Microsoft Defender for Endpoint is a paid security product that extends Microsoft Defender Antivirus (included for free in Windows) with enterprise capabilities, including a full EDR product that reports security telemetry into a security operations center (SOC).
Some recently-retired Microsoft employees have been surprised to discover that their personal PCs that had previously been used in a BYOD (bring your own device) manner are still applying Microsoft Internal IT security policies. For example, an ex-employee might see this block from Network Protection when visiting Grammarly.com:
When this happens, the user is often confused, either thinking Microsoft Defender is blocking everyone from visiting Grammarly’s website (it’s not), or realizing that it’s only their device previously used for work but not understanding why/how.
Some ex-employees are especially confused because they know that they remembered to “offboard” their device from Microsoft Corp, leaving the domain and/or performing the Intune offboarding process.
The confusion arises because Microsoft Defender for Endpoint doesn’t care whether your device has been disjoined from the domain or offboarded from Intune policies: neither of those actions will offboard your device from the enterprise’s Microsoft Defender tenant.
Today, the Windows Security app makes no mention of the fact that a given device is onboarded to a Microsoft Defender tenant:
Unfortunately, Defender-onboarded machines don’t mention this in the Windows Security App
To see whether your device is onboarded, you can check the registry. Look inside the HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Advanced Threat Protection key for the OnboardedInfo for information about which tenant your device is onboarded to. The senseId and senseGuid are the unique identifiers sent to the SOC when reporting security telemetry.
To offboard your device from an enterprise’s Defender tenant, you can’t simply delete a few registry keys and call it a day. Many of Defender’s registry keys and services are protected from modification by Tamper Prevention code inside Defender’s kernel module that’s designed to prevent unauthorized modifications.
Instead, to offboard you must run a signed offboarding script generated by the organization. The script notifies the MDE client that the machine should be offboarded. Only after the client verifies the validity (signature, expiration) of the offboarding blob will the device successfully offboard. These validity checks are critical, because otherwise initial access malware on a device could simply begin its attack by offboarding the device before further elevating privileges, moving laterally, and attacking the rest of the organization.
Unfortunately for ex-employees without access to their former-company’s IT helpdesk (to allow them to run the offboarding script), the easiest way to resolve this situation is to back up your files and then reinstall Windows.
This document contains some thoughts about the storage and comparison of URLs, common operations crucial to the correct function of security software like Microsoft SmartScreen.
Importantly, URLs are also displayed on security surfaces to enable the user to make a decision based on their contents. Eight years ago, I wrote the Guidelines for URL Display.
Background
The Web allows linking and retrieval of various resources via an address known as a URL. A URL (Uniform Resource Locator) is an identifier used to locate a resource on the Internet. (Note: “URI” stands for Uniform Resource Identifier, and in the real world, the two terms are used interchangeably).
It’s tempting to think of URLs as plain strings because almost all clients (like web browsers) and servers accept URL input as strings. However, despite the existence of various standards for the representation of URLs, there is considerable variation in the handling of URLs that creates inconsistency and variability in the interpretation of URL values. Additional complexity arises because URLs can include seldom-used components that must be understood to properly interpret the URL, and the URL syntax varies between different URL protocol schemes (e.g. HTTPS/HTTP/FTP/mailto/blob/data, etc).
The complexity of URLs is often exploited by attackers, either to socially-engineer users (as in phishing attacks) or to bypass security checks in code.
URL Encoding as Strings
In their canonical form, HTTPS/HTTP URLs are meant to contain only a subset of US-ASCII characters, where characters outside of that subset (e.g. emojis; international character sets like Cyrillic, Hiragana, Katakana, Kanji, etc; and ASCII characters like :@/\?# that are reserved for use to delimit URL components) are meant to be escaped. Escaping is a system whereby a character’s UTF-8 octet (byte) representation is serialized to ASCII by preceding each octet’s value with a % character. For example, the URL:
In this example, the 자 (Hangul Syllable Ja) character has the UTF-8 encoding 0xEC 0x9E 0x90, which is escaped in the URL to the sequence %EC%9E%90, while the Փ (Armenian Capital Letter Piwr) character with the UTF-8 encoding 0xD5 0x93 is escaped to %D5%93.
