When moving from other development platforms to the web, developers often have a hard time understanding why the web platform seems so … clunky. In part, that’s because the platform is pretty old at this point (>25 years as an app platform), partly because changes in form factors and paradigms (particular mobile) have introduced new constraints, and partly because the Web is just lousy with bad actors hoping to do bad things.
One “simple thing” desktop developers expect to be able to do is to prompt the user to take some action before leaving an application (e.g. “Save your work?”). For years, browsers offered a simple mechanism for doing so: closing the browser, navigating to a different page, or hitting Refresh button would trigger an OnBeforeUnload() event handler. If the developer’s implementation of that function returned a string, that string would be shown to the user:
Unfortunately, tech scam sites would often abuse this and use it as yet another opportunity to threaten the user, so browsers decided that the most expedient solution was to simply remove the site’s control over the prompt string and show a generic “Changes might not be saved” string, hoping that this reflected the webapp’s true concern:
For the dialog to even display, there must have been an earlier user-gesture on the page; if there was no gesture, the dialog is suppressed entirely.
For some applications, this prompt works just fine, but for complicated workflow applications, the user’s issue might have nothing to do with “saving” anything at all. A user who wants to satisfy the app’s concern must click “Stay on page” and then scroll around to try to figure out where the problem is.
You might hope that you could just update your page’s DOM to show a alert message beside the built in prompt (“Hey, before you go, can you go verify that the setting <X> is what you wanted”, but alas, that doesn’t work — DOM updates are suppressed until after the dialog is dismissed.
Browsers won’t even emit the site’s string into the DevTools console so that an advanced user could figure out what a site was complaining about without manually stepping through the code in a debugger.
Web Platform evangelists tend to reply with workarounds, trying to guide developers to thinking in a more “webby” way (“Oh, just store all the data in indexedDb and restore the state the next time the user visits“), and while well-intentioned, this advice is often hard to follow for one reason or another. So users suffer.
I’m sad about this state of affairs — I don’t like giving bad guys power over anyone. This truly feels like a case where the web platform threw the baby out with the bathwater, expediently deciding that “We cannot have nice things. No one may speak, because bad people might lie.” The platform could’ve chosen to have a more nuanced policy, e.g. allowing applications to show a string if there was some indication of user trust (e.g. site engagement, installed PWA, etc).
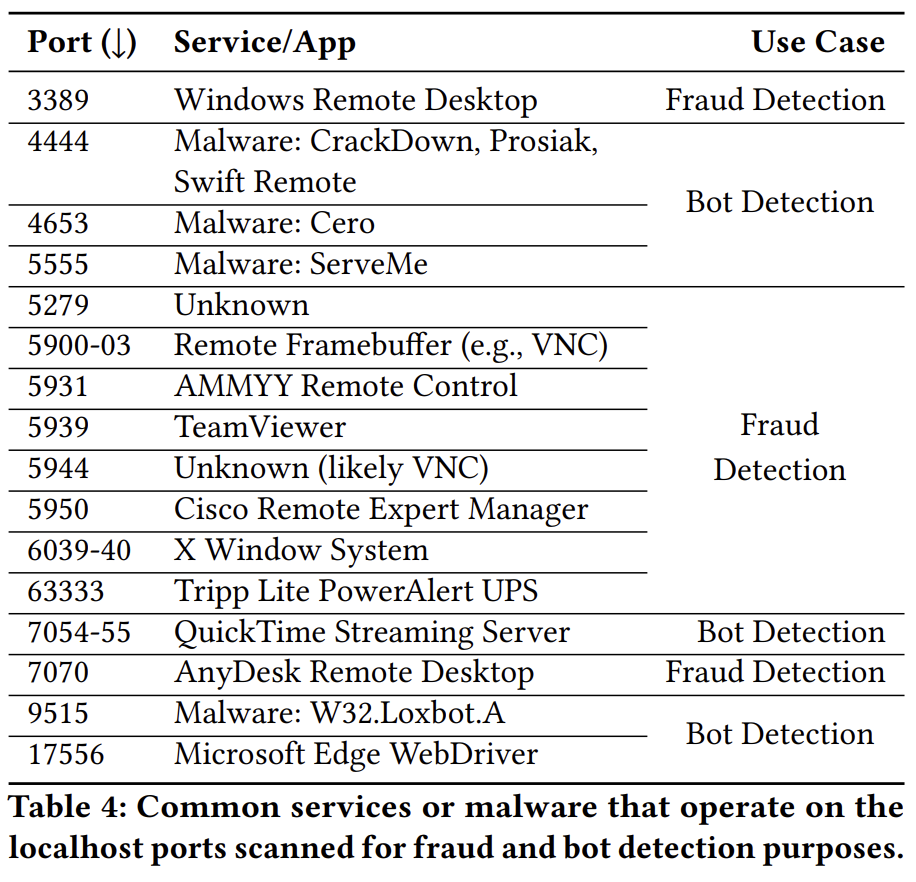
If you closely watch the Network tab in the Chromium Developer Tools when you try to log into Fidelity Investments, you might notice something that looks a bit weird. JavaScript on the page attempts to create WebSocket connections to a bunch of local ports on the IPv4 localhost address (127.0.0.1):
So, what are those ports used for? If you look at the website’s source code, you’ll see a clue; each port number in the code is preceded by a short tag of the protocol expected to be listening on that port:
But why does the website attempt these loopback connections?
