When some of the hipper PMs on the Internet Explorer team started using a new “microblogging” service called Twitter in the spring of 2007, I just didn’t “get it.” Twitter mostly seemed to be a way to broadcast what you’d had for lunch, and with just 140 characters, you couldn’t even fit much more.
As Twitter’s founder noted:
…we came across the word “twitter”, and it was just perfect. The definition was “a short burst of inconsequential information”, and “chirps from birds”. And that’s exactly what the product was.
https://en.wikipedia.org/wiki/Twitter#2006%E2%80%932007:_Creation_and_initial_reaction
When I finally decided to sign up for the service (mostly to ensure ownership of my @ericlaw handle, in case I ever wanted it), most of my tweets were less than a sentence. I hooked up a SlickRun MagicWord so I could spew status updates out without even opening the website, and spew I did:
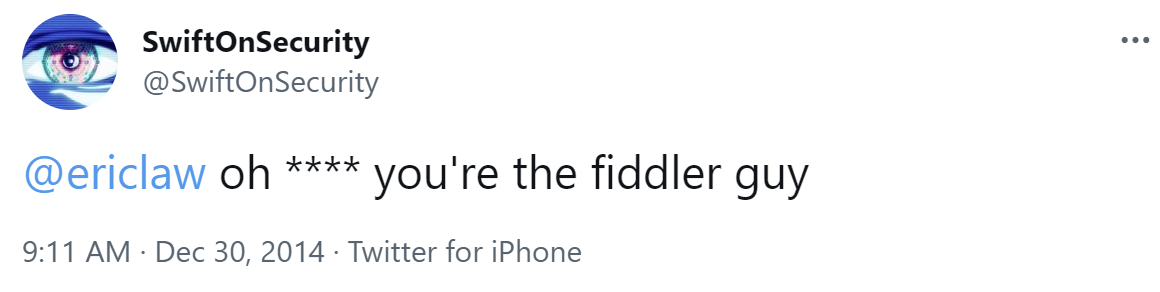
It looks like it was two years before I interacted with anyone I knew on Twitter, but things picked up quickly from there. I soon was interacting with both people I knew in real life, and many many more that I would come to know from the tech community. Between growing fame as the creator of Fiddler, and attention from improbable new celebrities:
…my follower count grew and grew. Soon, I was tweeting constantly, things both throwaway and thoughtful. While Twitter wasn’t a source of deep connection, it was increasingly a mechanism of broad connection: I “knew” people all over via Twitter.
This expanded reach via Twitter came as my connections in the real-world withered away from 2013 to 2015: I’d moved with my wife to Austin, leaving behind all of my friends, and within a few years, Telerik had fired most of my colleagues in Austin. Around that time, one of my internet-famous friends, Steve Souders confessed that he’d unfollowed me because I’d started tweeting too much and it was taking over his timeline.
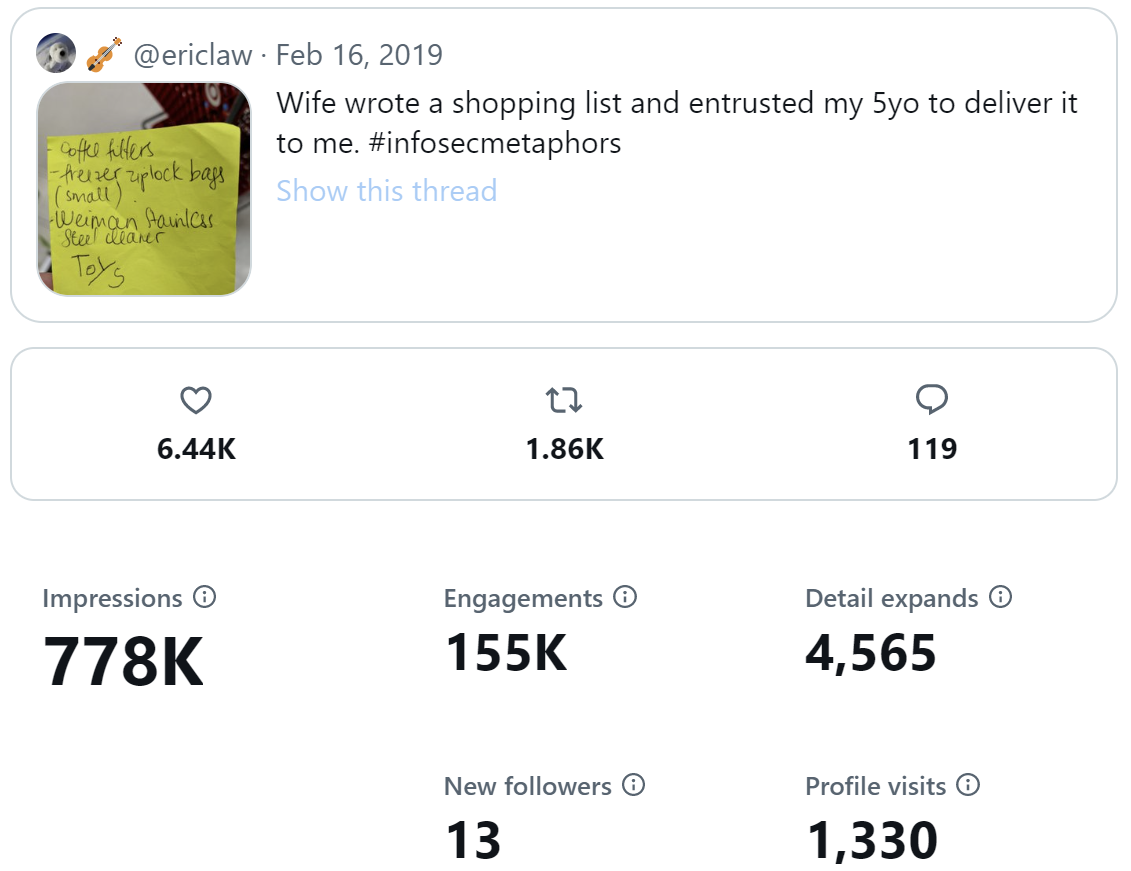
My most popular tweet came in 2019, and it crossed over between my role as a dad and as a security professional:
The tweet, composed from the ziplock bag aisle of Target, netted nearly a million views.
I even found a job at Google via tweet. Throughout, I vague-tweeted various life milestones, from job changes, to buying an engagement ring, to signing the divorce papers. Between separating and divorcing, I wrote up a post-mortem of my marriage, and Twitter got two paragraphs:
