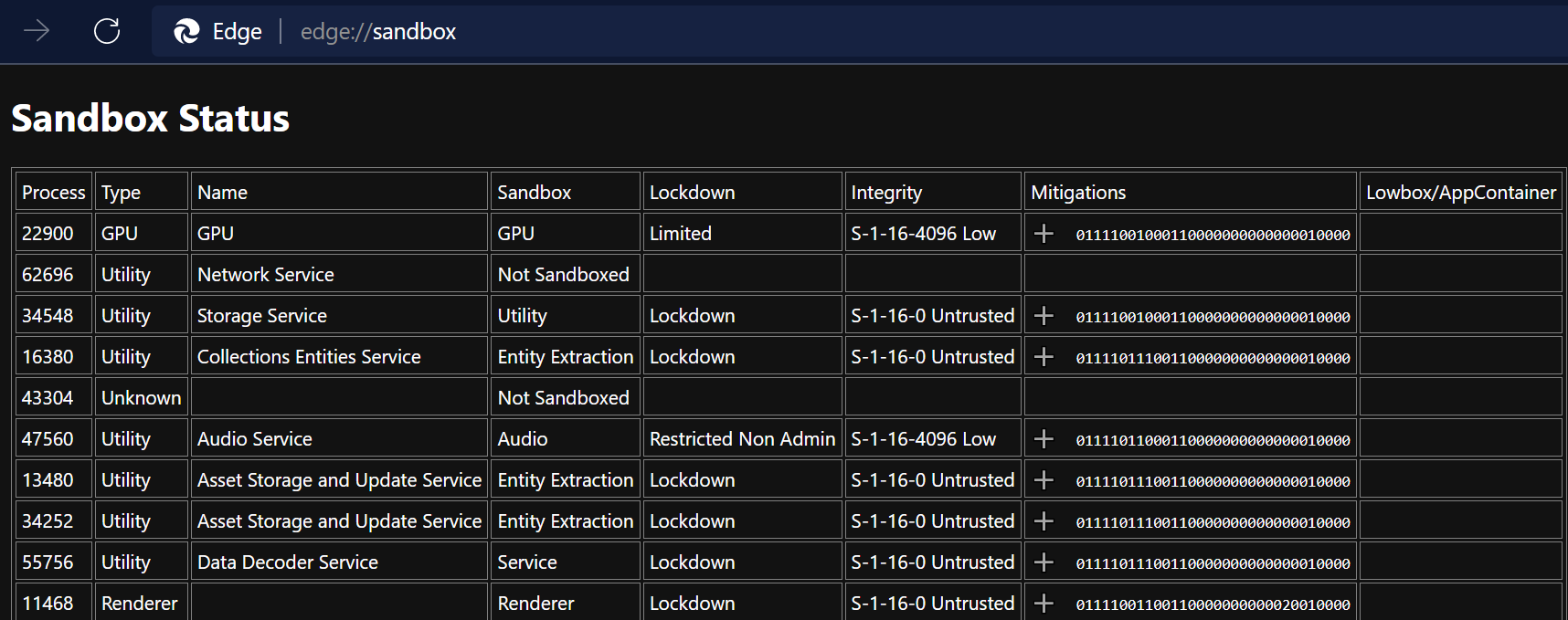
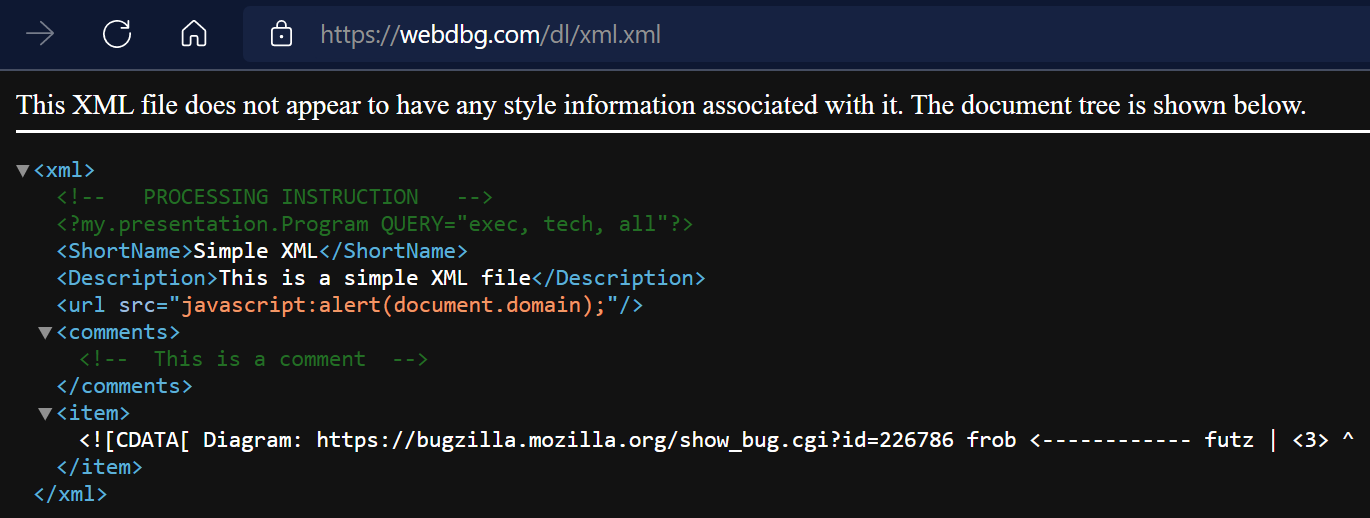
However, after testing my updates, I lazily left my Dev Channel browser in Dark Mode. Over the following months, I noticed that a surprising number of Chromium’s built-in pages were still rendering in brilliant white. Encountering a bright white screen after surfing around in dark mode can be jarring, to say the least.
