The Fiddler Web Debugger is now old enough to drink, but I still use it pretty much every day. Fiddler hasn’t aged entirely gracefully as platforms and standards have changed over the decades, but the tool is extensible enough that some of the shortcomings can be fixed by extensions and configuration changes.
Last year, I looked back at a few of the mistakes and wins I had in developing Fiddler, and in this post, I explore how I’ve configured Fiddler to maximize my productivity today.
Powerup with FiddlerScript & Extensions
Add a SingleBrowserMode button to Fiddler’s toolbar
By default, Fiddler registers itself as the system proxy and almost all applications on the system will immediately begin sending their traffic through Fiddler. While this can be useful, it often results in a huge amount of uninteresting “noise”, particularly for web developers hoping to see only browser traffic. Fiddler’s rich filtering system can hide traffic based on myriad criteria, but for performance and robustness reasons, it’s best not to have unwanted traffic going through Fiddler at all.
The easiest way to achieve that is to simply not register as the system proxy and instead just launch a single browser instance whose proxy settings are configured to point at Fiddler’s endpoint.
Adding a button to Fiddler’s toolbar to achieve this requires only a simple block of FiddlerScript:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This button is probably the single most-valuable change I made to my copy of Fiddler in years, and I’m honestly a bit sick that I never thought to include this decades ago.
Disable ZSTD
ZStandard is a very fast lossless compression algorithm that has seen increasing adoption over the last few years, joining deflate/gzip and brotli. Unfortunately, Telerik has not added support for Zstd compression to Fiddler Classic. While it would be possible to plumb support in via an extension, the simpler approach is to simply change outbound requests so that they don’t ask for this format from web servers.
Doing so is simple: just rewrite the Accept-Encoding request header:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Since moving to the Microsoft Defender team, I spend a lot more time looking at malicious files. You can integrate Fiddler into VirusTotal to learn more about any of the binaries it captures.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Beyond looking at hashes, I also spend far more time looking at malicious sites and binaries, many of which embed malicious content in base64 encoding. Fiddler’s TextWizard (Ctrl+E) offers a convenient way to transform Base64’d text back to the original bytes, and the Web Session List’s context menu’s “Copy > Response DataURI” allows you to easily base64 encode any data.
Add the NetLog Importer
If your goal isn’t to modify traffic with Fiddler, it’s often best not to have Fiddler capture browser traffic at all. Instead, direct your Chromium-based browser to log its the traffic into a NetLog.json file which you can later import to Fiddler to analyze using the Fiddler NetLog Importer extension.
There are a zillion other useful little scripts you might add to Fiddler for your own needs. If you look through the last ten years of my GitHub Gists you might find some inspiration.
Adjust Settings
Configure modern TLS settings
Inside Tools > Fiddler Options > HTTPS, make it look like this:
Use Visual Studio Code as the Diff Tool
If you prefer VSCode to Windiff, type about:config in the QuickExec box below the Web Sessions list to open Fiddler’s Preferences editor.
Add/update the fiddler.config.path.differ entry to point to the file path to your VSCode instance.
Set the fiddler.differ.params value to --diff "{0}" "{1}"
Miscellaneous
On the road and don’t have access to Fiddler? You can quickly explore a Fiddler SAZ file using a trivial web-based tool.
Developers can use Fiddler’s frontend as the UI for their own bespoke tools and processes. For example, I didn’t want to build a whole tampering UI for the Native Messaging Meddler, so I instead use Fiddler as the front-end.
The team recently got a false-negative report on the SmartScreen phishing filter complaining that we fail to block firstline-trucking.com. I passed it along to our graders but then took a closer look myself. I figured that maybe the legit site was probably at a very similar domain name, e.g. firstlinetrucking.com or something, but no such site exists.
Curious.
Simple Investigation Techniques
I popped open the Netcraft Extension and immediately noticed a few things. First, the site is a new site. Suspicious, since they claim to have been around since 2002. Next, the site is apparently hosted in the UK, although they brag about being “Strategically located at the U.S.-Canada border.” Sus... and just above that, they supply an address in Texas. Sus.
Let’s take a look at that address in Google Maps. Hmm. A non-descript warehouse with no signage. Sus.