Twitter. Unquestionably designed to maximize usage, with all of the cognitive tricks some of the most clever scientists have ever engineered. I could write a whole book about Twitter. The tl;dr is that I used Twitter for all of the above (News, Work, Stock) as well as my primary means of interacting with other people/”friends.” I didn’t often consciously think about how much it messed me up to go from interacting with a large number of people every day (working at Microsoft) to engaging with almost no one in person except [my ex] and the kids. Over seven years, there were days at Telerik, Google, and Microsoft where I didn’t utter a word for nine workday hours at a time. That’s plainly not healthy, and Twitter was one crutch I tried to use to mitigate that.
My Twitter use got worse when it became clear that [my ex] wasn’t especially interested in anything I had to say that wasn’t directly related to either us or the kids, either because our interests didn’t intersect, or because there wasn’t sufficient shared context to share a story in fewer than a few minutes. She’d ask how my day was, and interrupt if my answer was longer than a sentence or two without a big announcement. Eventually, I stopped answering if I couldn’t think of anything I expected she might find interesting. Meanwhile, ten thousand (mostly strangers) on the Internet beckoned with their likes and retweets, questions and kudos.
Now, Twitter wasn’t all just a salve for my crushing loneliness. It was a great and lightweight way to interact with the community, from discovering bugs, to sharing tips-and-tricks, to drawing traffic to blog posts or events. I argued about politics, commiserated with other blue state refugees in Texas, and learned about all sorts of things I likely never would have encountered otherwise.
Alas, Twitter has also given me plenty of opportunities to get in trouble. Over the years, I’ve been pretty open in sharing my opinions about everything, and not everyone I’ve worked for has been comfortable with that, particularly as my follower count crossed into 5 digits. Unfortunately, while the positive outcomes of my tweet community-building are hard to measure, angry PR folks are unambiguous about their negative opinions. Sometimes, it’s probably warranted (I once profanely lamented a feature that I truly believe is bad for safety and civility in the world) while other times it seems to be based on paranoid misunderstandings (e.g. I often tweet about bugs in products, and some folks wish I wouldn’t).
While my bosses have always been very careful not to suggest that I stop tweeting, at some point it becomes an IQ test and they’re surprised to see me failing it.
What’s Next?
While I nagged the Twitter team about annoying bugs that never got fixed over the years, the service was, for the most part, solid. Now, a billionaire has taken over and it’s not clear that Twitter is going to survive in anything approximating its current form. If nothing else, several people who matter a lot to me have left the service in disgust.