I wondered how hard it would be to fix some of these pages. The answer, it turns out, is “it’s mostly trivial.”
To indicate that a page supports dark mode styling, simply add a color-scheme meta tag to the head section of the HTML:
<meta name="color-scheme" content="light dark">
Alternatively, add the following rule to the CSS:
:root {
color-scheme: light dark;
}
Either change alone is enough for simple pages to render nicely in Dark Mode.
However, many pages use more colors than just the default text and background color, so new colors to be used in Dark Mode must be selected. To adjust colors based on the dark mode preference, use the prefers-color-scheme media query to override the default color in your stylesheet. For example:
#tab-list a:hover {
color: white;
}
@media (prefers-color-scheme: dark) {
#tab-list a:hover {
color: black;
}
}
Tip: Use CSS Variables for Dynamic Updates
When I first updated the about:Net-Internals page, I added dark mode detection and colors to a JavaScript function used to temporarily highlight a div:
function highlightFade(element) {
const isDarkMode =
window.matchMedia('(prefers-color-scheme: dark)').matches;
element.style.transitionProperty = 'background-color';
element.style.transitionDuration = '0s';
element.style.backgroundColor =
isDarkMode ? '#03DCB0' : '#fffccf';
setTimeout(function() {
element.style.transitionDuration = '1s';
element.style.backgroundColor =
isDarkMode ? '#121212' : '#fff';
}, 0);
}
However, I noticed a downside to this approach– if I changed my OS color theme from Light to Dark after this function had run without reloading the page, the old white (#fff) background color lingered on the div— it didn’t update to dark like the rest of the background of the page.
The fix was to specify the light and dark colors using CSS Variables within the stylesheet:
:root {
--color-active-tab: black;
--color-background: #fff;
--color-highlight: #fffccf;
}
@media (prefers-color-scheme: dark) {
:root {
--color-active-tab: white;
--color-background: #121212;
--color-highlight: #03DCB0;
}
}
…and update the JavaScript function to reference them:
function highlightFade(element) {
element.style.transitionProperty = 'background-color';
element.style.transitionDuration = '0s';
element.style.backgroundColor = "var(--color-highlight)";
setTimeout(function() {
element.style.transitionDuration = '1s';
element.style.backgroundColor = "var(--color-background)";
}, 0);
}
Now, as the OS switches between light/dark, the CSS variable is recalculated and the colors in the page are updated automatically.
Tip: UA Stylesheets are Special
Updating Chromium’s View-Source to support Dark Mode was a bit trickier, because the styles used in View-Source rendering come from a User-Agent stylesheet. Unlike a regular stylesheet, UA Stylesheets’ support for Media Queries is very limited, and prefers-color-scheme is not allowed.
The solution turns out to be pretty simple: instead of using a media query, we express colors using a special (only usable in UA Stylesheets) function, LightDarkValuePair that returns one of its two color arguments based on whether light or dark theme is in use:
color: -internal-light-dark(#00e, rgb(159, 180, 214));
This allows the View-Source page to respect dark mode without needing a media query.
View-Source also uses a bunch of different text colors for syntax-highlighting, so I had to override those– to avoid picking my own colors, I borrowed the colors from the dark mode support in the Developer Tools.
Changelists and Bugs
There’s still more to do (e.g. text, json) but here’s a list of updates I’ve made so far:
Some of these changes are so simple you can even make them using Chromium’s web-based editor!
-Eric
Appendix: Other Dark Mode trivia
The edge://settings UI for themes is the correct way to set Dark Mode for the browser, and it will affect pages that are designed to respect Dark Mode using the prefers-color-scheme
A big limitation of Dark Mode when it comes to web content is that there are a great many pages that are not designed to support Dark Mode and as a consequence changing the browser to Dark Mode has no impact at all on the rendering of the website. That’s where the “Auto Dark Mode for Web Contents” feature flag on edge://flags comes into play. That experimental feature forces a site into Dark Mode, replacing its color scheme with one computed by the browser. This works well on some sites, but less well on others. A site can manually opt-out of the automatic mode, but few will.