The Web Platform does not expose “raw sockets” that would allow the JavaScript to speak any of the protocols in question, and the WebSocket handshake is explicitly designed to prevent using a WebSocket to talk to anything that doesn’t realize it’s speaking to a WebSocket. Furthermore, Chromium has an explicit port block list for well-known ports that are used for protocols that might conceivably be confused by receiving HTTP/HTTPS/WebSocket traffic, and none of these ports are on that list anyway.
So, if the JavaScript cannot hope to communicate using any of the target ports’ expected protocols, why does it even try?
+ 36 were for fraud detection, + 10 were for bot detection, + 12 were communicating with native apps, + 44 were likely due to developer error
Knock and Talk: Section 4.3
For the Fidelity case, it seems obvious that they’re probing these ports for fraud detection purposes.
The “Native Apps” case is one I’ve mentioned previously in my Web-to-App Communication Techniques post; the tl;dr is that the Web Platform only exposes a few mechanisms to allow a website to talk to a native application running on the user’s computer, and messaging a localhost server is one of them.
Amusingly, the authors found that, while there’s significant concern about allowing websites this power, then they investigated malicious sites using this technique, those sites were doing so because they were phishing sites that had bulk copied the code from legitimate bank login pages. 🤣
The authors (incorrectly) posit that the probing scripts could detect information about any server running on the target port, but thanks to how WebSocket handshakes work, that’s not possible. Instead, the best the script could do is perform a timing/error analysis to determine whether there’s any service listening on the port [Demo/Article].
Still, it does seem a bit worrisome that web apps can do this sort of probing, and from “inside” the user’s firewall. Because the browser is on localhost, and it’s talking to localhost, most firewalls will ignore the connection attempt and allow it through. If nothing else, this seems like a potential fingerprinting vector, and browser vendors have been working hard to eradicate those.
However, there aren’t necessarily any great options: if we simply blocked access to localhost, any of the scenarios that rely on Web-to-App communication will break. Elsewhere in the Web Platform, there are old and new attempts to isolate the local machine and local network from Internet-sourced web pages. The new proposals rely on CORS preflights, which might be harder to adopt for WebSocket servers, and which might be subject to the same timing analysis already being abused here.
For now, I wouldn’t worry too much about this — it certainly might be scary to see port scans happening from your browser process in your EDR logs, but it should be comforting to know that the browser isn’t actually able to communicate over those ports.
It’s extremely difficult to prevent attacks when there are no trustworthy pixels on the screen, especially if a user doesn’t realize that none of what they’re seeing should be trusted. Unfortunately for the browsing public, the HTML5 Fullscreen API can deliver this power to an attacker.