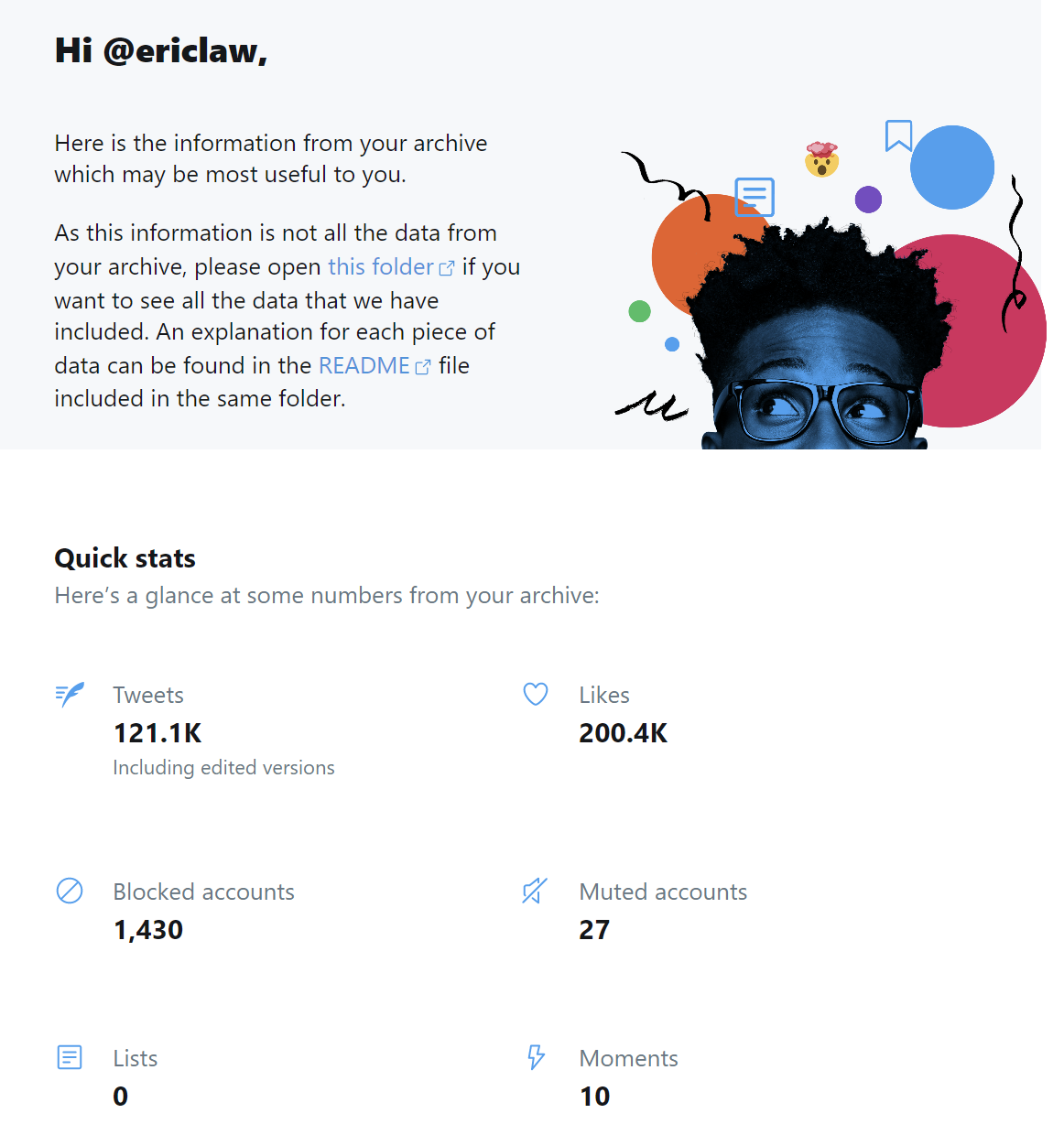
You can download an archive of all of your Tweets using the Twitter Settings UI. It takes a day or two to generate the archive, but after you download the huge ZIP file (3gb in my case), it’s pretty cool. There’s a quick view of your stats, and the ability to click into everything you’ve ever tweeted:
If the default features aren’t enough, the community has also built some useful tools that can do interesting things with your Twitter archive.
I’ve created an alternate account over on the Twitter-like federated service called Mastodon, but I’m not doing much with that account just yet.
Strange times.
-Eric
Update: As of November 2024, I’ve left the Nazi Bar and moved to BlueSky. Hope to see you there!