Last Update: 8 March 2024
Over the years, I’ve written a bunch about authentication in browsers, and today I aim to shed some light on another authentication feature that is not super-well understood: Browser SSO.
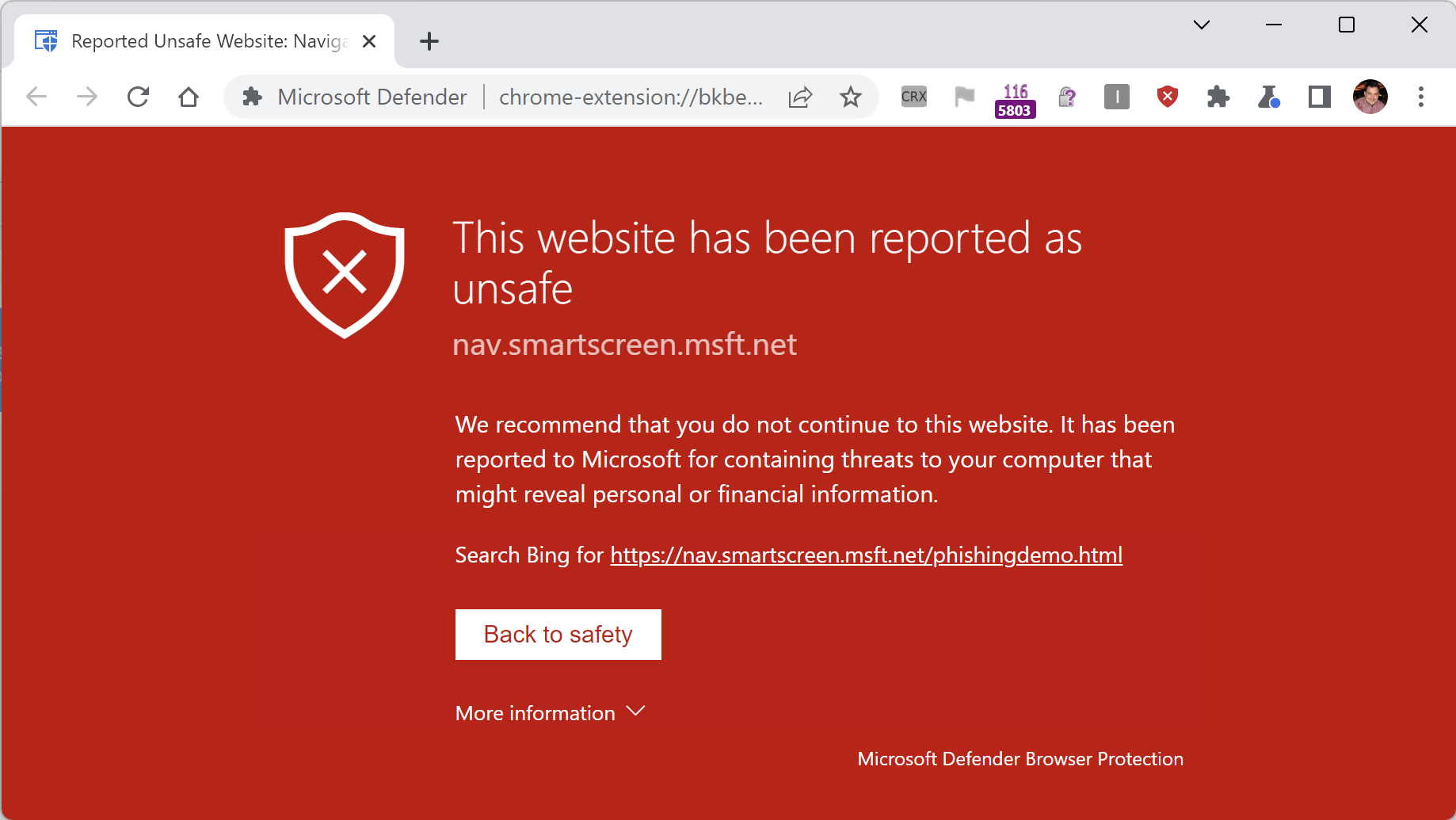
Recently, a user expressed surprise that after using the browser’s “Clear browsing data” option to delete everything, when they revisited https://portal.azure.com, they were logged into the Azure Portal app without supplying either a username or a password. Magic!
Here’s how that works.
