Enough malware researchers now depend upon Fiddler that some bad guys won’t even try to infect your system if you have Fiddler installed.
The Malware Bytes blog post has the details, but the gist of it is that the attackers use JavaScript to probe the would-be victim’s PC for a variety of software. Beyond Kaspersky, TrendMicro, and MBAM security software, the fingerprinting script also checks for VirtualBox, Parallels, VMWare, and Fiddler. If any of these programs are thought to be installed, the exploit attempt is abandoned and the would-be victim is skipped. This attempt to avoid discovery is called cloaking.
This isn’t the only malware we’ve seen hiding from Fiddler—earlier attempts use tricks to see whether Fiddler is actively running and intercepting traffic and only abandon the exploit if it is.
This behavior is, of course, pretty silly. But it makes me happy anyway.
Preventing Detection of Fiddler
Malware researchers who want to help ensure Fiddler cannot be detected by bad guys should take the following steps:
Do not put Fiddler directly on the “victim” machine, instead run it as a remote proxy. – If you must install locally, at least install it to a non-default path.
To run Fiddler as a proxy server external to the victim machine (either use a different physical machine or a VM). – Tick the Tools > Fiddler Options > Connections > Allow remote computers to connect checkbox. Restart Fiddler and ensure the machine’s firewall allows inbound traffic to port 8888. – Point the victim’s proxy settings at the remote Fiddler instance. – Visit http://fiddlerserverIP:8888/ from the victim and install the Fiddler root certificate
Click Rules > Customize Rules and update the FiddlerScript so that the OnReturningError function wipes the response headers and body and replaces them with non-descript strings. Some fingerprinting JavaScript will generate bogus AJAX requests and then scan the response to see whether there are signs of Fiddler.
ZIP is a great format—it’s extremely broadly deployed, relatively simple, and supports a wide variety of use-cases pretty well. ZIP is the underlying format beneath Java (.jar) Archives, Office (docx/xlsx/pptx) files, Fiddler (.saz) Session Archive ZIP files, and many more.
Even though some features (Unicode filenames, AES encryption, advanced compression engines) aren’t supported by all clients (particularly Windows Explorer), basic support for ZIP is omnipresent. There are even solid implementations in JavaScript (optionally utilizing asmjs), and discussion of adding related primitives directly to the browser. 2024 Update: I made a simple WebApp for zipping files.
I learned a fair amount about the ZIP format when building ZIP repair features in Fiddler’s SAZ file loader. Perhaps the most interesting finding is that each individual file within a ZIP is compressed on its own, without any context from files already added to the ZIP. This means, for instance, that you can easily remove files from within a ZIP file without recompressing anything—you need only delete the removed entries and recompute the index. However, this limitation also means that if the data files you’re compressing contain a lot of interfile redundancy (duplicated data across multiple files), the compression ratio does not improve as it would if there were intrafile redundancy (duplicate data in a single file).
This limitation can be striking in cases like Fiddler, where there may be a lot of repeated data across multiple Sessions. In the extreme case, consider a SAZ file with 1000 near-identical Sessions. When that data is compressed to a SAZ, it is 187 megabytes. If the data were instead compressed with 7-Zip, which shares a compression context across embedded files, the output is 99.85% smaller!
In most cases, of course, the Session data is not identical, but web traffic sessions on the whole tend to contain a lot of redundancy, particularly when you consider HTTP headers and the Session metadata XML files.
The takeaway here is that when you look at compression, the compression context is very important to the resulting compression ratio. This fact rears its head in a number of other interesting places:
brotli compression achieves high-compression ratios in part by using a 16 megabyte sliding window, as compared to the 32kb window used by nearly all DEFLATE implementations. This means that brotli content can “point back” much further in the already-compressed data stream when repeated data is encountered.
brotli also benefits by pre-seeding the compression context with a 122kb static dictionary of common web content; this means that even the first bytes of a brotli-compressed response can benefit from existing context.
SDCH compression achieves high-compression ratios by supplying a carefully-crafted dictionary of strings that result in an “ideal” compression context, so that later content can simply refer to the previously-calculated dictionary entries.
Adding context introduces a key tradeoff, however, as the larger a compression context grows, the more memory a compressor and decompressor tend to require.
While HTTP/2 reduces the need to concatenate CSS and JS files by reducing the performance cost of individual web requests, HTTP response body compression contexts are still per-resource. That means that larger files tend to yield higher-compression ratios. See “Bundling Improves Compression.”