The hostname of the URL does not use %-escaping, instead relying on a much more complicated escaping mechanism (Punycode), wherein each DNS label component containing non-ASCII characters is prefixed by xn-- followed by ASCII text that encodes any non-ASCII characters. For instance, a URL containing hostname characters from Thai and Latin character sets:
However, not all clients properly support standards-based encoding behaviors– some clients aim to maintain legacy compatibility with behaviors that existed before the current standards were written.
In particular, Microsoft’s MSHTML (and the WinINET network stack beneath it) used by Internet Explorer, Web Browser Controls (WebOCs) and other common Windows platform features, only implements the standards-based behavior when certain flags are set. Otherwise, MSHTML can put raw UTF-8 octets in the hostname component, and put ANSI codepaged (ACP) octets in the path, query, and fragment components.
The snowman emoji is properly UTF-8 escaped in the path component, and it is thunked down to a question mark ? in the query component (as the target character doesn’t exist in the system codepage). However, if we instead pick a character in the system codepage, we see the path component is UTF-8 escaped, but the query string’s raw ACP octet is put out on the wire:
Furthermore, this path-escaping is sensitive to the checkbox in the Internet Control panel, such that even the path may be sent without escaping if the “Send URL path as UTF-8” checkbox is unticked:
The Default URLMon codepath sets those options inside based on conditional logic, while the EdgeHTML fork of URLMon more simply sets them. Computation of the options is complex: for instance, Edge Legacy checks not only the Zone but also allows a Microsoft-delivered CompatView list to weigh in on the proper encoding.
Beyond the WinINET behavior, it is believed that many other HTTP stacks do not properly handle corner-cases (e.g. being passed URLs that do not follow standards-based escaping rules, contain octet sequences that cannot be validly represented in Unicode, utilize overlong encodings, etc.
URL Components
A URL is made up of a sequence of components. For example, an absolute URL containing all available components for the HTTPS protocol scheme might look like this:
In contrast, a relative URL, as seen within a web page, might be as simple as /file.html.
Making URLs Absolute: Combine
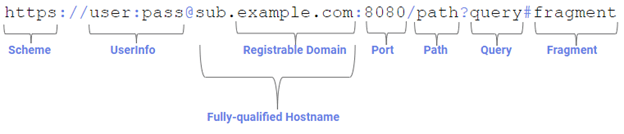
Relative URLs are rarely usable on their own; typically, the first thing that code must do before operating on a relative URL is convert it to an absolute URL by performing a combine operation on the relative URL with the absolute URL of its context (e.g. the web page in which it appears) to generate a new absolute URL. For example, combining https://user:pass@sub.example.com:8080/path?query#fragment with /file.html results in an absolute URL of https://user:pass@sub.example.com:8080/file.html. In this combination operation, the context URL’s path is overwritten, and its query and fragment components are dropped.
Deep Dive: Components
Let’s look at each of the URL components and explore how attackers might attempt to confuse code or humans with each component.
Component: Scheme
The scheme component of the URL designates what underlying protocol should be used to retrieve the information, as well as dictating the rules for interpreting the rest of the URL, including whether it uses the standard hierarchical syntax (e.g. HTTP/HTTPS/FTP/FILE) or the opaquegeneric syntax (e.g. mailto/data/blob).
Clients only support a limited set of URL schemes. Adding new schemes to browsers to retrieve resources or to open external applications generally requires installing native code; a web-platform mechanism allows adding schemes from JavaScript, but when invoked the custom-scheme URL is simply translated into a HTTPS URL for further use.
Security Considerations: Supported Scope
Each security-sensitive client must consider how it handles less common URL schemes; many clients will block all URLs except those using popular schemes (HTTP/HTTPS/mailto), but some clients (e.g. browsers) must support invocation of arbitrary URLs.
Because uncommon schemes are a common vector of security compromise, the decision of how to handle such schemes is an important one. If a security mechanism deems certain schemes out-of-scope, then the user could be exploited by those schemes. For example, mailto: links can be used in phishing:
Security Considerations: Parsing changes by Scheme
Each feature that attempts to analyze a URL for security purposes must understand the scheme of the URL and the rules by which it is parsed. For example, a mailto URL uses the format mailto:user@host.com?subject=messagecontent whereby the Internet address appears in the middle of the URL alongside other optional field content.
