The boys and I went to Maryland for the first half of August to visit family and check out some roller coasters. They hit Kings Dominion, Busch Gardens, Six Flags America (final season), and Hershey Park. We also hiked up Old Rag mountain, visited Tree Trekkers, and rafted the lower-Yough in Ohiopyle State Park.
We also caught the movie Sketch, which I enjoyed more than most of us; it dared to boldly answer the question “What if we made a horror movie for pre-teens”?
A friend we met on the ground at Old Rag. The kids assumed it was a lost Croc JibbitzNate and I waited 2.5 hours for Fahrenheit 451. His verdict? Not even close to being worth it.
Tree Trekkers is always a hit. Nate and I maximized our time on the zip lines.
Of all of our adventures, the rafting trip was the most fun. After a boring Middle-Yough experience last year, this year the boys and I were thrown from the raft shortly after the trip started, and this was followed by an intense storm that dumped on us, with lightning and trees coming down. Around halfway through, the weather cleared up. While the remainder of the expedition was still fun, Noah mused “It was more fun in the storm.”
Beyond the adventures, we played games, ate Grandma’s spaghetti, and Grandpa’s cinnamon rolls and omelets.
I’ve written about security products previously, laying out the framing that security products combine sensors and throttles with threat intelligence to provide protection against threats.
As a product engineer, I spend most of my time thinking about how to improve sensors and throttles to enhance protection, but those components only provide value if the threat intelligence can effectively recognize data from the sensors and tell the throttles to block dangerous actions.
A common goal for the threat intelligence team is to measure the quality of their intel because understanding the current quality is critical to improving it.
Efficacy is the measure of the false negatives (how many threats were missed) and false positives (how many innocuous files or behaviors were incorrectly blocked). Any security product can trivially have a 0% false negative rate (by blocking everything) or a 0% false positive rate (by blocking nothing). The challenge of the threat intelligence is in minimizing both false negatives and false positives.
Unfortunately, if you think about it for a moment the big problem in measuring efficacy leaps to mind: It’s kinda impossible.
Why?
Think about it: It’s like having a kid take a math test, and then asking that kid to immediately go back and grade his own test without first giving him an answer key or teaching him more math. When he wrote down his answers, he did his best to provide the answer he thought was correct. If you immediately ask him again, nothing has changed — he doesn’t have any more information than he had before, so he still thinks all of his answers are correct.
And the true situation is actually much more difficult than that analogy — arithmetic problems don’t try to hide their answers (cloaking), and their answers stay constant over time, whereas many kinds of threat are only “active” for brief slices of time (e.g. a compromised domain serving a phishing attack until it’s cleaned up).
There’s no such thing as an answer key for threat recognition, so what are we to do? Well, there are some obvious approaches for grading TI for false negatives:
Wisdom of the Crowd – Evaluate the entity through all available TI products (e.g. on VirusTotal) and use that to benchmark against the community consensus.
Look back later – Oftentimes threats are not detected immediately, but become are discovered later after broader exposure in the ecosystem. If we keep copies of the evaluated artifacts and evaluate them days or weeks later, we may get a better understanding of false negatives.
Sampling – Laboriously evaluating a small sample of specimens by an expert human grader who, for example, detonates the file, disassembles the code and audits every line to come up with an accurate verdict.
Corpus Analysis – Feed a collection of known-bad files into the engine and see how many it detects.
Each of these strategies is inherently imperfect:
the “Wisdom of the Crowd” only works for threats known to your competitors
“look back later” only works when the threat was ever recognized by anyone and remains active
sampling is extremely expensive, and fails when a threat is inactive (e.g. a command-and-control channel no longer exists)
Corpus analysis only evaluates “known bad” files and often contains files that have been rendered harmless by the passage of time (e.g. attempting to exploit vulnerabilities in software that was patched decades ago).
Even after you pick a strategy, or combination of strategies for grading, you’re still not done. Are you counting false positives/negatives by unique artifacts (e.g. the number of files that are incorrectly blocked or allowed), or by individual encounters (the number of times an incorrect outcome occurs)?
Incorrectly blocking a thousand unique files once each isn’t usually as impactful to the ecosystem as blocking a single file incorrectly a million times.
This matters because of the base rate: the vast majority of files (and behaviors) are non-malicious, while malicious files and behaviors are rare. The base rate means that a FN rate of 1% would be reasonably good for security software, while a FP rate of 1% would be disastrously undeployable.
Finally, it’s important to recognize that false positives and false negatives differ in terms of impact. For example:
A false negative might allow an attacker to take over a device, losing it forever.
A false positive might prevent a user from accomplishing an crucial task, making their device useless to them.
Customers acquire security software with the expectation that it will prevent bad things from happening; blocking a legitimate file or action is “a bad thing.” If the TI false positive rate is significant, users will lose trust in the protection and disable security features or override blocks. It’s very hard to keep selling fire extinguishers when they periodically burst into flame and burn down the building where they’re deployed.
Microsoft Family Safety is a feature of Windows that allows parents to control their children’s access to apps and content in Windows. The feature is tied to the user accounts of the parent(s) and child(ren).
When I visit https://family.microsoft.com and log in with my personal Microsoft Account, I’m presented with the following view:
The “Nate” account is my 9yo’s account. Clicking it reviews a set of tabs which contain options about what parental controls to enable.
Within the Settings link, there’s a simple dialog of options:
Within the tabs of the main page, parents can set an overall screen time limit:
Parents can configure which apps the child may use, how long they may use them:
…and so on. Parents can also lock out a device for the remainder of the day:
On the Edge tab, parents can enable Filter inappropriate websites to apply parental filtering inside the Edge browser.
(Unlike Microsoft Defender for Endpoint’s Web Content Filtering, there are no individual categories to choose from– it’s all-or-nothing).
As with SmartScreen protection, Family Safety filtering is integrated directly into the Microsoft Edge browser. If the user visits a prohibited site, the navigation is blocked and a permission screen is shown instead:
If the parent responds to the request by allowing the site:
…the child may revisit that site in the future.
Blocking Third-Party Browsers
Importantly, Family Safety offers no filtering in third-party browsers (mostly because doing so is very difficult), so enabling Web Filtering will block third party browsers by default.
The blocking of third-party browsers is done in a somewhat unusual way. The Parental Controls Windows service watches as new browser windows appear:
…and if the process backing a window is that of a known browser (e.g. chrome.exe) the process is killed within a few hundred milliseconds (causing its windows to vanish).
After blocking, the child is then (intended to be) presented with the following dialog:
If the child presses “Ask to use”, a request is sent to the Family Safety portal, and the child is shown the same dialog they would see if they tried to use an application longer than a time limit set by the parent:
The parent(s) will receive an email:
…and the portal gives the parent simple options to allow access:
Some Bugs
For a rather long time, there was a bug where Family Safety failed to correctly enforce the block on third party browsers. That bug was fixed in early June and blocking of third party browsers was restored. This led to some panicked posts in forums like Microsoft Support and Reddit complaining that something weird had happened.
In many cases, the problem was relatively mild (“Hey, I didn’t change anything, but now I’m seeing this new permission prompt. What??”) and could be easily fixed by the parent by either turning off Web Filtering or by allowing Chrome to run:
· Disable “Filter inappropriate websites” under the Edge tab, or
· Go to Windows tab → Apps & Games → unblock Chrome.
Note that settings changes will take a minute or so to propagate to the client.
Pretty straightforward.
What’s less straightforward, however, is that there currently exists a second bug: If Activity reporting is disabled on the Windows tab for the child account:
…then the browser window is blown away without showing the permission request prompt:
This is obviously not good, especially in situations where users had been successfully using Chrome for months without any problem.
This issue has been acknowledged by the Family Safety team who will build the fix. For now, parents can workaround the issue by either opting out of web filtering or helping their children use the supported browser instead.
At WWDC 2025, Apple introduced an interesting new API, NEURLFilter, to respond to a key challenge we’ve talked about previously: the inherent conflict between privacy and security when trying to protect users against web threats. That conflict means that security filtering code usually cannot see a browser’s (app’s) fetched URLs to compare them against available threat intelligence and block malicious fetches. By supplying URLs directly to security software (a great idea!), the conflict between security and privacy need not be so stark.
Their presentation about the tech provides a nice explanation of how the API is designed to ensure that the filter can block malicious URLs without visibility into either the URL or where (e.g. IP) the client is coming from.
At a high-level, the design is generally similar to that of Google SafeBrowsing or Defender’s Network Protection — a clientside bloom filter of “known bad” URLs is consulted to see whether the URL being loaded is known bad. If the filter misses, then the fetch is immediately allowed (bloom filters never false positive). If the bloom filter indicates a hit, then a request to an online reputation service is made to get a final verdict.
Privacy Rules
Now, here’s where the details start to vary from other implementations: Apple’s API sends the reputation request to an Oblivious HTTP relay to “hide” the client’s network location from the filtering vendor. Homomorphic encryption is used to perform a “Private Information Retrieval” to determine whether the URL is in the service-side block database without the service actually being able to “see” that URL.
Filtering requests are sent automatically by WebKit and Apple’s native URLSession API. Browsers that are not built on Apple’s HTTPS fetchers can participate by calling an explicit API:
Neat, right? Well, yes, it’s very cool.
Is it perfect for use in every product? No.
Limitations
Inherent in the system design is the fact that Apple has baked its security/privacy tradeoffs into the design without allowing overrides. Here are some limitations that may cause filtering vendors trouble:
Reputation checks can no longer discover new URLs that might represent unblocked threats, or use lookups to prioritize security rescans for high-volume URLs.
There does not seem to be any mechanism to control which components of a URL are evaluated, such that things like rollups can be controlled.
Reputation services cannot have rules that evaluate only certain portions of a URL (e.g. if an campaign is run across many domains with a specific pattern in the path or query).
There does not appear to be any mechanism to submit additional contextual information (e.g. redirect URLs, IP addresses) nor any way to programmatically weight it on the service side (to provide resiliency against cloaking).
There does not appear to be any mechanism which would allow for non-Internet operation (e.g. within a sovereign cloud), or to ensure that reputation traffic flows through only a specific geography.
There’s no mechanism for the service to return a non-binary verdict (e.g. “Warn and allow override” or “Run aggressive client heuristics”).
When a block occurs in an Apple client, there is no mechanism to allow the extension to participate in a feedback experience (e.g. “Report false positive to service”).
There’s no apparent mechanism to determine which client device has performed a reputation check (allowing a Security Operations Center to investigate any potential compromise).
The fastest-allowed Bloom filter update latency is 45 minutes.
Apple’s position is that “Privacy is a fundamental human right” which is an absolutely noble position to hold. However, the counterpoint is that the most fundamental violation of a computer user’s privacy occurs upon phishing theft of their passwords or deployment of malware that steals their local files. Engineering is all about tradeoffs, and in this API, Apple controls the tradeoffs.
Verdict?
Do the limitations above mean that Apple’s API is “bad”? Absolutely not. It’s a brilliantly-designed, powerful privacy-preserving API for a great many use-cases. If I were installing, say, Parental Controls software on my child’s Mac, it’s absolutely the API that I would want to see used by the vendor.
Since the first days of the web, users and administrators have sought to control the flow of information from the Internet to the local device. There are many different ways to implement internet filters, and numerous goals that organizations may want to achieve:
blocking responses based on the category of content a site serves.
Today’s post explores the last of these: blocking content based on category.
The Customer Goal
The customer goal is generally a straightforward one: Put the administrator in control of what sorts of content may be downloaded and viewed on a device. This is often intended as an enforcement mechanism for an organization’s Acceptable Use Policy (AUP).
An AUP often defines what sorts of content a user is permitted to interact with. For example, a school may forbid students from viewing pornography and any sites related to alcohol, tobacco, gambling, firearms, hacking, or other criminal activity. Similarly, a company may want to forbid their employees from spending time on data and social media sites, or from using legitimate-but-unsanctioned tools for sharing files, conducting meetings, or interacting with artificial intelligence.
Mundane Impossibility
The simplicity of the goal belies the impossibility of achieving it. On today’s web, category filtering is inherently impossible to perfect for several reasons:
There are an infinite number of categories for content (and no true standard taxonomy).
Decisions of a site’s category are inherently subjective.
Many sites host content across multiple categories, and some sites host content from almost every category.
Self-labelling schemes like ICRA and PICS (Platform for Internet Content Selection), whereby a site can declare its own category, have all failed to be adopted.
As an engineer, while it would be nice to work on only tractable problems, in life there are many intractable problems for which customers are willing to buy imperfect best-effort solutions.
Web content categorization is one of these, and because sites and categories change constantly, it’s typically the case that content filtering is sold on a subscription basis rather than as a one-time charge. Most of today’s companies love recurring revenue streams.
So, given that customers have a need, and software can help, how do we achieve that?
Filtering Approaches
The first challenge is figuring out how and where to block content. There are many approaches; Microsoft’s various Web Content Filtering products and features demonstrate three of them:
Each implementation approach has its plusses and minuses, from:
Supported browsers: does it work in any browser? Only a small list? Only a specific one?
Performance: Does it slow down browsing? Because the product may categorize billions of URLs, it’s usually not possible to store the map on the client device.
User-experience: What kind of block notice can be shown? Does it appear in context?
Capabilities: Does it block only on navigating a frame (e.g. HTML), or can it block any sub-resources (images, videos, downloads, etc)? Are blocks targeted to the current user, or to the entire device?
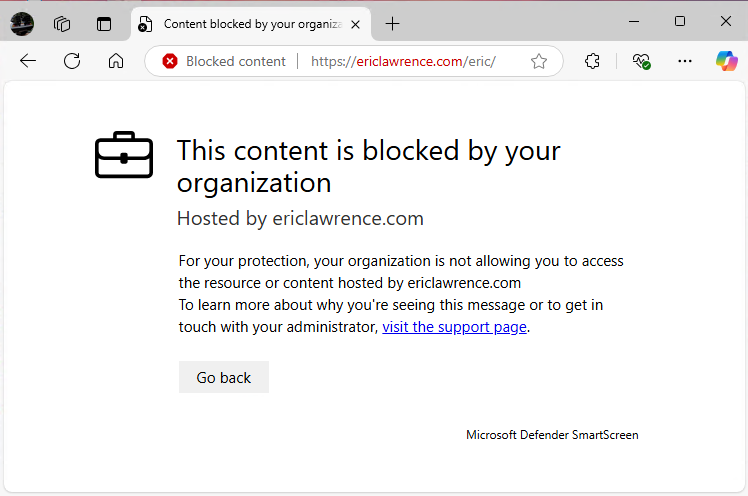
Microsoft Defender Web Content Filtering block page shown in Microsoft Edge
Categorization
After choosing a filtering approach, the developer must then choose a source of categorization information. Companies that are already constantly crawling and monitoring the web (e.g. to build search engines like Bing or Google) might perform categorization themselves, but most vendors acquire data from a classification vendor like NetStar or Cyren that specializes in categorization.
Exposing the classification vendor’s entire taxonomy might be problematic though– if you bind your product offering too tightly to a 3rd-party classification, any taxonomy changes made by the classification vendor could become a breaking change for your product and its customers. So, it’s tempting to go the other way, and ask your customers what categories they expect, then map any of the classification vendor’s taxonomy onto the customer-visible categories.
This is the approach taken by Microsoft Defender WCF, for example, but it can lead to surprises. For example, Defender WCF classifies archive.org in the Illegal Software category, because that’s where our data vendor’s Remote Proxies category is mapped. But to the browser user, that opaque choice might be very confusing — while archive.org almost certainly contains illegal content (it’s effectively a time-delayed proxy for the entire web), that is not the category a normal person would first think of when asked about the site.
Ultimately, an enterprise that implements Web Content Filtering must expect that there will be categorizations with which they disagree, or sites whose categories they agree with but wish to allow anyway (e.g. because they run ads on a particular social networking site, for instance). Administrators should define a process by which users can request exemptions or reclassifications, and then the admins evaluate whether the request is reasonable. Within Defender, an ALLOW Custom Network indicator will override any WCF category blocks of a site.
Aside: Performance
If your categorization approach requires making a web-service request to look up a content category, you typically want to do so in parallel with the request for the content to improve performance. However, what happens if the resource comes back before the category information?
Showing the to-be-blocked content (e.g. a pornographic website) for even a few seconds might be unacceptable. To address that concern for Defender’s WCF, Edge currently offers the following flag on the about:flags page:
Aside: Sub-resources
It’s natural to assume that checking the category of all sub-resources would be superior to only checking the category of page/frame navigations: after all, it’s easy to imagine circumventing, say, an adult content filter by putting up a simple webpage at some innocuous location with a ton of <video> elements that point directly to pornographic video content. A filter that blocks only top-level navigations will not block the videos.
However, the opposite problem can also occur. For example, an IT department recently tried to block a wide swath of Generative AI sites to ensure that company data was not shared with an unapproved vendor. However, the company also outsourced fulfillment of its benefits program to an approved 3rd party vendor. That Benefits website relied upon a Help Chat Bot powered by a company that had recently pivoted into generative AI. Employees visiting the Benefits website were now seeing block notifications from Web Content Filtering due to the .js file backing the Help Chat Bot. Employees were naturally confused — they were using the site that HR told them to use, and got block notifications suggesting that they shouldn’t be using AI. Oops.
Aside: New Sites
Generally, web content filtering is not considered a security feature, even if it potentially reduces an organization’s attack surface by reducing the number of sites a user may visit. Of particular interest is a New Sites category — if an organization blocks users from accessing all sites that are newer than, say, 30 days, and which have not yet been categorized into another category, not only do they reduce the chance of a new site evading a block policy (e.g. a new pornographic site that hasn’t yet been classified by the vendor), this also provides a form of protection from a spear-phishing attack.
Unfortunately, providing a robust implementation of a New Sites category isn’t as easy as it sounds: for a data vendor to classify a site, they have to know its domain name exists. Depending upon the vendors data collection practices, that discovery might take quite a bit of time. That’s because of how the Internet is designed: there’s no “announcement” when a new domain goes online. Instead, a DNS server simply gets a new record binding the site’s hostname to its hosting IP address, and that new record is returned only if a client asks for it.
Simply treating all unclassified sites as “new” has its own problems (what if the site is on a company’s intranet and the data vendor will never be able to access it?). Instead, vendors might learn about new sites by monitoring Certificate Transparency logs, crawling web content that links to the new domain, watching DNS resolutions from broadly deployed client monitoring software (“Passive DNS”), or by integrating with browsers (e.g. as a browser extension) to discover new sites as users navigate to them. After a domain is discovered, the vendor can attempt to load it and use its classification engine to determine the categories to which the site should belong.
-Eric
PS: Over on BlueSky, Nathan McNulty compares Defender WCF’s list of categories with GSA’s list.