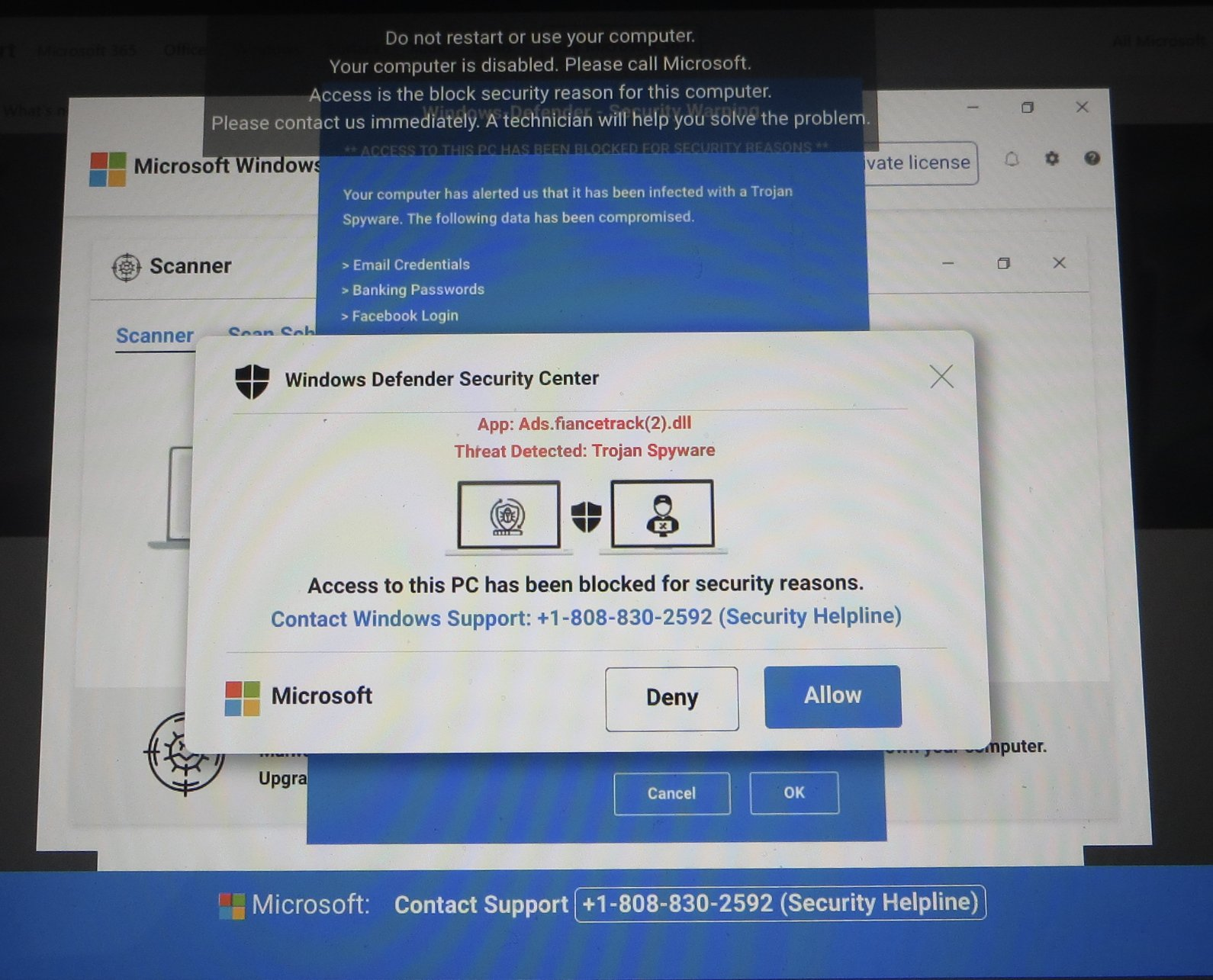
Today (and for over a decade now), an attacking website can enter full-screen after any user-gesture, which may be as simple as the user clicking anywhere in the page, or tapping any key. A common threat pattern is to abuse the browser’s APIs to perform a tech scam attack, in which a user is convinced to call a phone number staffed by the attacker.
On initial load, the attack page doesn’t have permission to go full-screen so the address bar and tabs remain visible…
As soon as the user hits any key, the attacker now has the “gesture” they need to abuse browser APIs and go full screen.
As in other hybrid web/phone attacks, after the victim phones the supplied number, the attacker then either directly asks the victim for money to “fix” the PC, or entices the victim to run “remote control” software to grant the attacker control of the PC to steal credentials or install malware. (Aside: The 2024 action thriller The Beekeeper explores what happens if the bad guys accidentally target the friend of a government assassin.)