Well, let’s see what else we have. Let’s go to the “About Us” page and see who claims to be employed here. Right-click the CEO’s picture and choose “Copy image link.”
Investigating the other employee photos and customer pictures from the “Customer testimonials” section reveals that most of them are also from stock photo sites. The unfortunately-named “Marry Hoe” has her picture on several other “About us” pages — it looks like she probably came with the template. Her profile page is all Lorem Ipsum placeholder text.
I was surprised that one of the biggest photos on the site didn’t show up in TinEye at all. Then I looked at the Developer Tools and noticed that the secret is revealed by the image’s filename — ai-generated-business-woman-portrait. Ah, that’ll do it.
I tried searching for the phone number atop the site ((956) 253-7799) but there were basically no hits on Google. This is both very sus and very surprising, because often Googling for a phone number will turn up many complaints about scams run from that number.
Moar Scams!
Hmm…. what about all of those blog posts on the site. They’re not all lorem ipsum text. Hrm… but they do reference other companies. Maybe these scammers just lifted the text from some legit company? It seems plausible that “New England Auto Shipping” is probably a legit company they stole this from. Let’s copy this text and paste it into Google:
I didn’t find the source (likely neautoshipping.com, an earlier version of the scam from October 2024), but I did find another live copy of the attack, hosted on a similar domain:
This version is hosted at firstline-vehicle.com with the phone number (908-505-5378) and an address in New Jersey. They’ve literally been copy/pasting their scam around!
Netcraft reports that it’s first seen next month 🙃. Good thing I’ve got my time machine up and running!
The page title of this scam site doesn’t match the scammers though. Hmm… What happens if I look for “Bergen Auto Logistics” then?
Another scam site, bergen-autotrans.com, this one registered this month and CEO’d by a Stock Photo woman:
There are some more interesting photos here, including some that are less obviously faked:
It looks like there was an earlier version of this site in November 2024 at bergenautotrans.com that is now offline:
Searching around, we see that there’s also currently a legit business in New York named “Bergen Auto” whose name and reputation these scammers may have been trying to coast off of. And now some of the pieces are starting to make more sense — Bergen New York is on the US/Canada border.
Searching for the string "Your car does not need be running in order to be shipped" turns up yet more copies of the scam, including britt-trucking.net with phone number (602) 399-7327:
Another random Stock Photo CEO is here, and our same General Manager now has a new name:
…and hey, look, it’s our old friends, now with a different logo on their shirts!
Interestingly, if you zoom in on the photo, you see that the name and logo don’t even match the scam site. The company logo and filename contain Sunni-Transportation, which was also found in the filename of Marry Hoe on the first site we looked at.
The same "Your car does not need be running in order to be shipped" string was also found on two now-offline sites, unitedauto-transport.com, and unitedautotrans.net.
Not a Phish, but definitely Fishy
I went back to our original complainant and asked for clarification — this site doesn’t seem to be pretending to be the site of any other company, but instead appears to be just entirely manufactured from AI and stock photos.
He explained that the attackers troll Craigslist[1] looking for folks buying used cars. They put up some fake listings, and then act as if the (fake) seller has chosen them as an escrow provider. After a bunch of paperwork, the victim buyer wires the attacker thousands of dollars for the nonexistent car. The attackers immediately send a fake tracking number that goes to an order tracking page that’s never updated. They’re abusing people who are risk-averse enough to seek out an escrow company to protect a big transaction, but who not able to validate the bonafides of that “escrow company”… aka, smart humans. (Having bought houses thrice, I can say that validating the legitimacy of an escrow company is a very difficult task). Escrow scams like this one are only one of several popular attacks — this guide and this one describe several scams and how to avoid them.
Unfortunately, creating a fake business almost entirely in pixels is a simple scam, and one that’s not trivial to protect against. In cases where no existing business’ reputation is being abused, there’s no organization that’s particularly incentivized to do the work to get the bad guys taken down. Phishing protection features like SafeBrowsing and SmartScreen are not designed to protect against “business practices scams.”
The very same things that make online businesses so easy to start — low overhead, no real-estate, templates and AIs can do the majority of the work — make it easy to invent fake businesses that only exist in the minds of their victims. After the scammers get found out, the sites disappear and the crooks behind them simply fade away.
