After last year’s disappointing showing at the Capitol 10K, I wanted to do better this time around.
We left the house at 6:47; traffic was light and we pulled into my regular parking spot at 7:09. It was a very chilly morning at 42F with a bracing breeze, so I wore my running tights, making sure to Body Glide everywhere to avoid a repeat of the miserable Austin Half chafing. I headed over to the start line and had a productive stop at the porta-potties on the way. The B corral was completely packed by the time I arrived so I had to wait outside of the queue until it drained up to the start line. My Coros watch successfully streamed music to one earbud for the whole race.
Compared to last year, I started out slower: this year, my pace to the 2 mile split was 9:18 while it was 8:58 last year. But this time, I kept running throughout and finished the first 5K 1:26 faster, and finished the overall race 6:33 faster; still 7:17 below my fastest, but under my goal.
I probably should’ve been running a bit faster throughout, but by far the most important factor was that I only dropped to a walk a few times, and usually for only 30 seconds or so. This year, I didn’t recognize the start of the “KQ Hill” (usually there’s an obvious counting cable you run over) so I didn’t run as hard as I might have otherwise. But I ran the whole hill, and the following hills as well.
Over the years, I’ve gotten in the bad habit of dropping to a walk when things seem hard (“Oh, I’ll walk until the next street light“) but I battled that in this race in two ways — by delaying myself by setting the start-target in the distance (“I’ll start walking when I pass the next street light“) and by avoiding excuses by keeping my heart rate under control for the whole race:
Unlike most past races, my pace was more consistent throughout:
All in all, it wasn’t my best performance, but I had fun with it. After the race, I wandered around the post-race expo (which I had entirely overlooked last year, oops) and tried a few non-alcoholic beers– they’d’ve been much more refreshing if it wasn’t in the low 40s and windy.
I’m excited to try to get an even better result in the Sunshine 10K in just 27 more days.
September 2025 tl;dr: You probably should not touch Exploit Protection settings. This post explains what the feature does and how it works, but admins and end-users should probably just leave it alone to do what it does by default.
Over the last several decades, the Windows team has added a stream of additional security mitigation features to the platform to help application developers harden their applications against exploit. I commonly referred to these mitigations as the Alphabet Soup mitigations because each was often named by an acronym, DEP/NX, ASLR, SEHOP, CFG, etc. The vast majority of these mitigations were designed to help shield applications with memory-safety vulnerabilities, helping prevent an attacker from turning a crash into reliable malicious code execution.
By default, most of these mitigations were off-by-default for application compatibility reasons– Windows has always worked very hard to ensure that each new version is compatible with the broad universe of software, and enabling a security mitigation by default could unexpectedly break some application and prevent users from having a good experience in a new version of Windows.
There were some exceptions; for instance, some mitigations were enabled by default for 64-bit applications because the very existence of a 64-bit app during the mid-200Xs was an existence proof that the application was being maintained.
In one case, Windows offered the user an explicit switch to turn on a mitigation (DEP/NX) for all processes, regardless of whether they opted-in:
But, generally, application developers were required to opt-in to new mitigations by setting compiler/linker flags, registry keys, or by calling the SetProcessMitigationPolicy API. One key task for product security engineers in each product cycle was to research the new mitigations available in Windows and opt the new version of their product (e.g. IE, Outlook, Word, etc) into the newest mitigations.
The requirement that developers themselves opt-in was frustrating to some security architects though– what if there was some older app that was no longer maintained but that could be protected by one of these new mitigations?
In response, EMET (Enhanced Mitigation Experience Toolkit) was born. This standalone application provided a user-friendly experience to enabling mitigations for an app; under the covers, it twiddled the bits in the registry for the process name.
EMET was useful, but it exposed the tradeoff to security architects: They could opt a process into new mitigations, but ran the risk of causing the app to break entirely, or only in certain scenarios. They would have to extensively test each application and mitigation to ensure compatibility across the scenarios they cared about.
EMET 5.52 went out of support way back in 2018, but had since been replaced by the Exploit Protection node in the Windows Security App. Exploit Protection offered a very similar user-experience to EMET, allowing the user to specify protections on a per-app basis as well as across all apps.
If you dig into the settings, you can see the available options:
You can also see the settings on a “per-program” basis:
…including the settings put into the registry by application installers and the like.
IFEO Registry screenshot showing the “Mandatory ASLR” bit set for msfeedssync.exe
While built into Windows, Exploit Protection also works with Microsoft Defender for Endpoint (MDE), enabling security admins to easily deploy rules across their entire tenant. Some rules offer an “Audit mode”, which would allow a security admin to check whether a given rule is likely to be compatible with their “real-world” deployment before being deployed in enforcement mode.