Compression contexts can introduce information disclosure security vulnerabilities if a context is shared between “secret” and “untrusted” content. See also CRIME, BREACH, and HPACK. In these attacks, the bad guy takes advantage of the fact that if his “guess” matches some secret string earlier in the compression context, it will compress better (smaller) than if his guess is wrong. This attack can be combatted by isolating compression contexts by trust level, or by introducing random padding to frustrate size analysis.
Want to learn much more about ZIP files? Check out these twogreat posts; or you can learn more about the author of PKZIP in this great (sad) video.
tl;dr: Download apps can taint a file originating from the web so that other apps will handle it more carefully.
Background
To help protect the user and their device, Windows and its applications will often treat files originating from the Internet more cautiously than files generated locally. The Windows Security Zones determination process is most directly implemented by the MapURLToZone API; that API accepts a URL or a file path and returns the correct Zone for the file.
An obvious problem arises, however– content downloaded from web browsers or email programs resides on the local disk, but originated from the Internet.
Windows uses a simple technique to keep track of where downloaded files originated. Each downloaded file is is tagged with a hidden NTFS Alternate Data Stream file named Zone.Identifier. You can check for the presence of this “Mark of the Web” (MotW) using dir /r or programmatically, and you can view the contents of the MotW stream using Notepad:
Within the file, the ZoneTransferelement contains a ZoneIdelement with the ordinal value of the URLMon Zone from which the file came1. The value 3 indicates that the file is from the Internet Zone2.
Aside: One common question is “Why does the file contain a Zone Id rather than the original URL? There’s a lot of cool things that we could do if a URL was preserved!” The answer is mostly related to privacy—storing a URL within a hidden data stream is a foot gun that would likely lead to accidental disclosure of private URLs. This problem isn’t just theoretical—the Alternate Data Stream is only one mechanism used for MotW. Another mechanism involves writing a <!--saved from url=(0018)http://example.com --> comment to HTML markup; that form does include a raw URL. A few years ago, attackers noticed that they could use Google to search for files containing a MOTW of the form <!--saved from url(0042)ftp://username:secretpassword@host.com –> and collect credentials. Oops.Update: Microsoft later decided the tradeoff was worth it. Windows 10+ includes the referrer URL, source URL and other information in the Zone.Identifier stream.
Browsers and other internet clients (e.g. email and chat programs) can participate in the MOTW-marking system by using the IAttachmentExecute interface’s methods (preferred) or by writing the Alternate Data Stream directly. Chrome uses IAttachmentExecute and thus includes the URL information on Windows 10. Firefox writes the Alternate Data Stream directly (and as of February 2021, it too includes the URL information).
Handling Marked Files
The Windows Shell and some applications treat Internet Zone files differently. For instance, examining a downloaded executable file’s properties shows the following notice:
More importantly, attempting to run the executable using Windows Explorer or ShellExecute() will first trigger evaluation using SmartScreen Application Reputation (Win8+) and any registered anti-virus scanners. The file’s digital signature will be checked, and execution will be confirmed with the user, either using the older Attachment Execution Services prompt, or the newer UAC elevation prompt:
Notably, MotW files invoked by non-shell means (e.g. cmd.exe or PowerShell) do not trigger security checks or prompts.
Smart App Control
While SmartScreen only checks the reputation of the entry point program, Windows 11’s Smart App Control goes further than SmartScreen and evaluates trust/signatures of all code (DLLs, scripts, etc) that is loaded by the Windows OS Loader and script engines.
SmartAppControl blocks a downloaded JS file from running
The current list of SAC-blocked-if-MotW extensions is .appref-ms, .appx, .appxbundle, .bat, .chm, .cmd, .com, .cpl, .dll, .drv, .gadget, .hta, .iso, .js, .jse, .lnk, .msc, .msp, .ocx, .pif, .ppkg, .printerexport, .ps1, .rdp, .reg, .scf, .scr, .settingcontent-ms, .sys, .url, .vb, .vbe, .vbs, .vhd, .vhdx, .vxd, .wcx, .website, .wsf, .wsh.
Office
Microsoft Office documents bearing a MotW open in Protected View, a security sandbox that attempts to block many forms of malicious content, and starting in 2022, macros are disabled in Internet-sourced documents.
Other Apps
As of October 2024, the Microsoft Management Console will refuse to load a .msc file from the Internet Zone (with a slightly misformatted prompt):
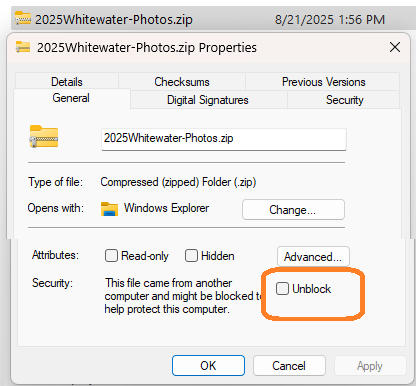
Some other applications inherit protections against files bearing a MotW, but don’t have any user-interface that explains what is going on. For instance, if you download a CHM with a MotW, its HTML content will not render until you unblock it using the “Always ask before opening this file” or the “Unblock” button:
What Could Go Wrong?
With such a simple scheme, what could go wrong? Unfortunately, quite a lot.
Internet Clients must participate
The first hurdle is that Internet clients must explicitly mark their downloads using the Mark-of-the-Web, either by calling IAttachmentExecute or by writing the Alternate Data Stream directly. Most popular end-user download clients will do so, but support is neither universal nor comprehensive.
For instance, for a few years, Firefox failed to mark downloads if the user used the Open command instead of Save. Similarly, in the past, browser plugins might have allowed attackers to save files to disk and bypass MotW tagging.
Microsoft Outlook (tested v2010) and Microsoft Windows Live Mail Desktop (tested v2012 16.4.3563.0918) both tag message attachments with a MotW you double-click on an attachment or right-click and choose Save As. Unfortunately, however, both clients fail to tag attachments if the user uses drag-and-drop to copy the attachment to somewhere in their filesystem. This oversight is likely to be seen in many different clients, owing to the complexity in determining the drop destination.
There are many ways to download files to a Windows system that do not result in writing a MotW to the file. For example, you can use the copy of CURL that ships in Windows, bitsadmin, a script that calls into WinINET or WinHTTP or System.NET objects (including from PowerShell), or you can use any of various binaries that offer downloads as a side-effect. The fact that these tools do not apply MotW is by-design — these are not common vectors for distribution of socially-engineered malware, and other security checks (e.g. Defender AV) still run.
Update: In the summer of 2024, a security update to File Explorer in Windows began adding a MotW to files copied to the local computer from untrusted network shares. When performing a file copy, File Explorer checks if the source file’s zone is Internet or Untrusted and, if so, it then evaluates URLACTION_SHELL_EXECUTE_HIGHRISK for the source file’s Zone. If that URLAction’s result is not set to URLPOLICY_ALLOW, then the destination file has a MotW added to it. A Group Policy was added to turn off the new behavior if desired.
Target file system must be NTFS
The Zone.Identifier stream can only be saved in an NTFS stream. These streams are not available on FAT32-formatted devices (e.g. some USB Flash drives), CD/DVDs, or the ReFS file system in Windows 8 / Server 2012 (support was later added to ReFS in Windows 8.1).
If you copy a file tagged with a MotW to a non-NTFS filesystem (or try to save it to such a file system to start with), the Mark of the Web is omitted and the protection is lost.
Originating location must be Internet or Restricted Zone
The IAttachmentExecute:Save API will not write the MotW unless the URL provided in the SetSource method is in a zone configured to write it (because that Zone’s setting for Launching applications and unsafe files is set to Enable):
Thus, by default, a MoTW can be written for Trusted, Internet or Restricted Sites zones. However, things get pretty weird for the Trusted Zone; a MotW is written only for a download from the Trusted Zone if there’s a Referrer and that Referrer is not Local Machine Zone1.
Normally, Windows will howl if an unsafe “Enable” configuration is set for the Internet Zone, but there’s a registry key that turns off the “Your security settings are unsafe” warning bar shown:
Policy must not disable the feature
Writing of the MoTW can be suppressed in the AttachmentExecuteServices API via Group Policy. In GPEdit.msc, see Administrative Templates > Windows Components > Attachment Manager > Do not preserve zone information in file attachments.
In the registry, the REG_DWORD SaveZoneInformation controls the behavior.
A value of 1 will prevent the MoTW from being written to files. (No, this isn’t an intuitive constant. For this policy, 1 means disabled, while 2 means enabled.)
For example, if the source of the download is a data: URI the browser has no great way to know what marking to put on the file. For data URIs or other anonymous sources, writing a default of about:internet is a common conservative choice to ensure that the file was treated as if it came from the Internet Zone. In Chrome v130, Chrome changed to begin storing the request_initiator for data: URL downloads.
Chromium stores about:internet rather than the real urls when saving downloaded files in Private Mode instances:
A url of about:untrusted would cause the file to be treated as originating from the Restricted Sites Zone.
blob: scheme URIs have a similar issue, but because blob URIs only exist within a security context (https://example/download/file.aspx can create blob:https://example/guid) the client can write that security context’s origin as a URL (e.g. https://example/ in this case) into the MoTW to help ensure proper handling.
Origin-Laundering via Archives
One simple trick that attackers use to try to circumvent MotW protections is to enclose their data within an archive like a .ZIP, .7z, or .RAR file, or a virtual disk like a .iso file. Attackers may go further and add a password to block virus scanners; the password is provided to the victim in the attacking webpage or email.
In order to remain secure, archive extractors must correctly propagate the MotW from the archive file itself to each file extracted from the archive.
Despite being one of the worst ZIP clients available, Windows Explorer gets this right:
In contrast, 7-zip does not reliably get this right. Malware within a 7-zip archive can be extracted without propagation of the MotW. 7-zip v15.14 will add a MotW if you double-click an exe within an archive, but not if you extract it first. The older 7-zip v9.2 did not tag with MotW either way.
Note that many command-line extractors don’t propagate MotW to extracted files: this isn’t generally considered a security issue because at the point where an attacker can coax a user to enter the command line, they’ve already managed to get to a surface unprotected by most MotW-checks.
Loss via Transfers
A file’s Zone.Identifier stream can be lost if the file is copied to a drive that does not support alternate streams (e.g. a FAT32-formatted USB key), or if it is copied via a tool that does not copy alternate streams (e.g. Remote Desktop, various cloud file-synchronization utilities).
SmartScreen & the User may unmark
Finally, users may unmark files using the Unblock button on the file’s Properties dialog in Windows Explorer, or by unticking the “Always ask before opening this file” checkbox on the pre-launch security prompt. The HideZoneInfoOnProperties policy can be used to hide these UIs from the user.
Similarly, on systems with Microsoft SmartScreen, Edge’s SmartScreen AppRep itself may unmark the file during download for improved performance and user-experience (avoiding duplicate SmartScreen web service checks).
Originally, SmartScreen would update the Zone.Identifier stream by replacing the ZoneId with an (undocumented) field of AppZoneId=4, but this changed in March 2022.
Update March 2022: SmartScreen changed to write a separate SmartScreen alternate stream from Edge, rather than modifying the Zone.Identifier stream.
When handling a file marked with a Zone.Identifier (MotW), the SmartScreen client checks for a trivial :SmartScreen alternate data stream containing the text Anaheim. If present, the client concludes that Edge (codename Anaheim) already performed the AppRep call and allowed the file3.
Update Feb 2023: When executing a program from the Windows Shell in Win11, the Zone.Identifier stream is removed from the file after the successful AppRep check.
File Opener/Launcher must participate
In order for a MotW to have an impact, the application that opens the file must check the zone of the file.
When launching a file, to have the MotW consulted, use ShellExecuteEx. The CreateProcess API does not care about the MotW.
ShellExecuteEx() callers may ignore the mark by passing SEE_MASK_NOZONECHECKS.
An environment variable named SEE_MASK_NOZONECHECKS with value 1 will disable the Zone checking inside ShellExecute().
1 This is an oversimplification. The ZoneIdvalue written is the least-privileged zone of the calculated zones for the caller-supplied Source URL and the Referrer URL. Interestingly, this means that if you download a Trusted Zone file from a link on an Internet Zone webpage, it will be treated as if it had originated from the Internet Zone.
There are other (surprising) nuances as well.
First, if either the Source or Referrer is not supplied, it is treated as “Local Machine Zone”; a caller can pass about:internet as a generic “Internet Zone” URL, or about:untrusted as a generic “Restricted Sites” URL. Using a generic URL can be necessary if the file is sourced from a non-basic URL like blob: or one that is over 2083 characters (INTERNET_MAX_URL_LENGTH).
Second, the determination of what zone is “least-privileged” diverges from the standard order for Windows Security Zones. The MoTW code orders the Zones as Untrusted < Internet < Intranet < Local Machine < Trusted. The standard ordering in URLMon is Untrusted < Internet < Trusted < Intranet < Local Machine.
Third, the Zone Marking code is hard-coded to avoid writing a MoTW to a file whose “least-privileged” zone is Local Machine. This seems reasonable (otherwise copying a file from the local computer to the local computer could add a MoTW), but, coupled with the non-standard ordering of Zones, results in a surprising outcome. To wit, if you call the API with a Source URL in the Trusted Zone, but do not supply a Referrer URL (say, because the user entered the URL in the address bar, or the download link has a rel=noreferrer attribute), no MoTW is written to the file (test case).