Looking through here, most of the sites are dead, but not all. Some have been live for years!
[1] In college, a friend fell victim to a different scam on Craigslist, the overpayment scam. They’d rented a 3 bedroom apartment and needed a 3rd roommate. They were contacted by an “international student” who needed a room and sent my friends a check $500 dollars larger than requested. “Oops, would you mind wiring back that extra? I really need it right now!” the scammer begged. My kind friends wired back the “overpayment” amount, and a few days later were heartbroken to discover that the original check had, of course, not actually cleared. They were out the $500, a huge sum for two broke young college students.
Recently, there’s been a surge in the popularity of trojan clipboard attacks whereby the attacker convinces the user to carry their attack payload across a security boundary and compromise the device.
Meanwhile, AI hype is all the rage. I recent had a bad experience in what I thought was a simple AI task (draw a map with pushpins in certain cities):
The generated map with wildly incorrect city locations
… but I was curious to see what AI would say if I pretended to be the target of a trojan clipboard attack. I was pleased to discover that the two AIs I tried both gave solid security advice for situation:
ChatGPT and Gemini both understood the attack and the risk
A few days later, the term “vibe-coding” crossed my feed and I groaned a bit when I learned what it means… Just describe what you want to the AI and it’ll build your app for you. And yet. That’s kinda exactly how I make a living as a PM: I describe what I want an app to do, and wait for someone else (ideally, our dev team) to build it. I skimmed a few articles about vibe coding and then moved on with my day. I don’t have a lot of time to set up new workflows, install new devtools, subscribe to code-specific AI models, and so forth.
Back to the day job.
Talking to some security researchers looking into the current wave of trojan clipboard attacks, I brainstormed some possible mitigations. We could try to make input surfaces more clear about risk:
… but as I noted in my old blog post, we could be even smarter, detecting when the content of a paste came from a browser (akin to the “Mark of the Web” on downloads) and provide the user with a context specific warning.
In fact, I realized, we don’t even need to change any of the apps. Years ago, I updated SlickRun to flash anytime the system clipboard’s content changes as a simple user-experience improvement. A simple security tool could do the same thing– watch for clipboard changes, see if the content came from the browser, and then warn the user if it was dangerous.
In the old days, I’d’ve probably spent an evening or two building such an app, but life is busier now, and my C++ skills are super rusty.
But… what if I vibe-coded it? Hmm. Would it work, or would it fail as spectacularly as it did on my map task?
Vibe-coding ClipShield
I popped open Google Gemini (Flash 2.0) and told directed it:
> Write me a trivial C++ app that calls AddClipboardFormatListener and on each WMClipboardUpdate call it scans the text on the clipboard for a string of my choice. If it's found, a MessageBox is shown and the clipboard text is cleared.
In about 15 seconds, it had emitted an entire C++ source file. I pasted it into Visual Studio and tried to compile it, expecting a huge pile of mistakes.
Sure enough, VS complained that there was no WinMain function. Gemini had named its function main(). I wonder if it could fix it itself?
> Please change the entry point from main to WinMain
The new code compiled and worked perfectly. Neat! I wonder how well it would do with making bigger changes to the code? Improvements occurred to me in rapid succession:
> To the WM_CLIPBOARDUPDATE code, please also check if the clipboard contains a format named "Chromium internal source URL".
> Update the code so instead of a single searchString we search for any of a set of strings.
> please make the string search case-insensitive
> When blocking, please also emit the clipboard string in the alert, and send it to the debug console via OutputDebugString
In each case, the resulting code was pretty much spot on, although I took the opportunity to tweak some blocks manually for improved performance. Importantly, however, I wasn’t wasting any time on the usual C++ annoyances, string manipulations and conversions, argument passing conventions, et cetera. I was just… vibing.
There was a compiler warning from Visual Studio in the log. I wonder if it could fix that? I just pasted the error in with no further instruction:
> Inconsistent annotation for 'WinMain': this instance has no annotations. See c:\program files (x86)\windows kits\10\include\10.0.26100.0\um\winbase.h(1060).
