Last update: October 29, 2024
Web browsers are conceptually pretty simple, but their code and the ecosystems that arise around the platforms they expose are immensely complicated.

I started building browser extensions more than 22 years ago, and I started building browsers directly just over 16 years ago. At this point, I think it’s fair to say that I’m entering the grizzled veteran phase of my career.
With the Edge team continuing to grow with bright young minds from college and industry, I’m increasingly often asked “Where do I learn about browsers?” and I haven’t had a ready answer for that question.
This post aims to answer it. (Prefer hearing me talk?)
First, a few prerequisites for developing expertise in browsers:
- Curiosity. While browsers are more complicated than ever, there are also better resources than ever to learn how they work. All major browsers are now based on open-source code, and if you’re curious, you no longer need to join a secret priesthood to discover how they operate under the hood.
- Willingness to Experiment. Considering how complex browsers are (and because they’re so diverse, across platforms, maker, and version), it’s often easiest to definitively answer questions about how browsers work by trying things, rather than reading an explainer (possibly outdated or a map that doesn’t match the terrain) or reading the code (often complex and potentially misleading). Build test cases and try them in each browser to see what happens. When you encounter surprising behavior, let your curiosity guide you into figuring it out. Browsers contain no magic, but plenty of butterfly effects.
- Doggedness. I’ve been doing this for over half of my life, and I’m still learning daily. While historical knowledge will serve you well, things are changing in this space every day, and keeping up is an endless challenge. And it’s often fun.
Now, how do you apply these prerequisites and grow to become a master of browsers? Read on.
Fundamental Understanding
Over the years, a variety of broad resources have been developed that will give you a good foundation in the fundamentals of how browsers work. Taking advantage of these will help you more effectively explore and learn on your own.
- First, I recommend reading the Chrome Comic Book. This short, 38 page comic book from comics legend Scott McCloud was published alongside the first version of Google Chrome back in 2008. It clearly and simply explains many of the core concepts behind modern browsers as application platforms.
- HTML5Rocks has a great introduction into How Browsers Work. This is a lengthy and detailed introduction into how browsers turn HTML and CSS into what you see on the screen. Read this article and you’ll understand more about this topic than 90% of web developers.
- The folks at Google have created a fantastic four-part illustrated series about how modern browsers work: Inside look at modern web browsers. Navigation, the Rendering Engine and Input and Compositing as a part of their Web Fundamentals site.
- Mozilla wrote a fantastic cartoon introduction to WebAssembly, explaining the basics behind this new technology; there’s tons of other invaluable content on Mozilla Hacks.
- The Chromium Chronicle is a monthly series geared specifically to the Chromium developers who build the browser.
- Web Developers should check out Web.Dev, a great source of articles on building fast and secure websites.
Books
If you prefer to learn from books, I can only recommend a few. Sadly, there are few on browsers themselves (largely because they tend to evolve too quickly), but there are good books on web technologies.
- High Performance Browser Networking can be read online for free.
- HTTP2 in Action explains this important new protocol.
- Bulletproof SSL and TLS provides an extremely detailed and accurate look at these intricate security protocols. (There’s also a great free newsletter.)
- The Tangled Web explains the web security model.
- Progressive Web Apps explores the technologies behind this new web application paradigm.
- Coming end-of-2024: Web Browser Engineering; one of the coauthors is the rendering lead from the Chrome team. Preorders open.
Tools
One of the best ways to examine what’s going on with browsers is to just use tools to watch what’s going on as you use your favorite websites.
Update: I’ve written a whole post on Browser-Debugging Tools.
Use the Source, Leia
The fact that all of the major browsers are built atop open-source projects is a wonderful thing. No longer do you need to be a reverse-engineering ninja with a low-level debugger to figure out how things are meant to work (although sometimes such approaches can still be super-valuable).
Source code locations:
- Firefox‘s code can be searched via Searchfox or DXR.
- WebKit source can be found here. I typically just search on a mirror on GitHub, and apparently Igalia’s Search Engine is even better.
- Chromium‘s code is found in the Code Search tool (future version).
- Microsoft Edge‘s code can be downloaded in giant (4gb) ZIP files from here. Sadly, online search is not yet available.
- Brave‘s changes to Chromium can be found on GitHub.
- The HTML5 Specification is often useful.
Navigating the Code
While simply perusing a browser’s source code might give you a good feel for the project, browsers tend to be enormous. Chromium is over 10 million lines of code, for example.
If you need to find something in particular, one often effective way to find it easily is to search for a string shown in the browser UI near the feature of interest. (Or, if you’re searching for a DOM function name or HTML attribute name, try searching for that.) We might call this method string chasing.

By way of example, today I encountered an unexpected behavior in the handling of the “Go to <url>” command on Chromium’s context menu:
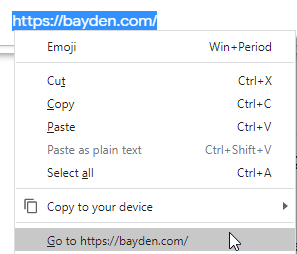
So, to find the code that implements this feature, I first try searching for that string:

…but there are a gazillion hits, which makes it hard to find what I need. So I instead search for a string that’s elsewhere in the context menu, and find only one hit in the Chromium “grd” (resources) file:
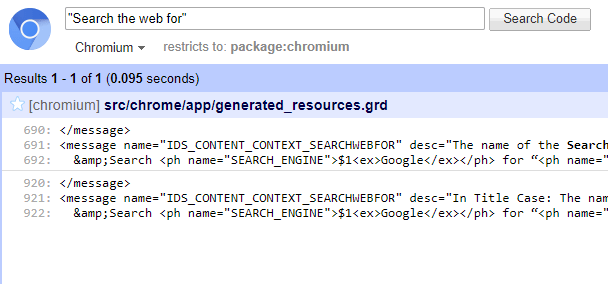
When I go look at that grd file, I quickly find the identifier I’m really looking for just below my search result:

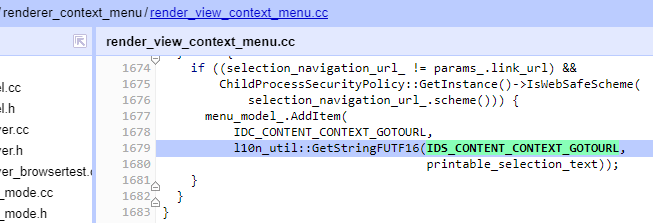
So, we now know that we’re looking for usages of IDS_CONTENT_CONTEXT_GOTOURL, probably in a .CC file, and we find that almost immediately:
(Note that, on Android, it’s a little more complicated. You drop the IDS_ prefix and change the rest to lowercase. Then search the source for e.g. R.string.content_context_gotourl).
From here, we see that the menu item has the command identifier IDC_CONTENT_CONTEXT_GOTOURL, which we can then continue to chase down through the source until we find the code that handles the command. That command makes use of a variable selection_navigation_url_, which is filled elsewhere by some pretty complicated logic.
After you gain experience in the Chromium code, you might learn “Oh, yeah, all of the context menu stuff is easy to find, it’s in the renderer_context_menu directory” and limit your searches to that area, but after four years of working on Chrome, I still usually start my searches broadly.
Optional: Compile the code
If you’d actually like to compile the code of a major browser, things are a bit more involved, but if you follow the configuration instructions to the letter— your first build will succeed. Back in 2015, Monica Dinculescu created an amazing illustrated guide for contributing to Chromium, and in 2020, Marcos Cáceres wrote a thorough explainer about building a feature in Firefox. In 2021, the WebKit team released a guide for contributing to WebKit.
You can compile Chromium or Firefox on a mid-range machine from 2016, but it will take quite a long time. A beefy PC will speed things up a bunch, but until we have cloud compilers available to the public, it’s always going to be pretty slow. Update October 2020: Note that there’s now a simple way to make simple changes to Chromium using just your web browser.
This guide on compiling WebKit suggests that a web platform-only build on a MacBook takes only about 20 minutes; you can run the resulting platform in a minibrowser or instruct Safari to use it.
Look at their Bugs
All browsers except Microsoft Edge have a public bug tracker where you can search for known issues and file new bugs if you encounter them.
- Firefox – Firefox Bugzilla
- WebKit – WebKit Bugzilla
- Chromium – CRBug
- Microsoft Edge‘s – Platform bugs that are inherited from Chromium are tracked using CRBug. Sadly, at present there is no public tracker for bugs that reproduce only in Edge. Bugs reported by the “Feedback” button are tracked internally by Microsoft.
- Brave – on GitHub
- Cross-browser compat issues – webcompat.com
- HTML5 Specification – on GitHub
Here are instructions for filing a great browser bug.
Binge on Online Video
The Chrome team has an excellent set of educational content used to train new and long-time Chrome engineers. Titled Chrome University, it is periodically updated. Here’s the Chrome Security 101 course, for instance.
Here’s a cool 51 minute talk on building a browser (“Ladybird”) from scratch.
Blogs to Read
- This One – I write mostly about browsers.
- My (archived) IEInternals – I started writing this blog because it was the only reliable way for me to find my notes from investigations and troubleshooting years later.
- Cloudflare’s – Cloudflare is a $20B+ company whose primary product is their amazing blog. I understand they also run a CDN on the side to generate interesting topics for their blog to talk about.
- April King‘s blog covers security and networking.
- Nasko Oskov’s – Nasko is an engineer on the Chrome Security team and writes mostly about security topics.
- Chris Palmer’s – Chris is an engineer on the Chrome Security team and writes about secure design.
- Adam Langley’s – Google’s expert cryptographer
- Bruce Dawson’s – Bruce is a Chrome Engineer who posts lots of interesting information about debugging and performance troubleshooting, especially on Windows.
- Anne van Kesteren’s – Anne works on the HTML5 spec.
- Mark Nottingham’s – Mark co-chairs the HTTP and QUIC working groups.
- Alex Russell’s – Alex is a deep thinker about the browser ecosystem and has written many very thoughtful posts about the competitive landscape for browsers.
- Emily Stark – Emily from Chrome Security is one of the smartest folks I know.
Specific Posts of Interest
- The Accessibility Tree and Screenreaders – Building accessible content matters. Understanding how AT tools work will help.
- Compatibility Strategery: Martian Headsets – A look at the difficult choices faced by the IE8 team.
- The Web We Want: Feedback from WebDevs to BrowserDevs – Introduces a new group designed to help browser developers better meet the needs of web developers.
- Today the Trident Era Ends – A look back at Internet Explorer’s innovations.
- The Chromium Glossary / Lexicon offers explanation of many important acronyms used in Chrome development.
- From security bug Bounty Hunter to the Edge Security Team.
People to Follow
- Lin Clark (@linclark) draws @codecartoons. These are my favorite thing in the universe.
- Similarly, @kosamari provides some of the clearest explanations of complicated browser topics.
- The @intenttoship bot publishes notices of browsers’ intention to launch new features
- Other Chrome folks often tweet interesting things: Mike West, Alex Russell (now on Edge), Paul Irish, Jake Archibald, Rick Byers, Pete LePage, Surma (now at Shopify), Jochen Eisinger, Jeffrey Yasskin, Yoav Weiss, Chris Wilson, Domenic Denicola, Paul Kinlan, Adrienne Porter Felt, Emily Schechter, Emily Stark, Parisa Tabriz, Nasko Oskov, Simeon, Ryan Sleevi (now at Apple and no longer on Twitter), Justin Schuh (now retired), Rowan Merewood, Peter Beverloo, Dominick Ng, Asanka Herath, Darin Fisher (now at Neeva), Andrew Whalley, Dion Almaer, Mathias Bynens, David Benjamin, Bruce Dawson, Addy Osmani, Ilya Grigorik (now at Shopify), Mathieu Perreault, Varun Khaneja, Chris Thompson, Ian Kilpatrick, Avi Drissman
- Assorted folks in the Web space: PPK, Michal Špaček, François Remy, Kenneth C, Melanie Richards, Tony Ross, Mark Nottingham, Alex Wykoff, Mike Taylor, Adam Langley, Nic Jansma, John Wilander, othermaciej, pes, Artur Janc, Ivan Fratric, Lucas Pardue, Anne van Kesteren, Stephanie Stimac, Aaron Gustafson, Allen Wirfs-Brock, J.C., Adam Roach, Zouhir, Kamila Hasanbega, Matt Holt, John Graham-Cumming, Jun Kokatsu, Patrick Kettner, Eiji Kitamura, Jonathan Kingston, Sampson, Brian Clifton, Brian Bondy, Owen Campbell-Moore, Natalie Silvanovich, Alex Ainslie, Mike Conley, Tanvi, Malte Ubl, Chris Heilmann, Monica Dinculescu, Eric Mill, Evan J, eae, Scott Helme, April King, Matthew Prince, Yan, Patrick Donahue, Justin, Jyrki Alakuijala, James Forshaw, Tim Kadlec, Kyle Pflug, Sam Sneddon, David Storey, Chris Love, Travis Leithead, Tammy Everts, Greg Whitworth, Sean Lyndersay, Colleen Williams, Daniel Stenberg, L. David Baron, TJ VanToll, John Jansen, Patrick McManus, Giorgio Maone, Ben Adida, Ivan Ristic, Patrick Meenan, Steve Souders, Jungkee Song, Dane Knecht, Scott Low, Dave Rupert, Mark Goodwin, Gareth Heyes, Manuel Caballero, James Kettle, Christian Schaefer, Sean Thomas Larkin, Rick Viscomi, Brendan Eich, Marcos Cáceres
- EdgeDevTools, ChromeDevTools, WebKit, WebCompat, Webhint
- Me :)
I’ve doubtless forgotten some, see who I follow.
The Business of Browsers
Public data reveals each point of marketshare in the browser market is worth at least $100,000,000 USD annually, most directly in the form of payments from the browser’s configured search engine. Apple reportedly gets $9-$12Billion per year for sending search traffic to Google, and Mozilla has yielded ~$400M per year from the same sort of deal.
Remembering this fact will help you understand many other things, from how browsers pay their large teams of expensive software engineers, to how they manage to give browsers away for free, to why certain features behave the way that they do.
Expert Alex Russell has some notes about money on his blog.
Extra Resources
- CanIUse.com often has useful information.
- ChromeStatus and particularly their “upcoming changes” schedule.
- Browser versions & schedules: Chrome’s OmahaProxy and ChromiumDash, and Firefox’s WhatTrainIsItNow.
- Chromium Design Docs – Some are badly outdated, but all of them are interesting.
- SSLLabs.com test sites’ and clients’ TLS cipher support
Browsers are hugely complicated beasts, and tons of fun. If the resources above leave you feeling both overwhelmed and excited, maybe you should become a browser builder.
Want to change the world? Come join the new Microsoft Edge team today!
-Eric

This is an awesome list of resources (I wasn’t surprised that many of the Twitter handles were ones I have been following for years).
As someone that wants to be able to dig in and know exactly what is happening for every page load I love things like the window.performance[.timing] API https://www.w3.org/TR/navigation-timing/#processing-model to inspect where time is being spent from the initial browser request for a page through the fully rendered response. Much of this I could determine through Fiddler and the browser dev tools network tab, but I’ve now opened up Pandora’s box with a tool I wrote sitting on top of the window.performance API. I’m getting great data to find and fix the “hot spots” for slowness but I also noticed there are chunks of “stall time” that vary and I’m wondering if (A) browsers intend to provide more granularity into this timeline and/or (B) if there are details about what happens in these gaps.
e.g. between the TCP “connectEnd” and the Request “requestStart”… this seems to vary on sites I inspect from 0ms to well over 500ms. Ditto for any delays between DNS “domainLookupEnd” and TCP “connectStart”.
I’d love to *demystify* what happens in these spots (*and more importantly*) is there anything I can do to reduce these gaps?
PS I understand that the performance.timing is technically deprecated: https://developer.mozilla.org/en-US/docs/Web/API/Performance/timing I’m hoping to be able to use other options to get fine-grained info wherever possible… the performance.timing object just happens to neatly wrap up all of these properties for me. ;-)
Checklist for contributing to Chromium https://chromium.googlesource.com/chromium/src/+/refs/heads/main/docs/commit_checklist.md