Microsoft Edge (and upstream Chrome) is available in four different Channels: Stable, Beta, Dev, and Canary. The vast majority of Edge users run on the Stable Channel, but the three pre-Stable channels can be downloaded easily from microsoftedgeinsider.com. You can keep them around for testing if you like, or join the cool kids and set one as your “daily driver” default browser.
Release Schedule
The Stable channel receives a major update every four weeks (Official Docs), Beta channel more often than that (irregularly), Dev channel aims for one update per week, and Canary channel aims for one update per day.
While Stable only receives a major version update every four weeks, in reality it will usually be updated several times during its four-week lifespan. These are called respins, and they contain security fixes and high-impact functionality fixes. (The Extended Stable channel for Enterprises updates only every eight weeks, skipping every odd-numbered release).
Similarly, some Edge features are delivered via components, and those can be updated for any channel at any time.
Why Use a Pre-Stable Channel?
The main reason to use Beta, Dev, or even Canary as your “daily driver” is because these channels (sometimes referred to collectively as “pre-release channels”) are a practical time machine. They allow you to see what will happen in the future, as the code from the pre-release channels flows from Canary to Dev to Beta and eventually Stable.
For a web developer, Enterprise IT department, or ISV building software that interacts with browsers this time machine is invaluable– a problem found in a pre-Release channel can be fixed before it becomes a work-blocking emergency during the Stable rollout.
For Edge and the Chromium project, self-hosting of pre-release channels is hugely important, because it allows us to discover problematic code before billions of users are running it. Even if an issue isn’t found by a hand-authored customer bug report submission, engineers can discover many regressions using telemetry and automatic crash reporting (“Watson”).
What If Something Does Go Wrong?
As is implied in the naming, pre-Stable channels are, well, less Stable than the Stable channel. Bugs, sometimes serious, are to be expected.
To address this, you should always have at least two Edge channels configured for use– the “fast” channel (Dev or Canary) and a slower channel (Beta or Stable).
If there’s a blocking bug in the version you’re using as your fast channel, temporarily “retreat” from your fast to slow channel. To make this less painful, configure your browser profile in both channels to sync information using a single MSA or AAD account. That way, when you move from fast to slow and back again, all of your most important information (see edge://settings/profiles/sync for data types) is available in the browser you’re using.
Understanding Code Flow
In general, the idea is that Edge developers check in their code to the internal Main branch. Code from Microsoft employees is joined by code pulled by the “pump” from the upstream Chromium project, with various sheriffs working around the clock to fix any merge conflicts between the upstream code pumped in and the code Microsoft engineers have added.
Every day, the Edge build team picks a cut-off point, compiles an optimized release build, runs it through an automated test gauntlet, and if the resulting build runs passably (e.g. the browser boots and can view some web pages without crashing), that build is blessed as the Canary and released to the public. Note that the quality of Canary might well be comically low (the browser might render entirely in purple, or have menu items that crash the browser entirely) but still be deemed acceptable for release. The Canary channel, jokes aside, is named after the practice of bringing birds into mining tunnels deep underground. If a miner’s canary falls over dead, the miners know that the tunnel is contaminated by odorless but deadly carbon monoxide and they can run for fresh air immediately. (Compared to humans, canaries are much more sensitive to carbon monoxide and die at a much lower dose). Grim metaphors aside, the Canary channel serves the same purpose– to discover crashes and problems before “regular” users encounter them. Firefox avoids etymological confusion and names its latest channel “Nightly.”
Every week or so, the Edge build team selects one of the week’s Canary releases and “promotes” it to the Dev branch. The selected build is intended to be one of the more reliable Canaries, with fewer major problems than we’d accept for any given Canary, but sometimes we’ll pick a build with a major problem that wasn’t yet noticed. When it goes out to the broader Dev population, Microsoft will often fix it in the next Canary build, but folks on the busted Dev build might have to wait a few days for the next Canary to Dev promotion. It’s for this reason that I run Canary as my daily driver rather than Dev.
Notably for Canary and Dev, the Edge team does not try to exactly match any given upstream Canary or Dev release. Sometimes, we’ll skip a Dev or Canary release when we don’t have a good build, or sometimes we’ll ship one when upstream does not. This means that sometimes (due to pump latency, “sometimes” is nearly “always”) an Edge Canary might have slightly different code than the same day’s Chrome Canary. Furthermore, due to our code pump works, Edge Canary can even have slightly different code than Chromium’s even for the exact same Chrome version number.
In contrast, for Stable, we aim to match upstream Chrome, and work hard to ensure that Version N of Edge has the same upstream changelists as the matching Version N of Chrome/Chromium. This means that anytime upstream ships or respins a new version of Stable, we will ship or respin in very short order.
In some cases, upstream Chromium engineers or Microsoft engineers might “cherry-pick” a fix into the Dev, Beta, or Stable branches to get it out to those more stable branches faster than the normal code-flow promotion. This is done sparingly, as it entails both effort and risk, but it’s a useful capability. If Chrome cherry-picks a fix into its Stable channel and respins, the Edge team does the same as quickly as possible. (This is important because many cherry-picks are fixes for 0-day exploits.)
Code Differences
As mentioned previously, the goal is that faster-updating channels reflect the exact same code as will soon flow into the more-stable, slower-updating channels. If you see a bug in Canary version N, that bug will end up in Stable version N unless it’s reported and fixed first. Other than a different icon and a mention on the edge://version page, it’s often hard to tell which channel is even being used.
However, it’s not quite true that the same build will behave the same way as it flows through the channels. A feature can be coded so that it works differently depending upon the channel.
For example, Edge has a “Domain Actions” feature to accommodate certain websites that won’t load properly unless sent a specific User-Agent header. When you visit a site on the list, Edge will apply a UA-string spoof to make the site work. You can see the list on edge://compat/useragent:
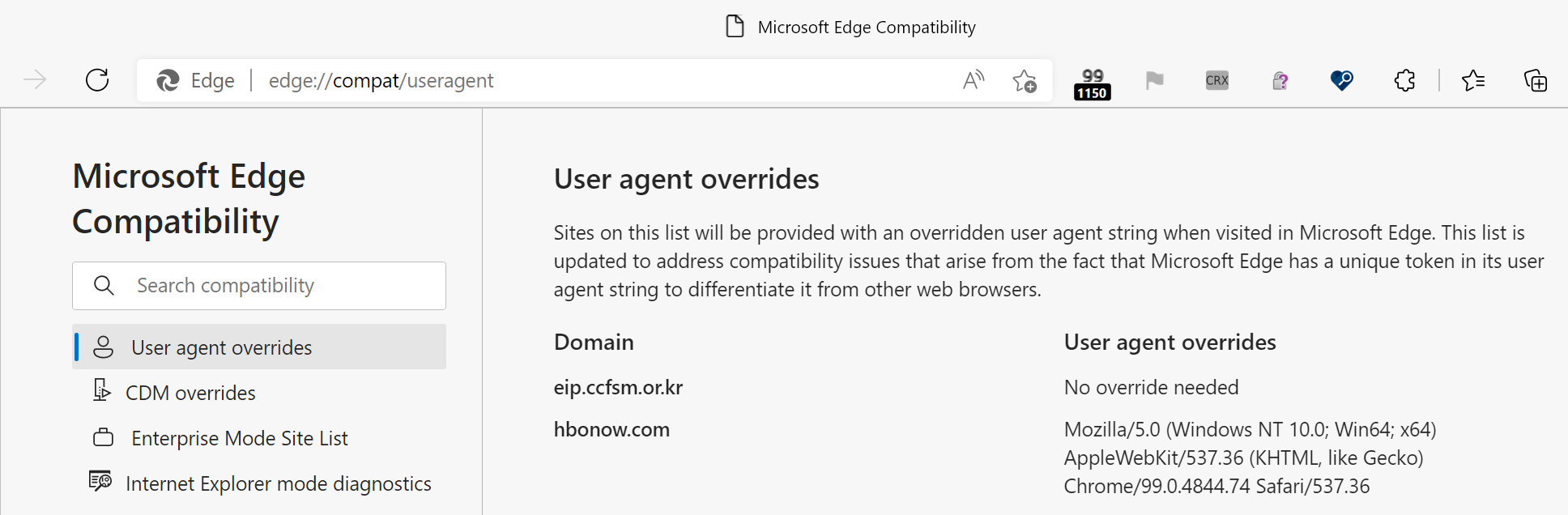
However, this Domain Actions list is applied only in Edge Stable and Beta channels and is not used in Edge Dev and Canary. Update: The UA overrides originally were only used in Edge Stable and Beta channels but as of September 2025, there now exist User-Agent overrides that apply in all channels and which are not shown in edge://compat.
Edge rolls out features via a Controlled Feature Rollout process (I’ve written about it previously). The Experimental Configuration Server typically configures the “Feature Enabled” rate in pre-release channels (Canary and Dev in particular) to be much higher (e.g. 50% of Canary/Dev users will have a feature enabled, while 5% of Beta and 1% of Stable users will get it).
Similarly, there exist several “experimental” Extension APIs that are only available for use in the Dev and Canary channels. There are also some UI bubbles (e.g. warning the user about side-loaded “developer-mode” extensions) that are shown only in the Stable channel.
Chrome and Edge offer a UX to become the default browser, but this option isn’t shown in the Canary channel.
Individual features can also take channel into account to allow developer overrides and the like, but such features overrides tend to be rather niche.
Thanks for helping improve the experience for everyone by self-hosting pre-Stable channels!
Update: Back in 2023 (or so) the Edge team partnered with the Windows Insiders team to broaden use of faster channels of Edge. If you’re testing the “Insiders” builds of Windows, you may get a pre-release (Beta or Dev) channel of Edge as your default (rather than Edge Stable).
-Eric
PS: The Chrome team has a nice article about their channels.