Gemini explained what the warning meant and exactly how to fix it. Hmm… What else?
> Is there a way to show the message box on a different thread so it does not block further progress?
Gemini refactored the code to show the alert in a different thread. Wait, is that even legal?
> In Windows API, is it legal to call MessageBox on another thread?
Gemini explained the principles around the UI thread and why showing a simple MessageBox was okay.
> Can you use a mutex to ensure single-instance behavior?
Done. I had to shift the code around a bit (I didn’t want errors to be fatal), but it was trivial.
Hmm…. What else. Ooh… What if I actually got real antivirus into the mix? I could call AMSI with the contents of the clipboard to let Defender or the system antivirus scan the content and give a verdict on whether it’s dangerous.
> Can you add code to call AMSI with the text from the clipboard?
It generated the code instantly. Amazing. Oops, it’s not quite right.
> clipboardText.c_str() is a char* but the AmsiScanString function needs an LPCWSTR
Gemini apologized for the error and fixed it. Hmm. Linking failed. This has always been a hassle. I wonder how Gemini will do?
> How do I fix the problem that the link step says "unresolved external symbol AmsiOpenSession"?
Gemini explained the cause of the problem and exactly how to fix it, including every click I needed to perform in Visual Studio. Awesome!
By now, I was just having tons of fun, pair programming a combination of my knowledge with Gemini’s strengths.
> Please hoist a time_point named lastClipboardUpdate to a global variable and update it each time the clipboard contents change.
> Please rewrite GetTimestamp not to use auto
I like to know what my types actually are.
> Please monitor keystrokes for the Win+R hotkey and if pressed and it's within 30 seconds of the clipboard copy, show a warning.
I see that it's using WM_HOTKEY.
> The RegisterHotKey call will not work because Windows uses that hotkey. Instead use a keyboard hook.
Gemini understands and writes the new code. It's a little kludgy, watching for the keydown and up events and setting booleans.
> Rather than watching for the VK_LWIN use GetAsyncKeyState to check if it's down.
Gemini fixes the code.
I’m super-impressed. Would the AI do as good a job for anyone who didn’t already deeply understand the space? Maybe not, and probably not as quickly. But it was nice that I had the chance to feel useful.
On Windows systems, that source of network threat information is commonly called SmartScreen, and support for querying it is integrated directly into the Microsoft Edge browser. Direct integration of SmartScreen into Edge means that the security software can see the full target URL and avoid the loss of fidelity incurred by HTTPS encryption and other browser network-privacy changes.
SmartScreen’s integration with Microsoft Edge is designed to evaluate reputation for top-level and subframe navigation URLs only, and does not inspect sub-resource URLs triggered within a webpage. SmartScreen’s threat intelligence data targets socially-engineered phishing, malware, and techscam sites, and blocking frames is sufficient for this task. Limiting reputation checks to web frames and downloads improves performance.
When an enterprise deploys Microsoft Defender for Endpoint (MDE), they unlock the ability to extend network protections to all processes using a WFP sensor/throttle that watches for connection establishment and then checks the reputation of the IP and hostname of the target site.
For performance reasons (Network Protection applies to connections much more broadly than just browser-based navigations), Network Protection first checks the target information with a frequently-updated bloom filter on the client. Only if there’s a hit against the filter is the online reputation service checked.
In both the Edge SmartScreen case and the Network Protection case, if the online reputation service indicates that the target site is disreputable (phishing, malware, techscam, attacker command-and-control) or unwanted (custom indicators, MDCA, Web Category Filtering), the connection will be blocked.