Security Considerations: Not All Schemes are Routable
Some URL schemes do not refer to a server on the internet; the most broadly supported and commonly used of these are the data and blob schemes.
A data: schemed URL contains the entire resource to which it refers. For example, if a client fetches the URL data:text/html;base64,PGgxPkhlbGxvIHdvcmxkPC9oMT4=, the result is the string <h1>Hello world</h1>, the base-64 decoding of the substring beginning PGg and ending with 4=.
A blob schemed URL refers to a resource which exists only in the memory of the JavaScript context that generated the URL via the createObjectURL() JavaScript method. JavaScript running inside a web page at https://webdbg.com/test/data.htm might generate a blob URL that looks like this:
When fetched from JavaScript inside the originating webpage, that blob URL will return an object (anything from an image to a file download to a HTML document). However, attempting to fetch that same blob URL from any other device (or even another browser window on the same device) will not return any content, because the blob scheme is not globally routable.
Security Considerations: The FILE Scheme is Weird
The file scheme allows routing a request to a file on either the local file system or the filesystem of a remote server. A URL like file:///C:/test.html refers to a file on C: drive of the system where the fetch retrieval occurs, while file://serverhostname/docs/test.html refers to a file on the share named docs on the server named serverhostname.
Fortunately, use of the file scheme in modern browsers is somewhat restricted because retrieving file URLs can result in assorted security and privacy badness, including fingerprinting the apps on the user’s computer or leaking the user’s Windows password hash to a remote servers.
Component: Authority
The Authority component of the URL consists of three subcomponents: userinfo, the fully-qualified hostname, and the port.
Component: UserInfo
The userinfo subcomponent of a URL specifies a username and password that the client should use when authenticating to a server. This subcomponent is only defined for certain URL schemes (e.g. FTP), while it is officially invalid for others (e.g. HTTP and HTTPS) but nevertheless supported (e.g. Firefox and Chromium allow userinfo for HTTP and HTTPS URLs).
Security Considerations: UserInfo UI Spoofing
Way back in Internet Explorer 6, IE started forbidding HTTP/HTTPS URLs containing userinfo because this obscure subcomponent’s primary real-world use was to confuse the user as a part of phishing attacks. Because the UserInfo is typically not present in URLs, a user looking at the URL https://victim.com:80@random.text.evil.com/ will often assume that they are looking at content from victim.com rather than from random.text.evil.com.
This threat vector is not terribly common today: Chromium hides the UserInfo component in its address bar, while Firefox explicitly warns the user about this threat:
The most security-relevant part of a URL is the fully-qualified hostname of the URL. The hostname is registered by an individual or business (e.g. PayPal, Inc. owns Paypal.com) with the relevant DNS registrar of the top-Level domain (e.g. Verisign controls the .com top-level domain).
Security Considerations: Transport Security
If the URL’s scheme is secure (e.g. HTTPS), content delivered from a given hostname is deemed to be under the control of the entity that registered the hostname (modulo compromised infrastructure, etc). However, if the scheme refers to a non-secure protocol like HTTP, and especially if the protocol traverses an untrusted network, the registrable domain information may not accurately describe the true source of the content because the content may have been modified by a man-in-the-middle on the network. The port number only needs to be specified if it is not the default for the scheme (e.g., 80 for HTTP, 443 for HTTPS).
Security Considerations: Parsing of IPv6 Literals
When the URL’s hostname is an IPv6 literal, the address is wrapped in square brackets, e.g. http://[::1]:8080/file.html is a reference to a file hosted on port 8080 of the current device’s IPv6 loopback interface. The fact that a colon character can appear before the colon delimiter representing the start of the Authority’s Port subcomponent can confuse a parser unfamiliar with IPv6 addresses.
