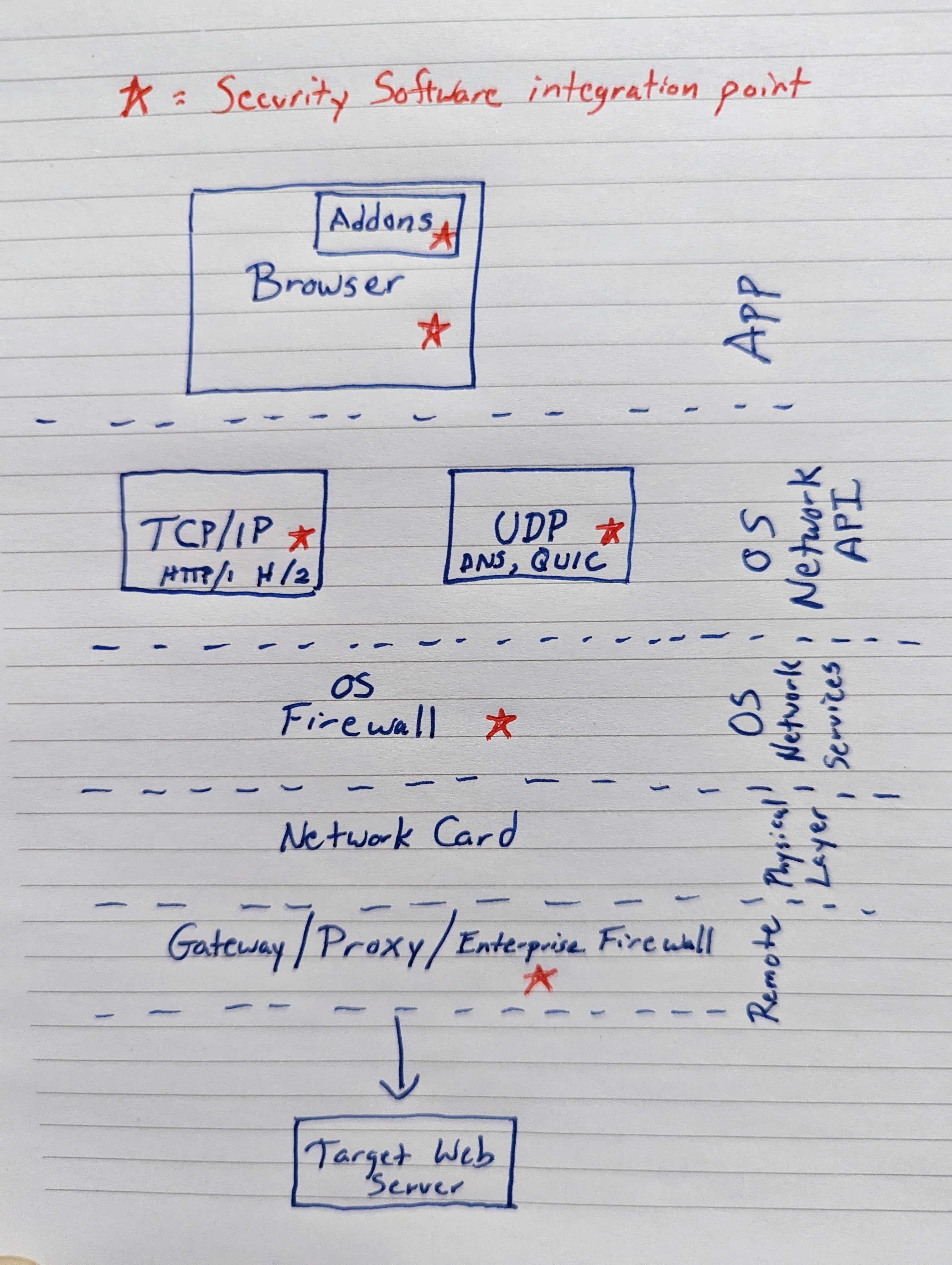
Folks often like to think of URLs as an entity that can be evaluated: “Is it harmless, or is it malicious?” In particular, vendors of security products tend to lump URLs in with other IoCs (indicators of compromise) like the hash of a known-malicious file, a malicious/compromised digital certificate, or a known-malicious IP address.
Unfortunately, these classes of IoCs are very different in nature. A file’s hash never changes– you can hash a file every second from now until eternity, and every single time you’ll get the same value. A file’s content cannot change without its hash changing, and as a consequence, a “harmless” file can never1 become “malicious” and vice-versa. Note that when we talk about a file here, we’re talking about a specific series of bytes in a particular order, stored anywhere. We’re not talking about a file path, like C:\users\eric\desktop\file.txt which could contain any arbitrary data.
In contrast to a file hash, a network address like an IP or a URL can trivially change from “harmless” to “dangerous” and vice-versa. That’s because, as we saw when we explored the problems with IP reputation, an IP is just a pointer, and a URL is just a pointer-to-a-pointer. The hostname component of a URL is looked up in DNS, and that results in an IP address to which the client makes a network connection. The DNS lookup can return[1] a different IP address every time, and the target server can switch from down-the-block to around-the-world in a millisecond. But that’s just the first pointer. After the client connects to the target server, that server gets to decide how to interpret the client’s request and may choose to return[2] different content every time:

Because the entities pointed at by a pointer can change, a given URL might change from harmless to malicious over time (e.g. a bad guy acquires a domain after its registration expires). But even more surprisingly, a URL can be both harmless and malicious at the same time dependent upon who’s requesting it (e.g. an attacker can “cloak” their attack to return malicious content to targeted victims while serving harmless content to others).
(Aside: A server can even serve a constant response that behaves differently when loaded on each client).
Implications & Attacks
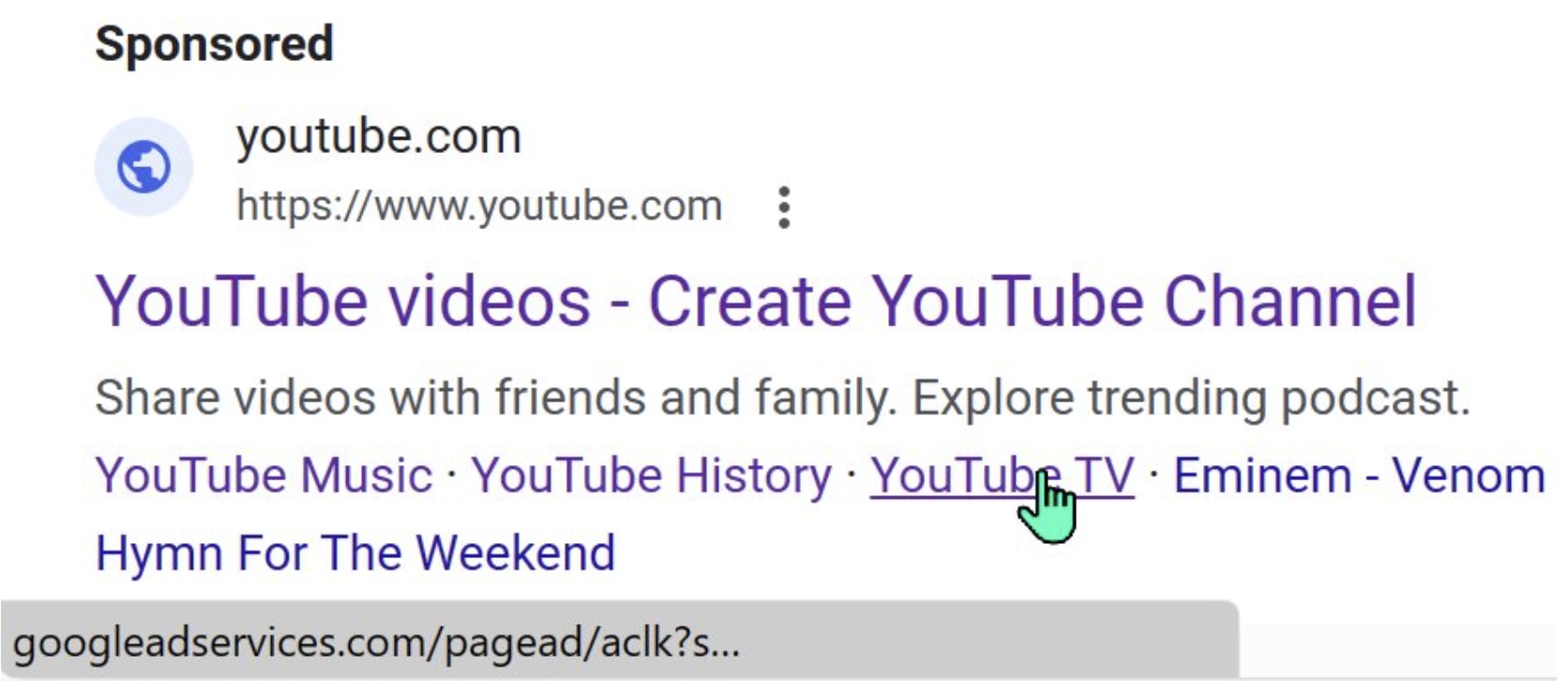
Recently, searching for youtube on Google would result in the first link on the page being a “sponsored” link that looked like this:

If a unsuspecting user clicked on the link, they were taken to a tech scam site that would try to take over the screen and convince the user that they needed to telephone the attacker:

How on earth was this possible? Were the attackers using some sort of fancy Unicode spoofing to make it look like a YouTube link to a human but not to Google’s security checks? Was there a bug on YouTube’s website?
No, nothing so fancy. Attackers simply took advantage of the fact that URLs are pointers to mutable entities.
What almost certainly happened here is that the attacker placed an ad order and pointed it at a redirector that redirected to some page on YouTube. Google’s ad-vetting system checked the URL’s destination to ensure that it really pointed at YouTube, then began serving the ad. The attacker then updated the redirector to point at their scam site, a classic “time-of-check, time-of-use” vulnerability2.

Because of how the web platform’s security model works, Google’s ability to detect this sort of chicanery is limited– after the user’s browser leaves the googleadservices.com server, Google’s ad engine does not know where the user will end up, and cannot3 know that the next redirector is now sending the user to an attack site.
Now, unfortunately, things are actually a bit worse than I’ve let on so far.
If you’re a “security sensitive” user, you might look at the browser’s status bubble to see where a link goes before you click on it. In this case, the browser claims that the link is pointed at tv.youtube.com:

Our exploration of this attack started at the URL, but there’s actually another level of indirection before that: a link (<a> element) is itself a pointer-to-a-pointer-to-a-pointer. Through JavaScript manipulation, the URL to which a link in a page points can change[0] in the middle of you clicking on it!

And that’s in fact what happens here: Google’s Search results page puts a “placeholder” URL into the <A> until the user clicks on it, at which point the URL changes to the “real” URL:
Now, malicious sites have always been able to spoof the status bubble, but browser vendors expected that “well-behaved sites” wouldn’t do that.

Unfortunately, that expectation turns out to be incorrect.
In this case, showing the “real” URL in the status bubble probably wouldn’t add any protection for our hypothetical “security-conscious” user — all of the links on the Google results page go through some sort of redirector. For example, the legitimate (non-sponsored) search result for YouTube shows www.youtube.com:
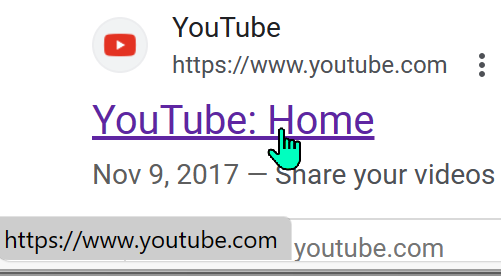
…but when clicked, it changes to an inscrutable redirector URL:

… so our theoretical user has no ready way to understand where they’ll end up when clicking on it anyway.
– Eric
1 All absolute statements are incorrect 😂. While a file’s content can’t change, files are typically processed by other code, and that code can change, meaning that a given file can go from harmless to dangerous or vice-versa.
2 It’s entirely possible that Google periodically revalidates the target destination of advertisements, and rather than doing a one-time-switcheroo, the attacker instead cloaked their redirector such that Google graders ended up on YouTube while victims ended up at the tech-scam. There’s some discussion of a similar vector (“tracking templates”).
3 If a user is using Chrome, Google at large could conceivably figure out that the ad was malicious, especially if the redirector ends up landing on a malicious page known by Google Safe Browsing. The SafeBrowsing code integrated into Chrome can “look back” at the redirect chain to determine how a user was lured to a site.