Beyond the Windows UI and MDE, mitigations can also be deployed via a PowerShell module; often, you’ll use the Export link on a machine that’s configured the way you like and then import that XML to your other desktops.
Notably, the Set-ProcessMitigation command should be run as an admin (since it needs to touch systemwide registry keys, and silently ignores Access Denied errors). If you choose to import an XML configuration file, the importer’s parser is extremely liberal (ignoring, for instance, whether the document is well-formed) and simply walks the document looking for AppConfig nodes that specify configuration settings per app.
The Big Challenge
The big challenge with Exploit Protection (and EMET before it) is that, if these mitigations were safe to apply by default, we would have done so. Any of these mitigations could conceivably break an application in a spectacular (or nearly invisible) way.
Exploit Mitigations like “Bottom Up ASLR” are opt-in because they can cause compatibility issues with applications that make assumptions about memory layout. Opting an application into a mitigation can cause the application to crash at startup, or later, at runtime, when the application’s (now incorrect) assumption causes a memory access error. Crashes could occur every time, or randomly.
When a mitigation is hit, you might see an explicit “block” event in the Event Log or Defender Portal events, or you might not. That’s because in some cases, a mitigation doesn’t mean the operation is just blocked, instead Windows terminates it. You might look to see whether Watson has captured a crash of the application as it starts, but typically debugging these sorts of things entails starting the target application under a debugger and stepping through its execution until a failure occurs. That is rarely practical for anyone other than the developers of the application (who have its private symbols and source code). If excluding an application from a mitigation doesn’t work, it may be the case that the executable launches some other executable that also needs an exclusion. You might try collecting a Process Monitor log to see whether that’s the case.
Other Problems…
Beyond the problem that turning on additional mitigations could break your applications in surprising and unusual ways, mitigations are also settable by both admins and developers, but there’s no good way to “reset” your settings if you make a mistake or change your mind. Various PowerShell scripts are available to wipe all of the EP settings from the registry, but doing so will wipe out not only the EP settings you set, but also any IFEO (Image File Execution Options) registry settings set by an application’s own developers, leaving you less secure than when you started.
Developer Best Practices
In the ideal case, developers will themselves opt-in (and verify) all available security mitigations for their apps, ensuring that they do not effectively “offload” the configuration and verification process to their customers.
With the increasing focus on security across the software ecosystem, we see that best practice followed by most major application developers, particularly in the places where it’s most useful (browsers and internet clients). Browser developers in particular tend to go far beyond the “alphabet soup” mitigations and also design their products with careful sandboxing such that, even if remote code execution is achieved, it is confined to a tight sandbox to protect the rest of the system.
Last November, I wrote a post about the basics of security software. In that post, I laid out how security software is composed of sensors and throttles controlled by threat intelligence. In today’s post, we’ll look at the Windows Filtering Platform, a fundamental platform technology introduced in Windows Vista that provides the core sensor and throttle platform upon which several important security features in Windows are built.
What is the Windows Filtering Platform?
The Windows Filtering Platform (WFP) is a set of technologies that enable software to observe and optionally block messages. In most uses, WFP is used to block network messages, but it can also block local RPC messages.
For networking and RPC scenarios, performance is critical, so a consumer of WFP specifies a filter that describes the messages it is interested in, and the platform will only call the consumer when a message that matches the filter is encountered. Filtering ensures that processing is minimized for messages that are not of interest to the consumer.
When a message matching the filter is encountered, it is sent to the consumer which can examine the content of the message and either allow it to pass unmodified, or it can change the content or indicate that WFP should drop the message.
This sensor and throttle architecture empowers several critical security features in Windows.
Windows Firewall
Most prominently, WFP is the technology underneath the Windows Firewall (formally, “Windows Defender Firewall with Advanced Security” despite the feature having little to do with Defender). The Firewall controls whether processes may establish outbound connections or receive inbound traffic using a flexible set of rules. The Firewall settings (wf.msc) allows the user to specify these rules that are then enforced using the Windows Filtering Platform.
…and when a process tries to bind a port to allow inbound traffic, a UI prompt is shown:
For the most part, however, the Windows Firewall operates silently and does not show much in the way of UI. In contrast, the Malware Bytes Windows Firewall Control app provides a much more feature-rich control panel for the Windows Firewall.
One major limitation of the Windows Firewall that existed for almost two decades is it natively only supports rules that target IP addresses. Many websites periodically rotate between IPs for operational, load-balancing, geographic CDNs, etc, and many products are unwilling to commit to a fixed set of IP addresses forever. Thus, the inability to create firewall rules that use DNS names (e.g. “Always permit traffic to VirusTotal.com“) was a significant limitation.
This limitation was later mitigated with a new feature called Dynamic Keywords. Dynamic keywords allow you to specify a target DNS name in a firewall rule. Windows Defender’s Network Protection feature will subsequently watch for any unencrypted DNS lookups of the specified DNS name. When Network Protection observes a resolution for a targeted DNS name, it will send a message to the firewall service directing it to update the rule with the IP address returned from DNS. (Note: This scheme is imperfect in several dimensions: for example, asynchrony means that the firewall rule may be updated milliseconds after the DNS resolution, such that the first attempt to connect to an allowed hostname could be blocked.)
Zero Trust DNS (ZTDNS)
More recently, the Windows team has been building a feature called “Zero Trust DNS” whereby a system can be configured to perform all DNS resolutions through a secure DNS resolver, and any connections to any network address that was not returned in a response from that resolver are blocked by WFP.
In this configuration, your organization’s DNS server becomes the network security control point: if your DNS server returns an address for a hostname, your clients can connect to that address, but if DNS refuses to resolve the hostname (returning no address), the network connection is blocked. (An app that is hardcoded to talk to a particular IP address would find its requests blocked, since no DNS request “unlocked” access to that address). The ZeroTrustDNS feature is obviously only suitable for certain operational environments due to its compatibility impact.
AppContainer
Windows 8 introduced a new application isolation technology called AppContainer that aimed to improve security by isolating “modern applications” from one another and the rest of the system. AppContainers are configured with a set of permissions, and the network permission set permits restricting an app to public or private network access.
James Forshaw from Google’s Project Zero wrote an amazing blog post about how AppContainer’s network isolation works. The post includes a huge amount of low-level detail about the implementation of both WFP and the Windows Firewall.
Restricted Network Access
Years before the advent of AppContainers, Windows included a similar feature to block network traffic from Windows Services. Like the AppContainer controls, it was implemented in WFP below/before the Windows Firewall feature, although like AppContainer’s controls, it was implemented in the service named Firewall.
Windows Service Hardening enables restrictions developers can set on a service’s network access. Network access restrictions for Services
are evaluated before the Windows Firewall rules
are enforced regardless of whether Windows Firewall is enabled
are defined programmatically using the INetFwServiceRestriction and INetFwRule APIs.
Windows Vista and later include a set of predefined network access restrictions for built-in services. Service network access restrictions are stored in the HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\SharedAccess\Parameters\FirewallPolicy\RestrictedServices\ registry key. The predefined restrictions are stored in the Static\System key, and custom restrictions are stored in the Configurable key.
A one-off protection built atop WFP is the Port Scanning Prevention filter, described here. The article also briefly mentions the use of Event Tracing for Windows (ETW) Logging in the WFP.
RPC Filtering
The Windows Filtering Platform is not limited to Network messages; it can also be used to filter RPC messages between processes.
I only learned about MDE’s use of RPC Filtering recently. In 2024, Microsoft Employees were briefly unable to play Netflix or other DRM’d video in the Microsoft Edge browser. The root cause turned out to be Defender’s Disruption RPC filter blocking messages from the PlayReady DRM sandboxed process causing the failure during playback.
Microsoft Defender Network Protection
Network Protection (NP) is composed of a WFP driver (wdNisDrv.sys) and a service (NisSrv.exe). It has the ability to synchronously block TCP traffic based on IP and URI reputation, relying on threat intelligence from the SmartScreen webservice and signatures authored by the Defender team. While SmartScreen is integrated directly by Microsoft Edge, NP can extend SmartScreen’s anti-phishing/anti-malware protection to other clients like Chrome and Firefox.
Unfortunately, the use of TLS causes user-experience problems for the blocking of unwanted content. When Network Protection determines that it must block a HTTPS site, it cannot return an error page to the browser because TLS prevents the injection of content on the secure channel. So, NP instead injects a “Handshake Failure” TLS Fatal Alert into the bytestream to the client and drops the connection. The client browser, unaware that the fatal alert was injected by Network Protection, concludes that the server does not properly support TLS, so it shows an error page complaining of the same.
If the system’s Notifications feature is enabled, a notification toast appears with the hope that you’ll see it and understand what’s happened.
Chromium-based browsers show ERR_SSL_VERSION_OR_CIPHER_MISMATCH when the TLS handshake is interruptedMozilla Firefox shows SSL_ERROR_NO_CYPHER_OVERLAP when the TLS handshake is interrupted
Beyond blocking unwanted connections, Network Protection provides network-related signals to the Defender engine, enabling behavior monitoring signatures to target suspicious network connections. By way of example, by generating a JA3/JA3S/JA4 signature of a HTTPS handshake’s fields and comparing it to known-suspicious scenarios, security software can detect a malicious process communicating with its Command and Control servers, even when the traffic is encrypted and the process is not yet known to be malicious.
Microsoft Defender for Endpoint EDR
MDE’s EDR feature also includes MsSecWfp, a driver aimed at filtering network connections based on rules. It is leveraged on network isolation scenarios when a configuration for the machine is passed to this driver for enforcement. This driver produces audit events in the form of ETW events and it does not perform deep traffic inspection.
When EPP is enabled, a WFP callout in WTD.sys watches for the Server Name Indicator extension in TLS Client Hello messages so that it can understand which hosts a process has established network connections with. If a user subsequently types their domain password, the Web Threat Defense service checks the reputation of the established connections to attempt to determine whether the process is connected to a known phishing site.
And More…
Importantly, WFP isn’t used just by Microsoft — many third party security products are also implemented using the Windows Filtering Platform. Security applications that integrate with the Windows Security Center are required (by policy) to be built upon WFP.
While WFP is a core platform technology used by many products, it’s not the only one available. For example, beyond its use of WFP in Network Protection, Microsoft Defender for Endpoint also includes a Network Detection and Response (NDR) feature.
NDR is composed of a service which listens to ETW notifications generated by Pktmon and WinSock, performing async packet analysis using Zeek, an open-source network monitoring platform. Network data is captured at a layer below/before WFP, using PktMon. Compared to WFP, PktMon enables capture of lower-level network data, useful for watching for attempts to exploit bugs in Windows’ network stack itself (e.g. 2021, 2024).
Finally, some network security solutions are based on network traffic routing (e.g. proxies), optionally with decryption via MitM. Microsoft Entra’s Global Secure Access is a newer offering in this category, but there are many vendors offering solutions in this category.
Limitations & Future Directions
Perhaps the most important limitation of network-level monitoring is that the increasingly ubiquitous use of encryption (HTTPS/TLS) means that request and response payloads are usually indecipherable at the network level.
In the “good old days” of network security, a security product could observe all DNS resolution and examine the full content of requests and responses. Nowadays, DNS traffic is increasingly encrypted, and HTTPS prevents network-level monitoring from observing URLs, requests (headers and body) and responses (headers and bodies). For years, security software could still observe the target hostname by sniffing the SNI out of ClientHello messages, but the ongoing deployment of Encrypted Client Hello means that even this signal is disappearing:
Beyond ECH, a growing fraction of traffic takes place over HTTP3/QUIC which doesn’t use TCP at all. QUIC’s use of “initial encryption” precludes trivial determination of the server’s name.
Some security solutions attempt to inject their code into clients or otherwise obtain HTTPS decryption keys, but these approaches tend to be unreliable or offer poor performance.
It seems likely that in the future, the security industry will need to work with application developers to ensure that their software integrates with network security checks directly (as they already do elsewhere) instead of trying to sniff out the destination of traffic at the network level.
Telerik developers recently changed Fiddler to validate the signature on extension assemblies before they load. If the assembly is unsigned, the user is presented with the following message:
However, it’s important to understand the threat model and tradeoffs here.
Validating signatures every time a file is loaded takes time and slows the startup of the app. That’s particularly true if online certificate revocation checking is performed. The performance impact is one reason why most of my applications have a manifest that indicates that .NET shouldn’t bother:
<configuration>
<runtime>
<generatePublisherEvidence enabled="false"/>
</runtime>
</configuration>
Signing your installers is critical to help protect them at rest on your servers and streamline the security checks that happen on download and install. Signing the binaries within can be essential in case the user has Smart App Control enabled, and other security software (e.g. Firewall rules that target publisher signatures) may benefit as well.
However, having your app itself check signatures of its own local files is less useful than you might expect for most applications. The problem is that there’s usually no trust boundary that would preclude an attacker from, for instance, tampering with your app’s code to remove the signature check. In most cases, the attacker could simply modify fiddler.exe to remove the new signature checking code, such that the protection is removed. Similarly, they could likely execute a .DLL hijacking attack to get their code loaded without any signature check at all. Or they could use their own process to inject code into the victim’s address space at runtime. It’s a long list.
In Telerik’s case, tampering to evade signature checking is even simpler. If the user elects to “Always allow” an unsigned extension, that decision is stored as a base64 encoded string in a simple Fiddler preference:
You can use Fiddler’s TextWizard to decode the preference value from about:config
An attacker with sufficient permission to write a .DLL to a place that Fiddler will load it would also have sufficient permission to edit the registry keys where this preference is stored.
Finally, Fiddler’s signature check doesn’t tell the user who signed the file, such that all signatures that chain to any CA are silently allowed. Now, this isn’t entirely worthless– CAs cannot prevent a certificate from being used to sign malware, but in theory a certificate found to do so will eventually get revoked.
If you plan to check code signatures in your application, carefully consider the threat model and ensure that you understand the limits to the protection. And remember that sometimes, “code” may be stored in a type of file that does not natively support signing, as in the case of Fiddler’s script or certain Chromium files.
-Eric
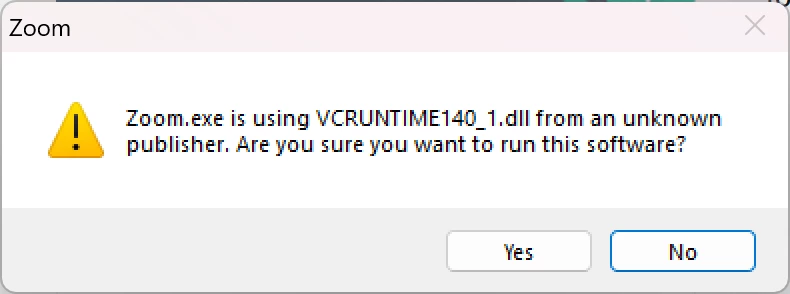
PS: Fiddler isn’t the only software to check its own modules’ signatures; Zoom also does so:
Spring break is one of the best times to be in Texas. The weather’s usually nice, and outdoor fun things to do aren’t miserably hot. This year, the kids are obsessed with roller coasters, so we bought Season Passes to Six Flags (which also includes a variety of other theme parks and water parks). Thus far, we’ve spent two days at Six Flags in San Antonio, and two days at Six Flags in Dallas.
The excellent “Dr. Diabolical” drop at Six Flags. The kids are in the back row. We all rode it a dozen times.
The kids spent the actual days of spring break on an adventure trip with their mom to Costa Rica:
While they were out of town, I took a quick four day cruise out of Galveston on the Mariner of the Seas.
To keep costs down, this time I took a Deck 7 “interior view” cabin that overlooked the Promenade:
… but I didn’t spend much time in the room. I spent a lot of time at shows, walking the top deck, enjoying music (“Ed”, a Brazilian singer/guitarist) in the pub, and generally relaxing. I passed some time reading Ken Williams’ history of Sierra On-line, a pleasant and nostalgic read that made little impression on me. The weather was imperfect (very windy with intermittent drizzles) but it was quite nice overall.
Most importantly, I achieved my secret goal for the trip, making some crucial progress in writing my long-overdue book which I’ve resolved to publish later this year.
The comedian (Rodney Johnson) was selling a copy of his book, and he autographed my copy with an inscription (coincidentally) perfect for my goals on the cruise:
Apparently, I was the only person to buy the book on the first day, and at the show on the last day, he asked if I was in the audience (“I am!”), had read it (“I did! Cover to cover!”) and what I thought of it (On the spot, I said “Pretty good”, and emailed him a funnier response later).
I often sit in the front row at shows, and I was called on stage to help Michael Holly with a magic trick (We held a chain and he walked through it.).
My original shore excursion (an adventure park) was canceled, I made the best of it with a short speedboat and snorkeling trip.
30 horsepower isn’t a lot, but it was plenty to jump the wavesAfter returning the boat, I killed an hour at a pretty swim-up bar.
With just one day at a destination and two sea days, I also booked a “Behind the Scenes” tour of the boat, getting the chance to see a galley, the provisions storerooms, the laundry, the bridge, the engine control room, and backstage in the theater.
The Engine Control Room
The crew work incredibly long hours: 10 hours a day, 7 days a week, on 7 month contracts. I resolved to think of this guy any time I’m feeling overwhelmed with work– He’s working in a windowless (underwater) room, hand-folding thousands of towels per day from a room-sized pile almost as tall as he is.
All in all, it was a busy but great spring break. Now, buckling down to get back in shape (two 10Ks coming up), finish booking various trips (including Kilimanjaro!), and otherwise get back to some semblance of a routine.