2 The Windows Zone identifier constants are Restricted Zone=4, Internet=3, Trusted Zone=2, Intranet=1. The Local Machine Zone is 0, but the API will not write a Zone.Identifier stream for a file whose ZoneId is 0.
3 Security-conscious readers might be alarmed: Could an attacker just create a :SmartScreen stream containing the text Anaheim to bypass AppRep checks? Maybe. It’s important to understand that in the vast majority of cases, an attacker with the ability to create the :SmartScreen stream could also simply delete the Zone.Identifier stream, resulting in the same impact.
It’s easy to imagine designs that try to do something more clever (e.g. put a signed token into the :SmartScreen stream instead) but these entail significant complexity and provide little protection because, again, the typical usage of MotW is to mark files fetched by browsers and other internet clients, which do not offer mechanisms to write or manipulate NTFS alternate streams.
I’m passionate about building tools that help developers and testers discover, analyze, and fix problems with their sites.
Some of the first code I ever released was a set of trivial JavaScript-based browser extensions for IE5. I later used the more powerful COM-based extensibility model to hack together some add-ons that would log ActiveX controls and perform other tasks as you browsed. But the IE COM extensibility model was extremely hard to use safely, and I never released any significant extensions based on it.
Later, I built a simple Firefox extension based on their XUL Overlay extensibility model to better-integrate Fiddler with Firefox, but this extension recently stopped working as Mozilla begins to retire that older extensibility model in favor of a new one.
Having joined the Chrome team, I was excited to see how difficult it would be to build extensions using the Chrome model which is conceptually quite a bit different than both the old IE and Firefox models. Both Microsoft Edge (IE’s successor) and Firefox are adopting the Chrome model for their new extensions, so I figured the time would be well-spent.
I haven’t ever coded anything of consequence using JavaScript, HTML, and CSS, so I expected that the learning curve would be pretty steep.
It wasn’t.
Sitting on the couch with my older son and an iPad a few weeks ago, I idly Googled for “Create Chrome Extension.” One of the first hits was John Sonmez’s article “Create a Chrome Extension in 10 Minutes Flat.” I’m currently reading a book he wrote and I like his writing style, so with a fair amount of skepticism, I opened the article.
Wow, that looks easy.
After my kids went to bed that night, I banged out my first trivial Chrome extension. After suffering from nearly non-existent documentation of IE’s extension models, and largely outdated and confusing docs for Mozilla’s old model, I was surprised and delighted to discover that Chrome has great documentation for building extensions, including a simple tutorial and developer’s guide
Over the next few weeks, I built my moarTLS Analyzer extension, mostly between the hours of 11pm and 2am– peak programmer hours in my youth, but that was long ago.
I pulled out some old JavaScript and CSS books I’d always been meaning to read, and giggled with glee at the joy of building for a modern browser where all of the legacy hacks these books spilled so much ink over were no longer needed.
I found a few minor omissions from the Chrome documentation (bugs submitted) but on the whole I never really got stuck.
The code is simple and you can read it all in less than five minutes:
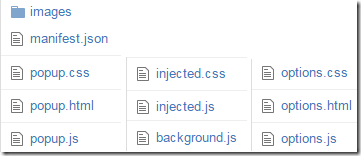
The images folder contains the images used in the toolbar and the report UI. The manifest.json file defines the extension’s name, icons, permissions, and browser compatibility. The popup.{css|html|js} files implement the flyout report UI. When invoked, the flyout uses the executeScript and insertCSS APIs to add the injected.{css|js} files to each frame in the currently loaded page. The script sends a message back to the popup to tattle on any non-secure links it finds. The background.js file watches for File Downloads and shows an alert() if any non-secure downloads occur. The options.{css|html|js} files implement the settings block that control the extension’s settings.
Things I Learned
allFrames Isn’t Always
When you call chrome.tabs.executeScript with allFrames: true, your script will only be injected into same-origin subframes if your manifest.json only specifies the activeTab permission. To have it inject your script into cross-origin subframes, you must declare the <all_urls> permission. This is unfortunate, but entirely logical for security reasons. Declaring the all_urls permission results in a somewhat scary permissions dialog when the extension is installed:
The Shadow DOM Hides Things
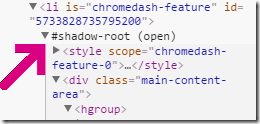
When I was testing the extension, I noticed that it wasn’t working properly on the ChromeStatus site. A quick peek at the Developer Tools revealed that my call to document.querySelectorAll(“a[href]”) wasn’t turning up any anchor elements nested inside the #shadow-root nodes.
These nodes are part of the Shadow DOM, a technology that allows building web pages containing web components—encapsulated blocks of markup written in HTML and CSS. By default, the internal markup of these nodes is invisible to normal DOM APIs like getElementsByClassname.
Fortunately, this was easy to fix. While deprecated in CSS, the /deep/ selector can still be used by querySelectorAll, and changing my code to document.querySelectorAll(“* /deep/ a[href]”); allowed enumeration of the links in the Shadow DOM.
The Downloads API Is Limited
The chrome.downloads API offers a lot of functionality, but not the one key thing I wanted—access to the raw file after the download is complete. Enabling moarTLS to warn users when a file download came from HTTP was easy, but I wanted to also automatically compute the hash of the downloaded file and display it for examination (since some sites still don’t sign files but they do publish their hashes). (Chromium itself calculates a SHA-256 hash on DownloadItems but does not appear to expose it to extensions.)
Unfortunately, it looks like the only way to get access to the file’s content is to use a native platform installer to install an “Native Host” executable, and have the Chrome extension use nativeMessaging to invoke that executable on the file. Ideally, you’d write the native portion in a cross-platform language like Go so that it will run on Windows, Linux, and OS X.
Landmines around filename case-sensitivity
chrome-extension URLs are case-sensitive only on Linux and CrOS which means that you can easily write an extension that works correctly on Mac/Win and fails on CrOS and Linux; on CrOS, the extension might be marked as corrupt while on Linux the request will just fail (probably breaking the extension).
Publishing your Extension is Easy
I figured getting my add-on listed on the Chrome Web Store would be complicated. It’s not. It costs $5 to get a developer account. Surprisingly, you don’t use the Pack extension command in the chrome://extensions tab—you instead just ZIP up the folder containing your manifest and other files. Be sure to omit unneeded files like unit tests, unused fonts, etc, and optimize your images. After you’ve got that ZIP, you simply upload it to the store. You’ll need to use the WebUI to upload a number of screenshots and other metadata about the extension, but it’ll be live for everyone to download shortly thereafter.
Updates are simple—just upload a new ZIP file, tweak any metadata, and wait about an hour for the update to start getting deployed to users.
Firefox, Edge, and Opera
After publishing my extension yesterday, two interesting things happened. First, someone said “I’ll use it when it runs in Firefox” and second, Microsoft released the first build of Edge with support for browser extensions. Last night, decided to look at what’s involved in porting moarTLS to Firefox and Edge.
For Firefox, it’s actually pretty straightforward and took about twenty minutes (coding without a mouse!):
2. The chrome object is named browser instead. You can resolve this with the following code at the top of your script: if (!chrome) chrome = browser || msBrowser || chrome; The chrome object is also defined, so it’s not clear there’s any value in preferring one over the other
3. It appears the/deep/ selector doesn’t work.
4. Styles using the -webkit- prefix need either the -moz- prefix or need to gracefully fall back.
5. The storage API is not available to content scripts yet.
Getting the extension running in Microsoft Edge Legacy wasn’t possible yet. At first, even after adding:
“minimum_edge_version”: “33.14281.1000.0”,
…to the manifest, the extension wouldn’t load at all. SysInternals’ Process Monitor revealed that the browser process was getting Access Denied when trying to read manifest.json. I suspect the reason is that Microsoft hasn’t yet hooked up the plumbing that allows read access out of the sandboxed AppContainer—this explains why Microsoft’s three demo extensions are unpacked by an executable instead of a plain ZIP file—the executable probably calls ICALCS.exe to set up the permissions on the folder to allow read from the sandbox. I tested this theory by allowing their installer to unpack one of the demo extensions, then I ripped out all of their files in that folder and replaced them with my own and it was loaded.
The extension still doesn’t run properly however; none of Microsoft’s three demos uses a browser_action with a default default_popup so I’m guessing that maybe they haven’t hooked up this capability yet. I’m hassling the Edge team on Twitter. :)
I haven’t tried building an Opera Extension yet, but I suspect my Chrome Extension will probably work almost without modification.
To secure web connections, TLS-enabling servers is only half the battle; the other half is ensuring that TLS is used everywhere.
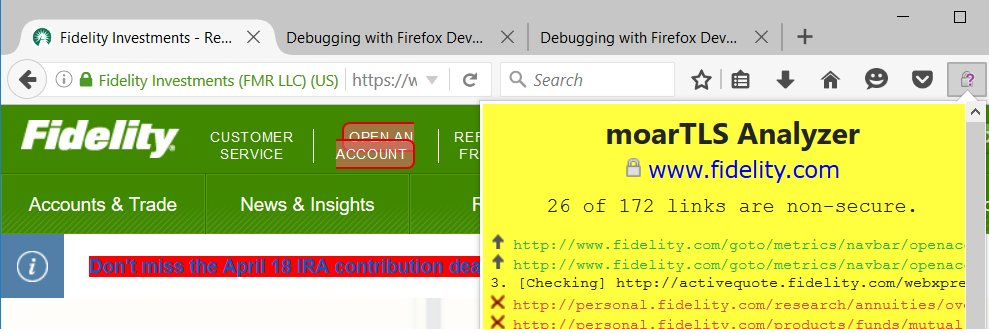
Unfortunately, many HTTPS sites today include insecure references that provide an network-based attacker the opportunity to break into the user’s experience as they interact with otherwise secure sites. For instance, consider the homepage of Fidelity Investments:
You can see that the site has got the green lock and it’s using an EV certificate such that the organization’s name and location are displayed. Looks great! Even if you loaded this page over a coffee shop’s WiFi network, you’d feel pretty good about interacting with it, right?
Unfortunately, there’s a problem. Hit F12 to open the Chrome Developer Tools, and use the tool to select the “Open An Account” link in the site’s toolbar. That’s the link you’d click to start giving the site all of your personal information.
Oops. See that http:// hiding out there? Even though Fidelity delivered the entire homepage securely, if a user clicks that link, a bad guy on the network has the opportunity to supply his own page in response! He can either return a HTML response that asks the victim for their information, or even redirect to a phony server (e.g. https://newaccountsetup.com) so that a lock icon remains in the address bar.
Adding insult to injury, what happens if a bad guy doesn’t take advantage of this hole?
That’s right, in the best case, the server just sends you over to the HTTPS version of the page anyway. It’s as if the teller at your bank carried cash deposits out the front door, walking them around the building before reentering the bank and carrying them to the vault!
Okay, so, what’s a security-conscious person to do?
First, recognize the problem. If you stumble across a “HTTP” reference, it’s a security bug. Either fix it, or complain to someone who can.
Web developers are familiar with two categories of Mixed Content: Active Mixed-Content (e.g. script) which is blocked by default, and Passive Mixed-Content (images, etc), which browsers tend to allow by default, usually with the penalty of removing the lock from the address bar.
However, secure pages with non-secure links don’t trigger ANY warning in the browser.
For now, let’s call the problem described in this post Latent Mixed Content.
Finding Latent Mixed Content
Finding HTTP links isn’t hard, but it can be tedious. To that end, between late-night feedings of my newborn, I’ve been learning Chrome’s extension model– a wonderful breath of fresh air after years of hacking together COM extensions in IE. The result of that effort is now available for your bug-hunting needs.
The extension adds an unobtrusive button to Chrome’s toolbar. The extension is designed to have little-to-no impact on the performance or operation of Chrome unless you actively interact invoke the extension.
When the button is clicked, the extension analyzes the current page to find out which hyperlinks (<a> elements) are targeting a non-secure protocol. If the page is free of non-secure links, the report is green:
If the current page’s host sends a HTTP Strict Transport Security directive, a green lock is shown next to the hostname at the top of the report: . Click the hostname to launch the SSLLabs Server Test for the host to explore what secure protocols are supported and find any errors in the host’s certificate or TLS configuration.
If the page contains one or more non-secure links, the report gets a yellow background and the non-secure links are listed:
The non-secure links in the content of the page are marked in red for ease-of-identification:
Alt+Click (or Ctrl+Click) on any entry in the report to cause the extension to probe the target hostname to see whether a HTTPS connection to the listed hostname is possible. If a HTTPS connection attempt succeeds, a grey arrow is shown. If the connection attempt fails (indicating that the server is only accessible via HTTP), a red X is shown:
If the target is accessible over HTTPS and the response includes a HTTP Strict Transport Security header, the grey arrow is replaced with a green arrow:
Note: Accepting HTTPS connections alone doesn’t necessarily indicate that the host completely supports HTTPS—the secure connection could result in error pages or redirections to a redirection back to HTTP. But a grey arrow indicates that at least the server has a valid certificate and is listening for TLS connections on port 443. Before updating each link to HTTPS, verify that the expected page is returned.
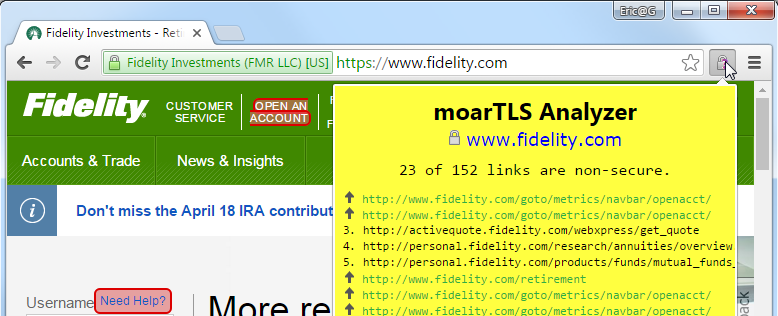
Returning to our original example, Fidelity’s non-secure links are readily flagged:
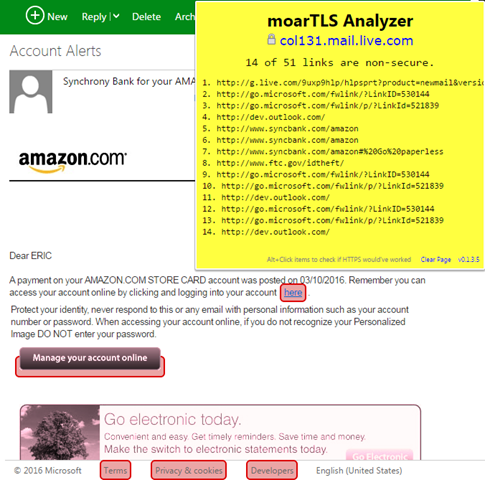
If you read your email in a web client like GMail or Hotmail, you can also check whether your HTML emails are providing secure links:
HTTP-Delivered Pages
The examples above presuppose that the current page was delivered over HTTPS. If the page itself was delivered non-securely (over HTTP), invoking the moarTLS extension colors the background of the page itself red. In the report flyout, the hostname shown at the top is prefixed with http/. The icon adjacent to the domain name will either be an up-arrow:
…indicating that the host accepts HTTPS connections, or a red-X, indicating that it does not:
The extension exposes the option (simply right-click the icon) to flip insecurely-delivered images:
When this option is enabled, images delivered insecurely are flipped vertically, graphically demonstrating one of the least malicious actions a Man-in-the-Middle could undertake when exploiting a site’s failure to use HTTPS.
The Warn on non-secure downloads option instructs the extension to warn you when a file download occurs if either the page linking to a download, or the download itself, used a non-secure protocol:
Non-secure file downloads are extremely dangerous; we’ve already seen attacks in-the-wild where a MITM intercepts such requests and responds with malware-wrapped replacements. Authenticode-signing helps mitigate the threat, but it’s not available everywhere, and it should be bolstered with HTTPS.
Limitations
This extension has a number of limitations; some will be fixed in future updates.
False Negatives
moarTLS looks only at the links in the markup. JavaScript could intercept a link click and cause an non-secure navigation when the user clicks a link with an otherwise secure HREF.
moarTLS does not currently check the source of CSS background images.
moarTLS does not currently mangle insecurely-delivered fonts, audio, or video.
moarTLS only evaluates links currently in the page. If links are added later (e.g. via AJAX calls), they’re not marked unless you click the button again.
False Positives
moarTLS looks only at the links in the markup. JavaScript could intercept a link click and cause an secure navigation when the user clicks a link with an otherwise non-secure HREF. Arguably this isn’t a false-positive because the user may have JavaScript disabled.
moarTLS looks only at the link, and does not exempt links which are automatically upgraded by the browser due to a HSTS rule. Arguably this isn’t a false-positive because not all browsers support HSTS, and the user may copy a URL to a non-browser client (e.g. curl, wget, etc).
moarTLS isn’t aware of upgrade-insecure-requests, although that only helps for same-origin navigations. Arguably this isn’t a false-positive because not all browsers support this CSP directive, and the user may copy a URL to a non-browser client (e.g. curl, wget, etc).
moarTLS isn’t aware of block-all-mixed-content. Arguably this isn’t a false-positive because not all browsers support this CSP directive, and the user may copy a URL to a non-browser client (e.g. curl, wget, etc).
Q&A
Q1. Why is this an extension? Shouldn’t it be in the Developer Tools’ Security pane, which currently flags active and passive mixed content:
A1. Great idea. :)
Q2. How do I examine “popups” which don’t show the Chrome toolbar?