Debugging Edge SmartScreen
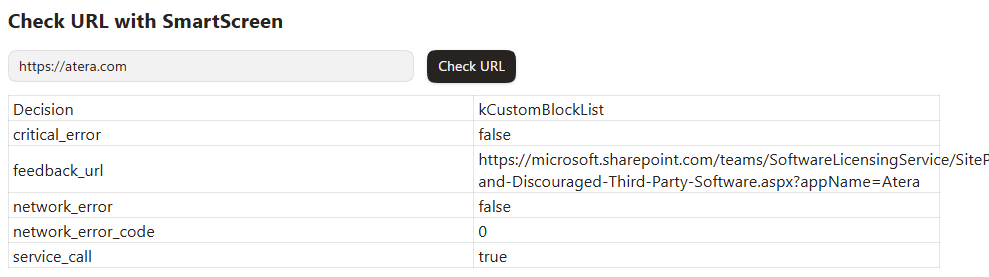
Within Edge, the Security Diagnostics page (edge://security-diagnostics/) offers a bit of information about the current SmartScreen configuration. For example, looking up the URL of a RMM Tool vendor shows that our company blocks it for our devices using a Custom Indicator:
SmartScreen’s reputation checks are sent directly through Edge’s own network stack (just like web traffic) which means you can easily observe the reputation requests simply by starting Fiddler (or you can capture NetLogs) while browsing around.
The service URL to look for will depend upon whether the device is a consumer device or an MDE-onboarded device. Onboarded devices will target a geography-specific hostname– in my case, unitedstates.smartscreen.microsoft.com:
The JSON-formatted communication is quite readable. A request payload describes the in-progress navigation, and the response payload from the service supplies the verdict of the reputation check:
For a device that is onboarded to MDE, the request’s identity\device\enterprise node contains an organizationId and senseId. These identifiers allow the service to go beyond SmartScreen web protection and also block or allow sites based on security admin-configured Custom Indicators, Web Category Filtering, MDCA blocking, etc. The identifiers can be found locally in the Windows registry under HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Advanced Threat Protection.
In the request, the forceServiceDetermination flag indicates whether the client was forced to send a reputation check because the WCF feature is enabled for the device. When Web Category Filtering is enabled, requests must hit the web service even if the target sites are “safe” (e.g. Facebook) because a WCF policy may demand it (e.g. “Block social media”).
If the target site has a negative reputation, the response’s responseCategory value indicates why the site should be blocked.
Verdict for a phishing site
Verdict for a site that delivers malware
The actions\cache node of the response allows the service to instruct the client component to cache a result to bypass subsequent requests. Blocks from SmartScreen in Edge are never cached, while blocks from the Network Protection filter are cached for a short period (to avoid hammering the web service in the event that an arbitrary client app has a retry-forever behavior or the like). To clear SmartScreen’s results cache, you can use browser’s Delete Browsing Data (Ctrl+Shift+Delete); deleting your history will instruct the SmartScreen client to also discard its cache.
Debugging Network Protection
In contrast to the simplicity of capturing Edge reputation checks, the component that performs reputation checks runs in a Windows service account and thus it will not automatically send traffic to Fiddler. To get it to send its traffic to Fiddler, set the WinHTTP Proxy setting from an Admin/Elevated command prompt:
netsh winhttp set proxy 127.0.0.1:8888 "<-loopback>"
(Don’t forget to undo this later using netsh winhttp reset proxy, or various things will fall down after you stop running Fiddler!)
Unlike Network Protection generally, Web Content Filtering applies only to browser processes, so traffic from processes like Fiddler.exe is not blocked. Thus, to debug issues with WCF while watching the traffic from the nissvc.exe process, you can start a browser instance that ignores the system proxy setting like so:
When a page is blocked by Web Category Filtering, you’ll see the following page:
If you examine the response to the webservice call, you see that it’s $type=block with a responseCategory=CustomPolicy:
Block response from unitedstates.smartscreen.microsoft.com/api/browser/edge/navigate/3
Unfortunately, there’s no indication in the response about what category the blocked site belonged to, although you could potentially look it up in the Security portal or get a hint from a 3rd party classification site.
In contrast, when a page is blocked due to a Custom Indicator, the blocking page is subtly different:
Note: If the blocked content is in a subframe rather than a top-level page, the block message will instead be:Your organization blocked this. Contact your IT admin for more info.
If you examine the response to the webservice call, you see that it’s $type=block with a responseCategory=CustomBlockList:
As you can see in the response, there’s an iocId field that indicates whether the block was targeting a DomainName or ipAddress, and specifically which one was matched.
Understanding Edge vs. Other Clients
On Windows, Network Protection’s integration into Windows Filtering Platform gives it the ability to monitor traffic for all browsers on the system. For browsers like Chrome and Firefox, that means it checks all network connections used by a browser both for navigation/downloads and to retrieve in-page resources (scripts, images, videos, etc).
Importantly, however, on Windows, Network Protection’s WFP filter ignores traffic from machine-wide Microsoft Edge browser installations (e.g. all channels except Edge Canary). In Edge, URL blocks are instead implemented using a Edge browser navigation throttle that calls into the SmartScreen web service. That service returns block verdicts for web threats (phishing, malware, techscams), as well as organizational blocks (WCF, Custom Indicators, MDCA) if configured by the enterprise. Today, Edge’s SmartScreen integration performs reputation checks only against navigation (top-level and subframe) URLs only, and does not check the URLs of subresources.
In contrast, on Mac, Network Protection filtering applies to Edge processes as well: blocks caused by SmartScreen threat intelligence are shown in Edge via a blocking page while blocks from Custom Indicators, Web Category Filtering, MDCA blocking, etc manifest as toast notifications.
Block Experience
TLS encryption used in HTTPS prevents the Network Protection client from injecting a meaningful blocking page into Chrome, Firefox, and other browsers. However, even for unencrypted HTTP, the filter just injects a synthetic HTTP/403 response code with no indication that Defender blocked the resource.
Instead, blocks from Network Protection are shown as Windows “Toast” Notifications:
In contrast, SmartScreen’s direct integration into Edge allows for a meaningful error page:
Troubleshooting Network Protection “Misses”
Because Network Protection relies upon network-level observation of traffic, and browsers are increasingly trying to prevent network-level observation of traffic destinations, the most common complaints of “Network Protection is not working” relate to these privacy features. Ensure that browser policies are set to disable QUIC and Encrypted Client Hello.
Ensure that your scenario actually entails a network request being made: URL changes handled by ServiceWorkers and via pushState don’t require hitting the network.
If your scenario is blocked in Edge but some sites are not blocked in Chrome or Firefox, look at a NetLog to determine if H/2 Connection Coalescing is in use or disable Firefox’s network.http.http2.coalesce-hostnames using about:config.
Ensure that Defender Network Protection is enabled and you do not have exclusions that apply to the target process.
Test Pages
A older test page for SmartScreen scenarios can be found here. Note that some of its tests are based on deprecated scenarios and no longer do anything.
After last year’s disappointing showing at the Capitol 10K, I wanted to do better this time around.
We left the house at 6:47; traffic was light and we pulled into my regular parking spot at 7:09. It was a very chilly morning at 42F with a bracing breeze, so I wore my running tights, making sure to Body Glide everywhere to avoid a repeat of the miserable Austin Half chafing. I headed over to the start line and had a productive stop at the porta-potties on the way. The B corral was completely packed by the time I arrived so I had to wait outside of the queue until it drained up to the start line. My Coros watch successfully streamed music to one earbud for the whole race.
Compared to last year, I started out slower: this year, my pace to the 2 mile split was 9:18 while it was 8:58 last year. But this time, I kept running throughout and finished the first 5K 1:26 faster, and finished the overall race 6:33 faster; still 7:17 below my fastest, but under my goal.
I probably should’ve been running a bit faster throughout, but by far the most important factor was that I only dropped to a walk a few times, and usually for only 30 seconds or so. This year, I didn’t recognize the start of the “KQ Hill” (usually there’s an obvious counting cable you run over) so I didn’t run as hard as I might have otherwise. But I ran the whole hill, and the following hills as well.
Over the years, I’ve gotten in the bad habit of dropping to a walk when things seem hard (“Oh, I’ll walk until the next street light“) but I battled that in this race in two ways — by delaying myself by setting the start-target in the distance (“I’ll start walking when I pass the next street light“) and by avoiding excuses by keeping my heart rate under control for the whole race:
Unlike most past races, my pace was more consistent throughout:
All in all, it wasn’t my best performance, but I had fun with it. After the race, I wandered around the post-race expo (which I had entirely overlooked last year, oops) and tried a few non-alcoholic beers– they’d’ve been much more refreshing if it wasn’t in the low 40s and windy.
I’m excited to try to get an even better result in the Sunshine 10K in just 27 more days.