Attack pages show text in a black box near the top-center of the window to try to confuse the user so they don’t see the browser’s hint that the browser is now in full-screen mode and hitting the Escape key will exit. They make the attack even harder to escape using the Pointer Lock API (which hides the mouse pointer) and the Keyboard Lock API (so exiting fullscreen requires that the user hold the Escape key). They increase the urgency with animation and even a computerized voice claiming that the user’s machine is under attack and they should call immediately to avoid damage. Some attacks will use tricks to cause the browser to become sluggish (e.g. by spamming the IPC channel between the renderer and the browser process) to make it harder for the user to escape the attack page.
If a user even manages to get out of full-screen mode, any keystroke or click re-enters the fullscreen mode. Attempting to close the tab with the [x] button will result in the OnBeforeUnload dialog box, where the user must see and press the Leave button in order to close the page:
Making matters even scarier, the attack site may deliver JavaScript which, while (harmlessly) loaded into the browser cache, causes the system’s real security software to pop up a toast indicating that an attack is underway.
What’s a normal human to do in the face of this attack?
One response might be to turn off the power to the computer in the hopes that it will just go away. That might work, at the expense of losing anything that hadn’t been saved, but it might not, if the user accidentally just “sleeps” the device or if the browser’s crash recovery brings the attack site back after the computer reboots.
I recently noticed that the MalwareBytes extension attempts to detect “browser locker” scam sites like these by watching the exercise of certain web-platform APIs. While blocking APIs entirely could have site-compat impact, it might be a reasonable thing to do for many sites on the too-often hostile web.
Punditry
In my opinion, browsers are much too eager to enter and reenter fullscreen – if a user exits full-screen manually, I think we shouldn’t allow the site to regain it without a more explicit user-interaction (e.g. a permission bubble). And browser vendors probably ought to be smarter by paying attention, for example, automatically denying full-screen on sites where the user isn’t a regular visitor.
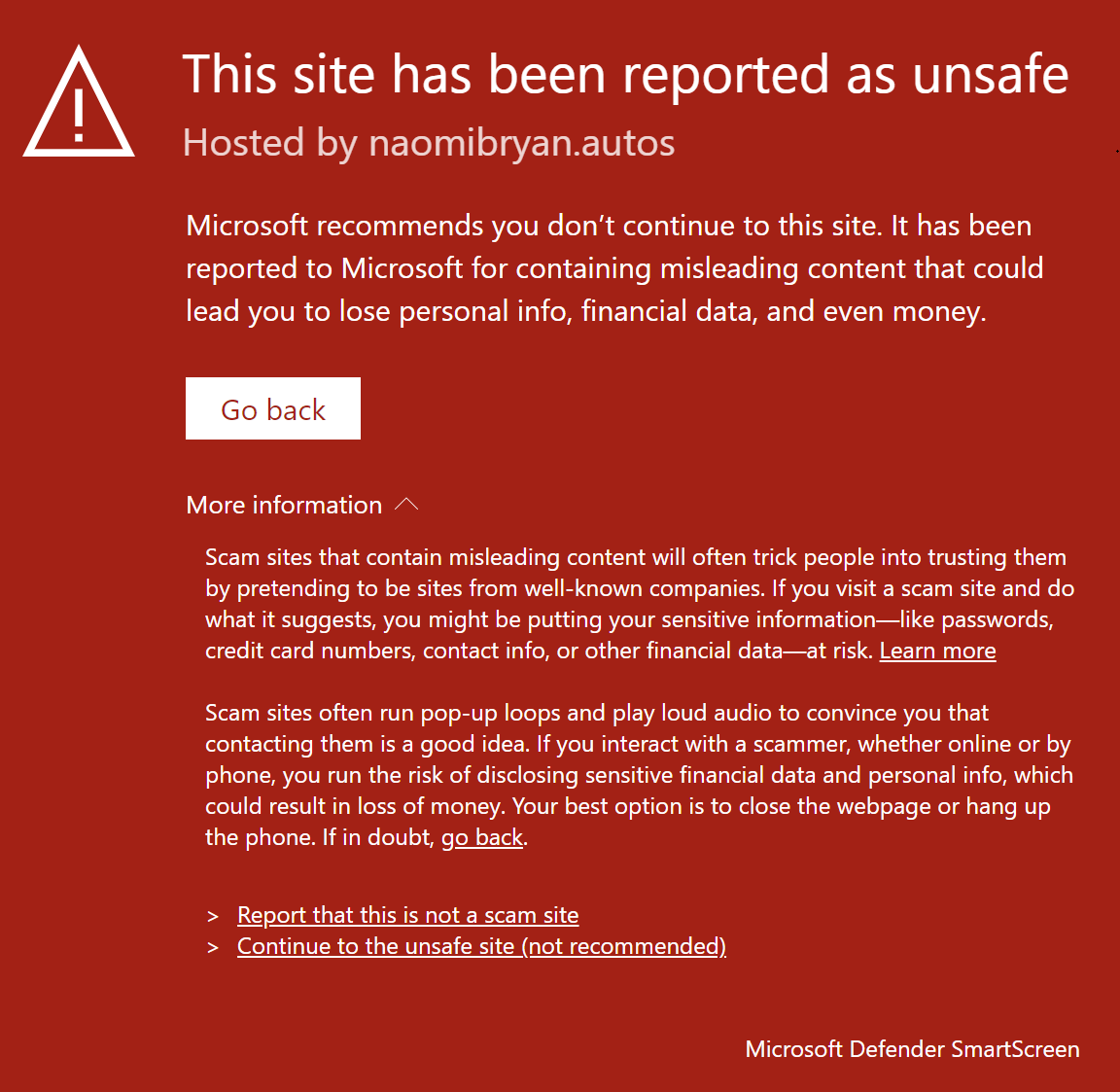