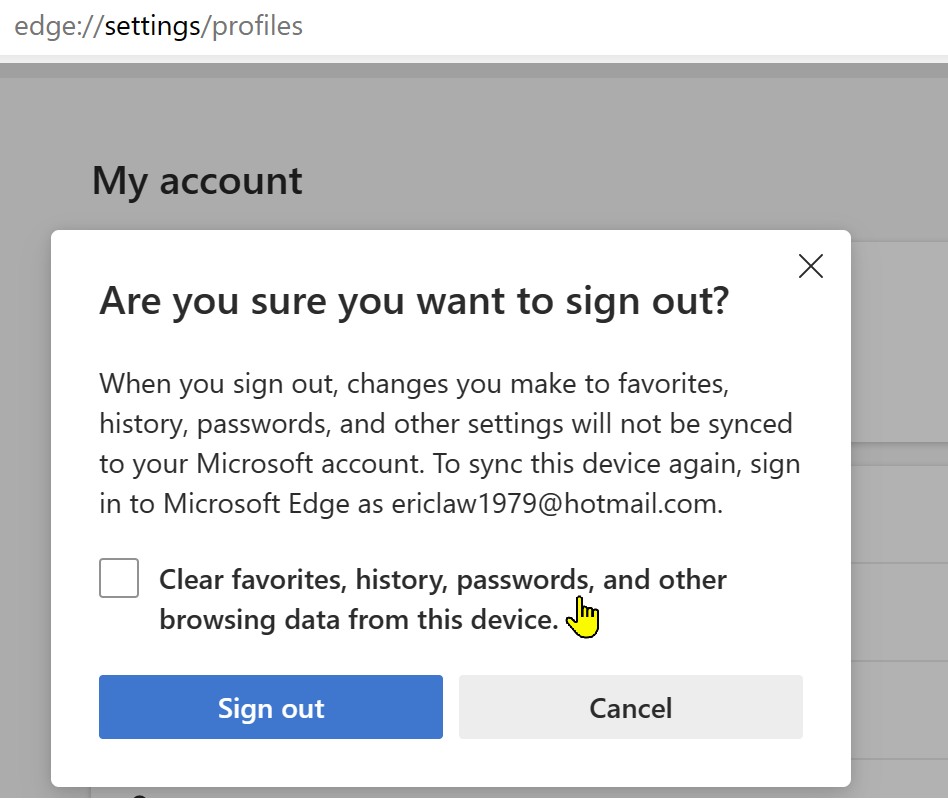
When you select this option:

… the browser will delete all cookies. Because auth tokens are often stored in cookies, as noted in the text, this option indeed “Signs you out of most sites.” And, in fact, if you go look at your cookie jar, you will see that your cookies for e.g. https://portal.azure.com are indeed gone. In a strictly literal sense, you are no longer “logged into” Azure.
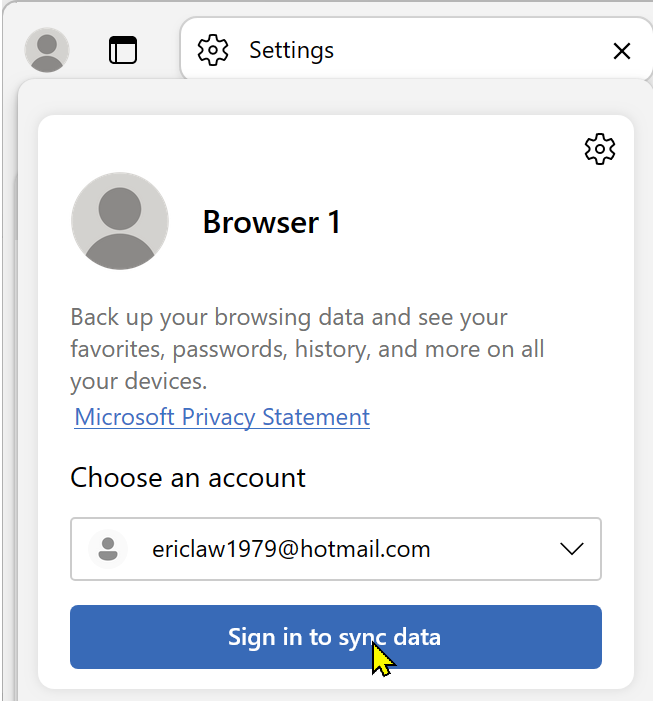
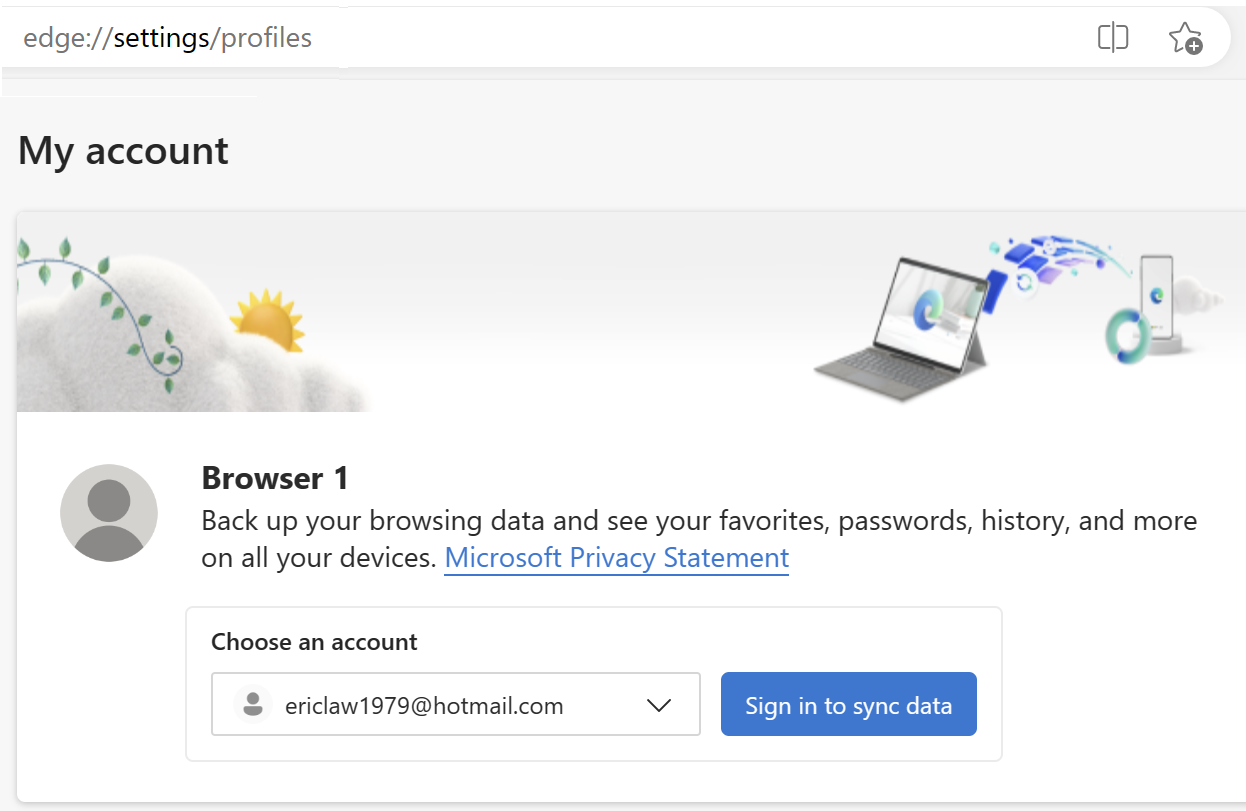
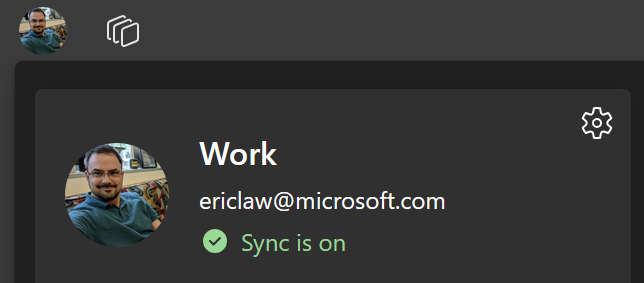
However, what this Clear Site Data command doesn’t do is log you out of the browser itself. If you click the Avatar icon in the Edge toolbar, you’ll see that the profile’s account is still listed and signed in:
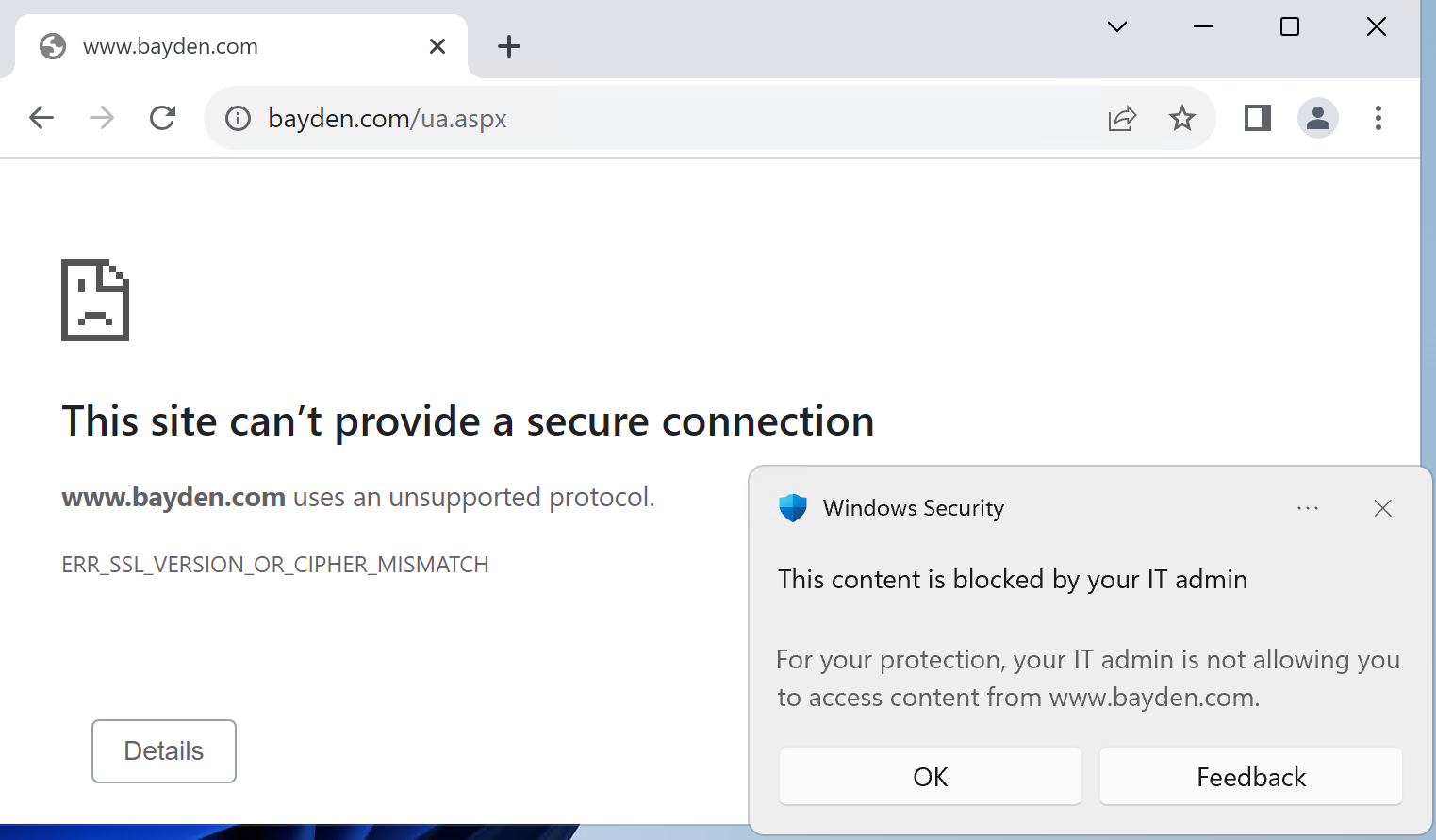
When you next visit https://portal.azure.com, the server says “Hrm, I don’t know who this is, I better get them to log in” … and the browser is redirected to a login page.

You might assume that this page would prompt for your username and password. And that is, in fact, what happens if you launch https://portal.azure.com in a default Chrome or Edge InPrivate browser instance.
But if you’re in a non-Private Edge window logged in with a profile or in a Chrome browser with the Windows 10 Accounts extension installed, that login.microsoftonline.com page doesn’t need to bother the user for a username and password – either the browser (Edge) or the extension (Chrome) just says “Oh, a login page! I know what to do with that – here, have a token!” (Under the hood, the token may be sent to the identity provider via a browser-injected HTTP header, or supplied to the identity provider page’s JavaScript via an extension API.)
Signing in to the browser itself is a relatively new mechanism for enabling “Single Sign On”, a catalog of approaches that have existed in one form or another for decades, including Client Certificate Authentication, Windows Integrated Authentication, and now Browser SSO. The Edge team has a nice documentation page explaining the various SSO features posted here here.
Because the browser/extension supplies the token in lieu of the username / password into the login page, the login page says “Okay, we’re good to go, navigate back to the portal.azure.com page – the user has supplied proof of their identity.”