While there’s no standard for including an IPv6 scope id within a URL, WinINET allows specification of the scope by %-encoding the % delimiter character, e.g. https://[::1%253]/
Security Considerations: Interpretation of IPv4 Literals non-canonical syntax
Most technically savvy users are familiar with IPv4 literal addresses in dotted decimal format, like http://127.0.0.2/. However, dotted decimal is not the only format; you can also express the same address by dropping the 0. components, like http://127.2, with extra 0s like http://127.000000002/, or in decimal notation http://2130706434/, octal notation http://0177.0.0.2/, or hexadecimal notation http://0x7f000002/.
The various serializations of addresses could be used to evade matching logic. Historically, we’ve also seen some code that assumes that any hostname lacking a dot must not be globally routable and belongs to the (more trustworthy) Intranet zone (leading to an MSRC case for Windows/IE in the early 2000s).
Security Considerations: IDN and PunyCode
Support for non-Unicode characters in URLs can lead to spoofing attacks.
Usually, the security context that the user cares about is the registrable domain of the top-level page’s URL’s origin, even when a given page is made up of components from many different origins. The registrable domain typically consists of a subdomain of an entry on the Public Suffix list. For instance, bbc.co.uk is a registrable domain under the co.uk public suffix. The fully-qualified hostname consists of a registrable domain, and optionally one or more subdomain labels.
The port component of the URL indicates which TCP/IP port should be contacted to send the request.
Security Considerations: Shared Servers and “Well-Known” Ports
In general, a server operator is deemed to be in control of all ports on the server, although notably some systems (e.g. Unix) allow low-permissioned users to perform TCP/IP listen operations only on certain ports (>1024) while requiring administrative permissions to listen to “low ports” (<1024) which are the default ports used by popular services (HTTP/HTTPS/FTP).
Security Considerations: Canonicalization Drops Default Port
When canonicalizing a URL, if the specified target port is the default port for the scheme, it should be removed from the URL entirely. For example,
The Web Platform security model uses a term called “Origin” which is comprised of the triplet scheme+fullyQualifiedHostname+port.
Challenges and Threats
Malicious websites are motivated to misrepresent their provenance in order to trick visitors into performing an unsafe action (e.g., phishing, malware install) or to otherwise grant unwarranted trust in the information provided by the site (e.g., “fake news”).
Other components of the URL (subdomain, userinfo, path, query, and fragment) are completely under the control of the website and may be crafted in an attempt to spoof the user by misrepresenting the registrable domain.
URL Comparison
A critical thing security software needs is a consistent function that turns “a pile of octets that some client is treating as a URL” into “a string that the security software considers to be the canonical / common form that we will use in all subsequent matching logic, even if that string would not be accepted by a real server.”
That function will need to handle things like bare-ACP octets appearing anywhere in the string, invalid UTF-16 sequences, raw (non-encoded) UTF-16 codepoints, and anything else we devise.
Canonicalization and Normalization
We’ll also need comparison functions that work correctly both with and without the most common forms of canonicalization/normalization performed by servers (e.g. https://example.com/blah/..///thisisafile.htm matches https://example.com/thisisafile.htm. Similarly, there are many ways to represent equivalent IPv6 literals, and so on.
Matching and “Rollups”
Beyond that, the software needs to decide how closely two URLs must match to be considered equivalent.
For example, http://example.com/PaTH and http://example.com/path are technically different URLs, but in actual practice, they will return the same content on from most servers.
While the port component in the URL is technically a part of the web origin, in actual practice, it is very uncommon for an arbitrary port to be controlled by a different entity than the default port, and there’s no evidence to suggest that any human being will make a different security decision based on the target port number. As such, security software will often ignore the port when comparing URLs. In Microsoft SmartScreen, for example, a rule set to block https://x.com (implicitly port 443 due to the HTTPS scheme) will also block requests to http://x.com:12345.
Any URL matching function needs to decide how closely two URLs must match; in SmartScreen, we call this roll-up, meaning “Will a block for X.com block X.com/something? What about sub.x.com/anything?” We call these “path rollup” and “domain rollup”, respectively.
Challenge: Supporting URL “Scrubbing”
URLs often contain sensitive information, ranging from PII to document titles, to security nonces that are intended to be available only for a single client computer. In an attempt to limit the privacy impact of URL transmission/telemetry, software may attempt to “scrub” the URL, replacing private data with a replacement character (e.g. https://phone.com/425-830-6600/call is masked as https://phone.com/XXX-XXX-XXXX/call).
Because scrubbing logic is, at best, based on imprecise heuristics, it is subject to false negatives (sensitive values not masked) and false positives (PII-looking values that are e.g. actually just meaningless numbers formatted as if they were telephone numbers).
Any attempt at scrubbing creates a mechanism by which an attacker can easily interfere with URL matching logic. The attacker can “cloak” their endpoint such that it responds only with innocuous content when a “PII-looking” value is omitted from the request URL (e.g. by a server-side detonator that is using a scrubbed URL).
Any attempt at using scrubbed values in threat intel feeds creates problems if the components creating and consuming the feed do not recognize how sensitive data is masked within that data, potentially leading to URL matching ambiguities.
Challenge: Inconsistent Length Limitations
URLs do not have a consistent length limit. Chromium limits URLs to 2MB for navigation (and 32kb for display, in some contexts), while various components of Windows use 2083 characters, and some servers and security software have URL length limits that are longer and shorter.
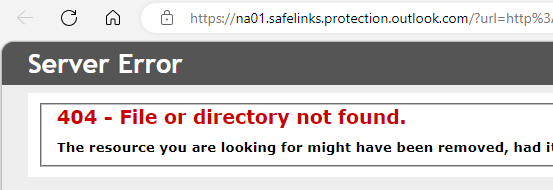
Some security software imposes a lower limit on URL length, returning error pages if the URL length exceeds their limit (e.g. 4096 characters):
Back in 2022, I brought home a new 2023 Nissan Leaf S and I’ve had a blast driving it since. In hindsight, it was one of my best purchases in a long time– it’s super fun to drive, and other than tires/alignment it has required zero maintenance (not even refilling the wiper fluid!) in the 45 months that I’ve driven it almost 38K miles. It’s a great car. Update: on 7/29/2026, the wiper fluid finally ran out at 38.8K miles 🤣
But…
The Leaf’s range is not awesome. While its efficiency is high (I average 4.2 miles per KW), that’s partly achieved with a small 40KW battery pack, and the extremely limited fast-charger support (I’ve fast-charged perhaps 4 times) means that it’s completely impractical for road trips.
It’s small. My 13yo now rides in the front seat, and my 10yo is pretty crammed in the back.
It lacks features. No remote start or charge monitoring, no built-in CarPlay, small internal screen. Black cloth interior.
As early as one year in after getting my Leaf, I was already thinking about upgrading to something bigger in a year or two. I was excited that the 2026 Leaf fixes many of the problems of my 2023 (bigger battery, nicer features, winning charger standard) but was disappointed to see that it’s got a backseat that seems even smaller than that of the 2023. I pondered waiting for a Tesla Model YL (the upcoming extended length version of the Y) but I’ve been souring on the Tesla because they’re everywhere nowadays and the look doesn’t appeal to me as it once did.
On June 27th, I bought an Equinox EV AWD in RipTide Blue with the cloud grey interior:
A week prior, I’d test-driven a Blazer EV and was disappointed that driving it felt … pokey. It was big and comfortable, yes, but driving it felt more like my CX-5 than my sporty Leaf, despite the 220HP electric motor. I’d initially been skeptical of going to the all wheel drive model because it costs more ($3300) and drops estimated range (from 319 to 307), but online reviewers raved that the additional 80HP gave the AWD the “electric car zip” that I was looking for.
So the following Saturday, as my kid warmed up at his out-of-town swim meet, I drove up from San Antonio to San Marcos (a lot further than I realized) to test drive the AWD LT2 trim. As soon as I sat down in its big comfy grey seat, I knew I wanted it. Ten-seconds off the lot in the test drive, I dropped the pedal and got that roller-coaster takeoff feel I was craving. The price was good (about $10K under sticker for the Riptide Blue one I wanted that had been used as a courtesy vehicle). Then it was just an annoying amount of paperwork before I got the keys and headed back to the swim meet.
I’ve only got some initial impressions, but here they are:
The cabin is really nice (quiet, high-riding, spacious)
The giant Google-powered infotainment display is really great (with a few annoyances: no CarPlay, many features locked out while driving)
360 degree cameras are awesome, especially in my cluttered garage and busy parking lots
Fast-charging at up to 150KW (I consistently got 125KW at EvGo and Buc-ee’s) makes it a practical road-trip car. Competitors can charge faster (deep dive) but 150KW is fine for how rarely I expect to fast charge.
Having three cars is a hassle. I’d been planning for the kids to get my hand-me-downs, but it’s going to take a few years. Update: I quickly found a good home for my CX-5.
The CCS charge port is much more broadly supported than the CHAdeMO, but they really ought to throw in a NACS converter (I bought one) for less than $200. The 2027 model is expected to switch to the native NACS port.
WeatherTech floor mats are a worthwhile upgrade.
Selling heated seats and steering wheels in Texas (in the summer!) has to be a hard proposition. They probably should sell a “LT2 Hot Weather” trim instead, with ventilated seats and shades.
Remote Start/ClimateControl is awesome, but the myChevrolet app is still annoyingly limited. For instance, you cannot remotely override the charge schedule to say “Charge fully now”:
In the nine days I’ve owned the Equinox EV, I’ve driven it to and from San Antonio twice and around town a bit, but I’ve been driving my Leaf more than I expected– it’s still fun, easy to park, and 33% more energy efficient than the Equinox.
So, why I bought, in order of reasons:
I need the range. I bought a house a bit further out from the city and I’ll be moving sometime in August.
The Equinox offers more room for my family.
I wanted it. :)
I’ll expect I’ll update this post over the next few months when I’ve got more informed things to say.
-Eric
My Car History:
1990 Pontiac Grand Am (thanks, Grandma!) -> Red Cross (2021)
2003 Corolla LE 130hp (thanks, Microsoft!) -> Coworker’s kid (2012)
Today marks my 25th anniversary of full-time work in tech.
June 18, 2001 – My third “New Employee Orientation” at Microsoft, starting my full-time employment after University. I worked on the Office Online PM team for three years before moving to the Internet Explorer Networking and Security teams for 8 more, eventually leading a team of PMs.
September 29, 2012 – I resigned from Microsoft to move to Austin and build Fiddler at Telerik.
January 4, 2016 – I started on the Chrome Security team at Google. Working at Google was an amazing experience and while I wasn’t supposed to be a software engineer, I managed to survive long enough to learn a ton.
June 4, 2018 – I rejoined Microsoft to work on the Edge Web Platform team. Using my newfound Chromium skills, I landed more changes into Chromium as an Edge PM at Microsoft than I had landed as a Chrome SWE at Google. lol. After four years on Edge, I moved to the Defender team, where I’ve been a PM, GPM, SWE, and Architect-in-All-But-Name.
Prior to full-time work, I spent:
two summers as an Electronics Test technician
a summer as a Delphi developer
a summer as an intern webdev at a Federal contractor
a spring as a webdev intern at The Motley Fool
two summers interning at Microsoft on the product that would become SharePoint
two semesters as a Student Consultant for Microsoft at the University of Maryland
I don’t have anything newly profound to share today, but much of what I’ve learned over this quarter-century is summarized in some of the many posts on Career I’ve posted over the last thirteen years. Back in 2015, I gave a talk about what I’d learned in my first fifteen years: you can find the recording and deck of Lucking In on GitHub.
In the past, I’ve explained how security products combine sensors and throttles with threat intelligence to protect users and devices from attack. I’ve also outlined how the evolution of software, including increased complexity and a focus on privacy, have made it harder than ever for sensors and throttles to function effectively, leading to security and reliability risk.
The Current Landscape
Today in the Windows ecosystem, we have a few cases of “participatory extensible security” (PES). PES is extensible on both sides:
An “enlightened” client can participate by asking for security help
Any security product can extend protection to any client
One PES example is the IOfficeAntivirus interface, which gets called on file downloads and document opens to tell installed antivirus software “I got a new file. Scan it for viruses?” (This direct call isn’t entirely redundant behavior in a world with Real-time Protection, but it’s close).
The more prominent example of PES is an API called AMSI — the Antimalware Scan Interface. I’ve blogged about AMSI before but the tl;dr is that it is an API contract where an (arbitrary) AMSI client can ask an (arbitrary) AMSI security provider “Hey, what do you think of this. Does it look malicious?”
This allows the client application (a script engine, a document editor, etc) the ability to choose the best place to put a sensor/throttle pair– for instance, Word can call AMSI right after a document is decrypted and immediately before its powerful script content is about to be executed. This is great for several reasons:
The client doesn’t need to know anything about the security provider.
The security provider doesn’t need to try to hook the (potentially new or unknown) client.
The security provider gets the content to be scanned in whatever form the client believes will best reveal signs of malice.
If the content is determined to be malicious, the client can show a meaningful error message and/or offer advice or remediations.
That’s great stuff!
Unfortunately, the flexibility and simplicity of this API contract has its downsides. In particular, the API was designed in the style of most Microsoft extensibility APIs of the late 1990s: a series of registry keys point to a set of DLLs that are loaded and then executed in process of the calling app. This istheoretically good for performance because it means that an AMSI scan does not require spawning new processes or marshalling data cross-process. Unfortunately, it’s very bad for reliability. If an AMSI provider crashes or otherwise corrupts the memory of the process into which it was loaded, the AMSI client crashes. Because it’s a native code crash, there’s usually no meaningful error message, so a buggy AMSI provider can cause crashes across multiple clients without the user realizing what’s happening or that there’s a common culprit. Even if AMSI providers are rock solid in terms of reliability, implementations can silently degrade performance — most AMSI clients and providers do not show UI or any other indication that a scan is in progress or what provider is conducting it. A user could install a new product that dramatically hinders the performance of every AMSI client and suffer poor experiences for years without understanding why: “This PC is sometimes just slow, I guess.” In addition to the possibility of a single slow implementation, AMSI permits multiple providers on a single device. The performance impact of a single provider might be acceptable, but three or more? A final issue is that Windows now supports certain types of processes called Protected Processes (or Protected Process Lite) that rely on Windows Code Integrity enforcement to allow only DLLs bearing certain digital signatures to load. If an AMSI provider isn’t signed with the required signature, the LoadLibrary call will fail, that AMSI provider will be skipped, and the user’s Event Log will record a code integrity violation.
Beyond the mechanics of how AMSI providers load and run, another issue is that the API contract for AMSI is probably a bit too generic:
HRESULT AmsiScanBuffer(
[in] HAMSICONTEXT amsiContext,
[in] PVOID buffer,
[in] ULONG length,
[in] LPCWSTR contentName,
[in, optional] HAMSISESSION amsiSession,
[out] AMSI_RESULT *result );
AMSI callers calling AmsiScanBuffer in new scenarios means that AMSI providers can abruptly start getting data of sorts they’ve never seen before. For example, a few years back SharePoint started calling AMSI on inbound HTTPS request headers and bodies. In the latest Windows Insider builds, the Run dialog will call AMSI on content pasted in from the Internet to combat ClickFix attacks. AMSI’s flexibility meant that existing security products didn’t need to be redeveloped with awareness of the new call sources and data, but it also introduces the risk that one of those products might misunderstand what it’s scanning and cause a false positive, performance issue, or even a crash. Even if the scan call succeeds, the value of the call depends upon the security product having meaningful threat intelligence against whatever sorts of threats might be found in the caller’s buffer. Scanning for malicious Win32 native code in a buffer containing a command line string isn’t going to be very useful, for example.
The Fix?
None of the problems here are insurmountable, we just need to invest and adjust the engineering tradeoffs to reflect more modern needs. Off the top of my head, I’m hoping we’ll see:
Telemetry for the AMSI providers to understand their real-world performance impact
UX for the user to understand how their security software impacts performance and reliability
An API contract that does not result in loading foreign code into every AMSI caller
A richer API contract that allows for more context on what’s being scanned
A richer API contract that allows for more result codes
I’m hopeful that one day we’ll be able to fold the legacy AMSI features into the upcoming Windows Endpoint Security Platform that is being built as a part of the Windows Resiliency Initiative.