URL Reputation services like Google Safe Browsing and Microsoft SmartScreen do allow blocking of known tech scam sites, but there are just so so many of them (millions every month).
Update: An End-user Mitigation Appears
Updated: 8/12/2024
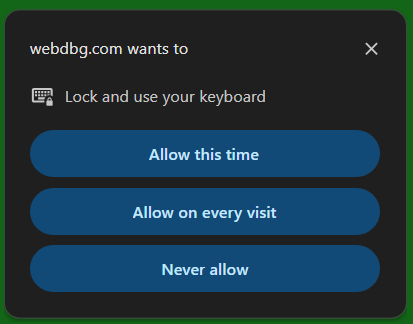
Current versions of Chrome have introduced a setting on chrome://flags that helps blunt the risk of the Keyboard Lock API. If you enable this setting:
…and restart your browser, future attempts to invoke the keyboard lock will explicitly prompt before locking the keyboard:
Microsoft Edge Canary (v129.0.2772.0) includes this setting. Firefox does not (yet?) support the keyboard lock API.
Unfortunately, there’s no option for such a prompt before any random site enters full-screen mode.
Edge’s Scareware Blocker
Updated: 11/21/2025
Edge has introduced a clientside detection for scareware sites. If a scareware attack is detected, the attack is interrupted and the user is presented with an explanatory block page. From that block page, they can report the malicious site to SmartScreen for blocking. Want to know more? Check out a demo video.
-Eric
PS: It’s tempting to think: Can’t the authorities just go after the bad guys on the other end of the phone? That might work, but it’s not a slam dunk.
Some attackers have built their scams in a loosely-coupled way, with plausible deniability at the point where the scam enters “the real world”. They outsource the job of taking money to a company unrelated to the site that scared the user into making the call in the first place. Add to that attackers’ ability to pivot between overseas call centers within hours, and you’ve basically gotten back to the “anti-spam” problem – good guys can take down, at best, a tiny fraction of a percent of the attackers.
When protecting clients and servers against network-based threats, it’s tempting to consider the peer’s network address when deciding whether that peer is trustworthy.
Unfortunately, while IP addresses can be a valuable signal, attempts to treat traffic as trustworthy or untrustworthy based on IP address alone can be very prone to mistakes.
Background
Most clients and servers today have one of fewer than 4.3 billion IPv4 addresses, often expressed as a set of four numbers delimited by dots. For example, 20.231.239.246 is an IP address used to serve the Microsoft.com homepage. IPv6, which offers 340 trillion trillion trillion unique addresses, is used relatively less commonly because not every internet service provider supports IPv6. For example, my provider, AT&T Fiber, presently does not.
DNS
Rather than directly supplying an IP address, most apps usually work by looking up a given hostname (say, microsoft.com) in the Domain Name System (DNS). In response to a query for a hostname, the DNS server returns one or more IPv4 or IPv6 addresses, and the client selects one to connect to. (If the connection fails, a client may try more addresses in the list.)
Different DNS servers may return different addresses for a given hostname. For example, a DNS server in France asked to look up microsoft.com is likely to return the address of Microsoft’s server in Europe, rather than the IP of its server in the United States. That helps ensure that French users don’t have to send their traffic across the Atlantic when a closer server is available. Similarly, DNS might return different addresses as a part of load-balancing or as servers are taken offline to perform maintenance tasks.
IP Geolocation
Various services purport to offer geolocation information for a given IP address based on where they believe this IP is hosted, but such services are imperfect. (Aside: I once remember a case at a Microsoft conference in Vegas where my IP geolocation was marked as New York. I was confused but eventually I realized that the traveling conference’s last stop was in New York, and whatever database was mapping IPs to locations simply had cached outdated information.)
Still, that’s not to say that geolocation isn’t without value as a signal. For example, last month, my parents encountered a scam site purporting to sell shoes. The scam site was a visually-perfect copy of a real site, but hosted by the scammers who collected credit card numbers and ran up hundreds of dollars in bogus charges. While the site’s domain name ended in us.com, suggesting an American company, the site’s IP address reveals that it was hosted out of Beijing. When I went back a few days later, the IP had changed to one somewhere in the Middle East.
Problems With IP Reputation
While IP addresses seem like a useful signal for whether a peer is trustworthy, there are unfortunately some major problems.
IPs Are Not Constants
A key problem with using IP addresses for reputation is that they can change. That’s true for both servers (as described above) and clients. For example, my ISP may assign my home router a particular IP this morning, but a different one tonight.
Similarly, thanks to DNS, a server needn’t have just one IP address — a given DNS query might return several different IPs, and a different DNS server might return an unrelated set. The hostname to IP mapping might even change very rapidly (“fast flux“). As long as all of the IPs are handled by the same server (either physically or logically), they go to the same “place” even if the IPs themselves have no components in common.
IPs May Be Unavailable
For web content in particular, the client may not know the IP address of the target server. While, as noted above, browsers usually perform DNS resolutions themselves, proxy servers are a common feature in enterprise environments. When communicating to a proxy server, the browser (unless using the SOCKS protocol) doesn’t look up the web server’s address at all. Instead, the proxy server does the DNS resolution on the client’s behalf, and the client never even sees the server’s IP address. A similar issue can occur if the client uses a VPN to connect to Internet sites.
In extreme cases, the client PC might not even have working Internet DNS at all, relying on a proxy or VPN for all of its Internet-access needs.
Shared Server Addresses: Virtual Hosting
Another key problem with using IP addresses for server reputation is that a single IP address might be used by many unrelated entities, particularly when the IP address resolves to a web server.
When a modern browser navigates to a HTTPS server, its initial message to establish the TLS connection (the ClientHello) contains a field called the Server Name Indication, that specifies the certificate that the client expects to receive. The server (often a frontend owned by a Content Delivery Network that has hundreds or thousands of unrelated customers) then knows which of the many HTTPS sites the client expects and it returns the content from that site. Because a single IP may serve content from many different parties, blocking that IP because it serves some malicious content could result in blocking lots of legitimate content.
Back in 2021, the blogging giants over at Cloudflare posted an amazing article on their experiments with serving Canadian visitors over 20 million sites from one IP address. Their shocking conclusion was that it worked, and doing so even had a number of benefits.
Cloudflare’s learning
Shared Client Addresses: NAT
A parallel problem exists for evaluating the reputation of clients. There are many scenarios where a server will see traffic from a large number of different entities originating from a single IP address. This can occur with, for instance, enterprise proxy servers, consumer VPN egress points, carrier-grade NAT, or even a bunch of users behind a single wifi router at a school or business (NAT/”Network Address Translation”).
A service that applies rate limits or anti-abuse mechanisms against a client’s IP address has to be careful to avoid breaking hundreds or thousands of clients using that same IP address. Once again, Cloudflare has a great blog post here, which explains the multi-user IP address problem and a service they offer to try to mitigate it.
Advantages of URL or Hostname Reputation
In contrast to IP-based reputation, URL or URL-Hostname based reputation has some advantages.
Blocking URLs and URL-hostnames is not subject to the vagaries of DNS– you can block evil.com without worrying about what specific IP address it’s being served from, and you don’t have to worry that you might’ve missed an address, or that it may resolve to a different IP if you use a different DNS server.
In the case of a server configured for virtual hosting, having reputation for a particular hostname allows you to block only traffic bound for that specific hostname and not all of the other hosts on that server.
In the case of a server that allows many unrelated parties to publish content (e.g. drive.google.com) URL reputation allows blocking only specific resources (e.g. drive.google.com/user/evil/* is blocked while drive.google.com/user/good/* is allowed).
Some security benefits are less obvious.
Securing a site with a HTTPS certificate now requires that the certificate’s existence be publicly logged via Certificate Transparency, allowing for the possibility of detection of abusive sites (e.g. www.paypal.com.gibberish.example.com) by a log monitor, even before the scam site is put online.
So We Should Always Use URL Reputation, Right?
While URL and URL-Hostname reputation are preferable to IP reputation when it comes to evaluating the trustworthiness of an Internet server, unfortunately, we cannot always rely upon them.
One scenario involves malware that talks to a “Command and Control” (C2) server. Such software may connect to an IP directly rather than using an address supplied by DNS, meaning that there’s no hostname to block. However, C2 IP addresses are kinda sitting ducks for security software, so attackers have started using other approaches to get their attacks to blend in with legitimate scenarios.
In other cases, blocking may be provided by a component that does not have access to the URL. For example, prior to the ubiquitous deployment of HTTPS, security software on the local PC or at the network gateway could easily see all of the URLs streaming by. TLS encryption prevents software on the network from seeing the HTTPS URLs being loaded, however, meaning that an observer only has access to the target IP address and maybe the hostname. Today, the hostname can be detected for most TLS connections by sniffing the TLS ClientHello message sent by the client to pluck out the Server Name Indicator (SNI) field that contains the hostname the client is trying to talk to. In the future, Encrypted Client Hello aims to combat this shortcoming of HTTPS by hiding the target hostname. An enterprise who wishes to perform hostname blocking will need to disable the ECH feature in their browser (e.g. Chrome, Edge).
For example, Windows Defender’s Network Protection (NP) feature operates on the Windows Filtering Platform layer (below the Windows Firewall). As a consequence, it only has access to the IP address, and to the hostname if present in the SNI. This allows NP to block access to sites if the entire site is deemed malicious (evil.com) but unlike Edge’s SmartScreen, sites with only some malicious content (drive.google.com/user/evil) must be allowed through to avoid false positives.
Unfortunately, TLS causes a bunch of user-experience problems for the blocking unwanted content.
When Network Protection determines that it must block a HTTPS site, it cannot return an error page to the browser because TLS prevents the injection of content on the secure channel. So, NP injects a “Handshake Failure” TLS Fatal Alert into the bytestream to the client and drops the connection. The client browser, unaware that the fatal alert was injected by Network Protection, concludes that the server does not properly support TLS, so it shows an error page complaining of the same.
If the system’s Notifications feature is enabled, a notification toast appears with the hope that you’ll see it and understand what’s happened.
Chromium-based browsers show ERR_SSL_VERSION_OR_CIPHER_MISMATCH when the TLS handshake is interruptedMozilla Firefox shows SSL_ERROR_NO_CYPHER_OVERLAP when the TLS handshake is interrupted
I continue to explore some of the challenges in implementing network address-based protections in this follow-up post on Security/Privacy Tradeoffs.
Earlier this year, I mentioned that I load every phishing URL I’m sent to see what it does and whether it tries to use any interesting new techniques.
While Edge’s “Enhanced Security Mode” reduces the risks of 0-day attacks against the browser itself, another great defense available for enterprise users is Microsoft Defender Application Guard. AppGuard allows you to run a protected Edge instance inside a virtual machine container that aims to prevent any damage to your system, even if the browser is compromised by an exploit.
You can get a new AppGuard window easily, using the “New Application Guard Window” command on Edge’s … menu:
…or you can launch a specific URL directly in AppGuard using the command line argument --ms-application-guard=https://example.com
I’ve configured SlickRun with a MagicWord that launches a site in AppGuard like so:
When handling toxic sites, use as much protection as you can!