On all popular computing systems, all files, at their most basic, are a series of bits (0 or 1), organized into a stream of bytes, each of which uses 8 bits to encode any of 256 possible values. Regardless of the type of the file, you can use a hex editor to view (or modify) those underlying bytes:

But, while you certainly could view every file by examining its bytes, that’s not really how humans interact with most files: we want to view images as pictures, listen to MP3s as audio, etc.
When deciding how to handle a file, users and software often need to determine specifically what type the file is. For example, is it a Microsoft Word Document, a PDF, a compressed ZIP archive containing other files, a plaintext file, a WebP image, etc. A file’s type usually determines what handler software will be launched if the user tries to “open or run” the file. Some file types are based on standards (e.g. JPEG or PDF), while others are proprietary to a single software product (e.g. Fiddler SAZ). Some file types are handled directly by the system (e.g. Screensaver files on Windows) while other types require that the user install handler software downloaded from the web or an app store.
Some file types are considered dangerous because opening or running files of that type could result in corrupting other files, infecting a device with malicious code, stealing a victim’s personal information, or causing unwanted transactions to be made using a victim’s identity or assets (e.g. money transfer). Software, like browsers or the operating system’s “shell” (Explorer on Windows, Finder on MacOS), may show warnings or otherwise behave more cautiously when a user interacts with a file type believed to be dangerous.
As a consequence, correctly determining a file’s type has security impact, because if the user or one part of the system believes a given file is benign, but the file is actually dangerous, calamity could ensue.
So, given this context, how can a file’s type be determined?
Type-Sniffing
One approach to determining a file’s type is to have code that opens the file and reads (“sniffs”) some of its bytes in an attempt to identify its internal structure. For some file formats, a magic bytes signature (typically at the very start of the file) conveys the type of the content. As seen above, for example, a Windows Executable starts with the characters MZ, while a PDF document begins with %PDF:

… and a PNG image file starts with the byte sequence 89 50 4E 47 0D 0A 1A 0A:

The Problems with Type-Sniffing
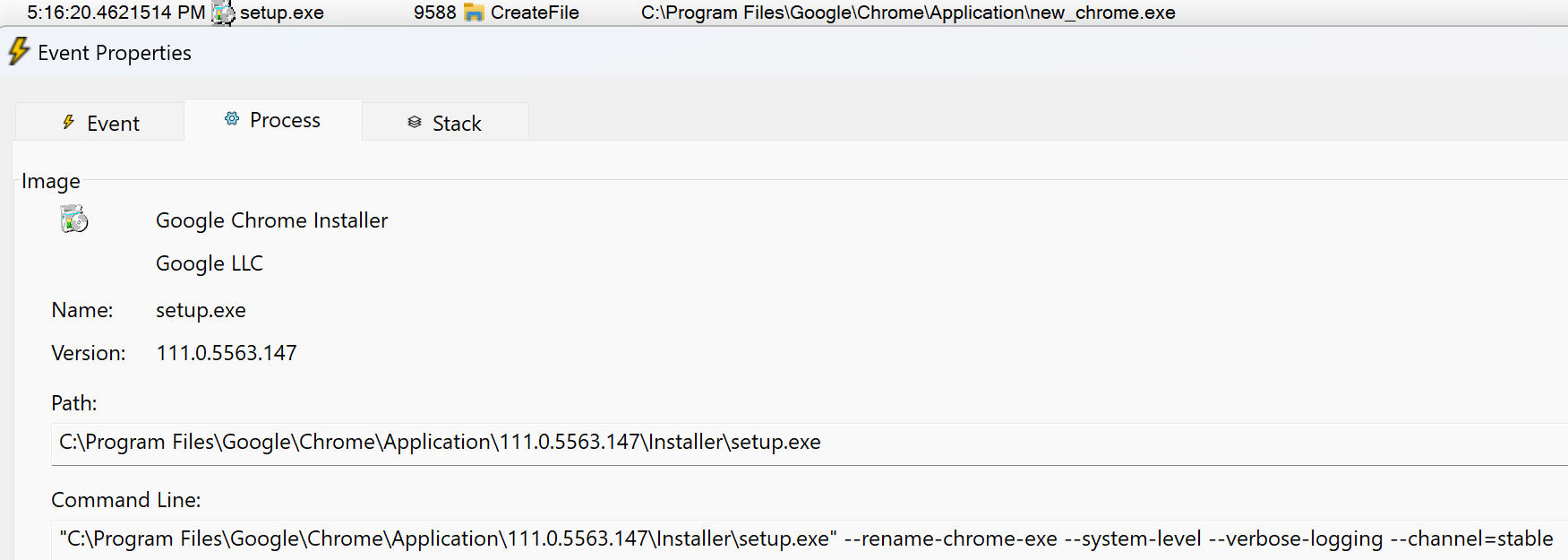
Unfortunately, sometimes a signature may be misleading. For example, both the Microsoft Office Document format and Fiddler’s Session Archive ZIP format are stored as specially-formatted ZIP files, so a file handler looking for a ZIP file’s magic bytes (PK) might get confused and think a Microsoft Word document is a generic archive file:

Alas, the problem is even worse than that, because many file type formats do not demand a magic byte signature at all. For example, a plain text file has no magic bytes, so any text that happens to be at the start of a text file could overlap with another format’s signature. One afternoon decades ago, I was tasked with solving the mystery of why Internet Explorer was renaming a the ZIP specification text file from zip_format.txt to zip_format.zip, but if you look at the bytes, the explanation is pretty obvious:

HTML is another popular format that does not define any magic bytes, and reliably distinguishing between HTML and text is difficult. In the old days, Internet Explorer would scan the first few hundred bytes of the file looking for known HTML tags like <html> and <body>. This worked well enough to be a problem — an author could rely upon this behavior, but then subtly change their document and it would stop working.
Because type-sniffing requires that a file be opened and (some portion of) its contents examined, there are important performance considerations. For example, if you tried to sort a directory listing by the file type, the OS shell would have to open every file to determine its type, and only after opening every file could the list be sorted. This could take a long time, especially if the file is located on a remote network share, or within a compressed archive. Furthermore, this logic would fail if the file could not be opened for some reason (e.g. it was already opened in exclusive mode by some other app, or if reading the file’s content requires additional security permissions).
In a system where type-sniffing is used, a user cannot reliably determine what will happen when a file is opened based solely on the name of the file. They must rely on the OS or browser software to determine the type and expose that information somewhere.
MIME Types
MIME standards describe a system where each type of file is described using a media type, a short, textual string, consisting of a type and subtype separated by a forward slash. Examples include image/jpeg, text/plain (this blog’s namesake), application/vnd.ms-word.document.12 and so on.
If you look at the raw source of an email that has a photo embedded within it, you’ll see the photo’s MIME type mentioned just above the encoded bytes of the image:

And, you’ll see the same if you download an image over HTTPS, listed as the value of the HTTP Content-Type header:

MIME Media types are a great way to represent the type of a file, but there’s a big shortcoming — they only work when there’s a consistent place to store the string, and unfortunately, that isn’t common. For internet-based protocols that offer headers, a Content-Type header is a great place to store the information, but after the file has been downloaded, where do you store the info?
Within some file systems, the data can be stored in an “alternate stream” attached to the file, but not all filesystems support the concept of alternate streams. You could imagine storing the type information in a separate database, but then the system has to be smart enough to keep the information in sync as the file is moved or edited.
Finally, even if you are able to reliably store and recall this information as needed, in a system where MIME types are used, a user cannot reliably determine what will happen when a file is opened based solely on the name of the file. They must rely on the OS or browser software to determine the type and expose that information somewhere.
File Extensions
Finally, we come to file extensions, the system of representing a file’s type using a short identifier at the end of the name, preceded by a dot. This approach is the most common one on popular operating systems, and it’s one I’ve previously described as “The worst approach, except for all of the other ones.”
In terms of disadvantages, there are a few big ones:
- Users might not know what a file’s extension means
- Users can accidentally corrupt a file’s type information if they change the extension while changing a filename
- Some folks think that file extensions are “ugly”
- Attackers might abuse security prompt UIs to try to confuse the user about which part of the filename is the extension. (A common fix is to show the extension separately)
However, there are numerous advantages to file extensions over other approaches:
- Every popular OS supports naming of files, meaning that the file’s type isn’t “lost” as the file moves between different types of systems
- Most UI surfaces are designed to show (at least) a file’s name, which means that the file’s type can be seen by the user
- Most software operates on file names, which means that the file’s type is immediately available without requiring reading any of the file’s content
- File extensions are relatively succinct and do not contain characters (e.g. the forward slash in a MIME-type) that have other meanings in file systems
Interoperability, in particular, is a very important consideration, and combined with the long legacy of systems built around file extensions (dating back more than 40 years), file extensions have become the dominant mechanism for representing a file’s type.
In practice, modern systems usually a mapping between file extensions and MIME types; for example, text/plain files have an extension of .txt, and .csv files have a MIME type of text/csv. In Windows, this mapping is maintained in the Windows Registry:

…and these mappings are respected by most programs (although e.g. Chromium also consults an override table built into the browser itself).
In some cases, a misconfigured MIME mapping in the Windows registry can impact browser scenarios like file upload.
File Extensions are associated with MIME types via registrations with the IANA standards body.
File Extension Arcana
On Windows, users can configure the Explorer Shell to hide the file extension from display; the setting applies to many file types, but not all of them.

MSDN contains a good deal of documentation about how Windows deals with file types, including the ability of a developer to indicate that a given file type is inherently dangerous (FTA_AlwaysUnsafe)
On Windows, you can find a path’s file extension using the PathFindExtensionW function. Note that a valid file name extension cannot contain a space. There’s more information within the article on File Type Handlers.
Windows also has the concept of “perceived types“, which are categories of types, like “image”, “video”, “text”, etc, akin to the first portion of the MIME type.
Importantly, file extensions can be “wrong” — if you rename an executable to have a .txt extension, the system will no longer treat it as potentially dangerous. However, from a security point-of-view, this mismatch is generally harmless– so long as everything treats the file as “text”, it will not be able to execute and damage the system. If you double-click on the misnamed file in Explorer, for example, it will simply open in Notepad and display the binary garbage.
However, the Windows console/terminal (cmd.exe) does not care (much) about file extensions when running programs. If you rename an executable to have a different extension, then type the full filename, the program will run[1]:

If you fail to include the extension, however, the program will not run unless the extension happens to be listed in the %PATHEXT% environment variable, which defaults to PATHEXT=.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC

Some filenames might contain a “double-extension” like (.tar.gz) that conveys that the file is a “Tar file that has been compressed with GZip.” Some software is aware of this multiple-file-extensions concept (and can treat tar.gz files differently than .gz files) but most will simply respect only the so-called final extension.
The std::filesystem::path::extension() function (and Boost) will treat a file that consists of only an extension (e.g. .txt) as having no extension at all. This is an artifact of the fact that such files are considered “dotfiles” on Unix-based systems, where the leading dot suggests that the file should be considered “hidden.” Windows does not really have this concept (the hidden bit is a file attribute instead), and thus you can freely name a text file just .txt and, when invoked from the shell, the system will open Notepad to edit it as it would any other text file.

-Eric
[1] Or, it used to, at least. On my Windows 11 24H2 system, invoking the IAmNotaTextFile.txt file from the terminal opens in Notepad. I’m not sure what changed and when. Maybe there’s a setting?