And thus the “magic” here is pretty simple.
With that said, one factor that can lead to confusion about browser SSO is the fact that browser vendors tend to only support automatic authentication for their own first-party login pages. UPDATE: This changed in Chrome 111. See below.
For example, Microsoft Edge’s SSO automatically logs into web properties like https://portal.azure.com that rely on the Microsoft identity provider, while Google Chrome only enables SSO through the Microsoft logon page if the Chrome Windows 10 account extension is installed.
This “First Party” support isn’t unique to Microsoft. Consider the similar scenario in the “Google universe” version of this scenario”:
- Launch Chrome, using an
@gmail.comprofile. - Visit
mail.google.comand look at your email - Hit
CTRL+Shift+Deleteand use the dialog to Clear Site Data for all time - Close the browser
- Restart the browser
- Visit
mail.google.comand observe: You’re still logged in.
Why? Because you’re logged into Chrome, and it supplies your browser identity token to Google’s website.
Now,
- Launch Edge.
- Visit
mail.google.com, sign in if needed, and look at your email - Hit
CTRL+Shift+Deleteand use the dialog to Clear Site Data for all time - Close the browser
- Restart the browser
- Visit
mail.google.comand observe: You have to log in again.
Why? Because while you’re logged into Edge, Edge doesn’t supply your browser identity token to Google’s website.
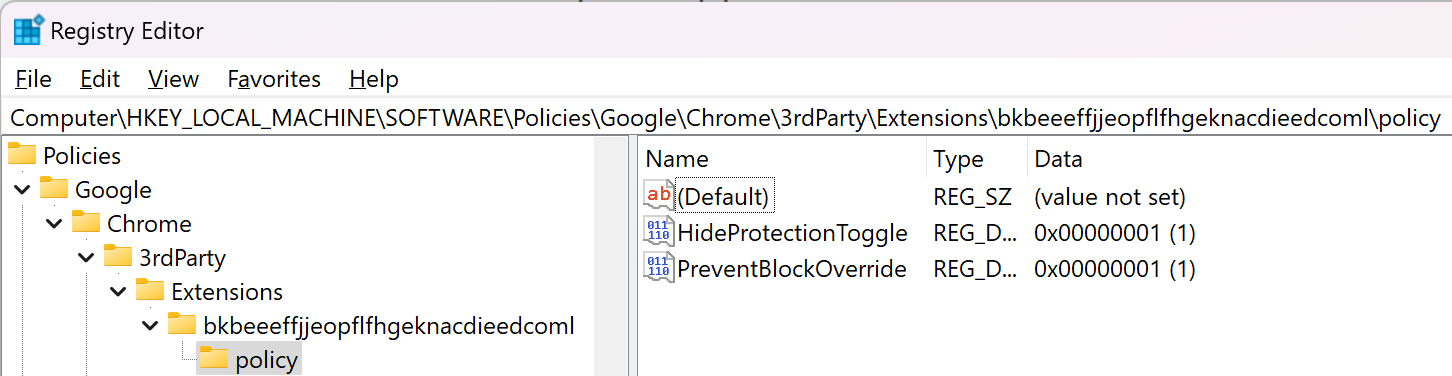
Note: Microsoft Edge does offer policies to control whether users may log into the browser itself, so if you really don’t want your users to be automatically signed in (and allowed to sync settings, history, credentials, etc), setting the policy would be one option.
Chrome CloudAPAuth
Chrome 111 introduced a new feature called CloudAPAuth. When enabled and running on Windows 10+, the browser will automatically add x-ms-DeviceCredential and x-ms-RefreshTokenCredential headers when sending requests to the login.microsoftonline.com authentication portal:

Chromium names this the PlatformAuthenticationProvider. When enabled (and not in Incognito/Guest mode), a navigation throttle adds the appropriate custom headers when navigating to login URLs pulled from the Windows registry:

…or hardcoded if the registry keys aren’t specified.
As an aside, this code flow looks very very similar to the code that the Edge team had built into their browser for the same purpose years ago.
This allows SSO authentication to Microsoft websites in Chrome even without the Windows Accounts browser extension installed. Note that both CloudAPAuth and the Windows Accounts extension go a bit beyond just user authentication — they also provide attestations about the state of the device, which can be targeted by Conditional Access to allow only, say, fully-patched managed PCs to access a sensitive website.
You can learn more about the token here.
Firefox 91+
Firefox offers this same feature: