This is an introduction/summary post which will link to individual articles about browser mechanisms for communicating directly between web content and native apps on the local computer (and vice-versa).
This series aims to provide, for each mechanism, information about:
- On which platforms is it available?
- Can the site detect that the app/mechanism is available?
- Can the site send more than one message to the application without invoking the mechanism again, or is it fire-and-forget?
- Can the application bidirectionally communicate back to the web content via the same mechanism?
- What are the security implications?
- What is the UX?
Application Protocols
tl;dr: Apps can register url protocol schemes (e.g. myapp://mydata). Browsers will spawn the native apps when directed to navigate to a url of that scheme.
Characteristics: Fire-and-Forget. Generally non-detectable. Supported across all browsers for decades, supported on desktop platforms, but typically not mobile platforms. Prompts on launch by default, but warnings usually can be suppressed.
Native Messaging via Extensions
tl;dr: Browser extensions can communicate with a local native app using stdin/stdout channels, passing JSON between the app and the extension. The extension may pass information to/from web content if desired.
Characteristics: Bi-directional communications. Detectable. Supported across most modern browsers; not legacy IE. Dunno about Safari. Installing extensions requires a prompt, and installing Native Hosts requires a local application installation, but post-install, communication is (usually) silent.
File downloads (Traditional)
Blog Post – I gave a long talk on this topic at a conference.
tl;dr: Apps can register to handle file types of their choosing. The user may spawn the app to open the downloaded file.
Characteristics: Fire-and-Forget. Non-detectable (can’t tell if the user has the app). Supported across all browsers in default configurations, although administrators may restrict download of certain file types. Shows prompts for most file types, but some browsers allow bypassing the prompt.
DirectInvoke of File downloads
tl;dr: Internet Explorer/Edge support DirectInvoke, a scheme whereby a file handler application is launched with a URL instead of a local file.
Characteristics: Fire-and-Forget. Non-detectable. Windows only. Supported in Internet Explorer, Edge 18 and below, and Edge 78 and above. Degrades gracefully into a traditional file download in unsupported browsers.
Drag/Drop
Blog Post – Coming someday.
tl;dr: Users can drag/drop files into and out of the browser.
Bi-directional. Awkward. “Looks like” a file upload or download in most ways.
System Clipboard
Blog Post – Coming someday.
tl;dr: Much in common with drag/drop: Web Pages and local applications can read and write the shared clipboard. You can pass limited types of data this way, and sometimes attackers do.
Bi-directional. Awkward. If you don’t immediately use and clear the clipboard, some other site/app with access to it might read or overwrite your data.
Local Web Server
Blog Post – Coming someday.
tl;dr: Apps can run a HTTP(S) server on localhost and internet webpages can communicate with that server using fetch/XHR/WebSocket/WebRTC etc.
Requires calling page be a secure context. Potential future restrictions: may require internal website to respond to a CORS pre-flight
Update: As of 2026, such connections require that the user approve a permission request:
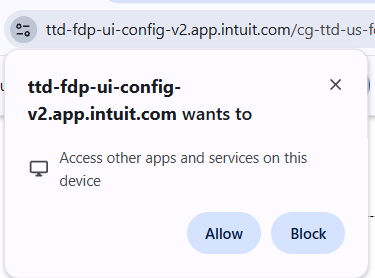
Characteristics: Bi-directional communications directly from web pages. Detectable. Supported across all browsers. Not available on mobile. Complexities around Secure Contexts / HTTPS, and loopback network protections in Edge18/IE AppContainers and upcoming restrictions in Chromium.
Risks: Webservers are complicated and present a lot of attack surface. Many products have gotten this wrong; beware of DNS Rebinding attacks.
This capability has also been abused as a tracking-vector and for other abuse.
Local Web Server- Challenges with HTTPS
In many cases, HTTPS pages may not send requests to HTTP URLs (depending on whether the browser supports the new “SecureContexts” feature that treats http://localhost as a secure context, and not as mixed content. As a result, in some cases, applications wish to get a HTTPS certificate for their local servers.
Getting a trusted certificate for a non-public server is complex and error-prone. Many vendors used a hack, whereby they’d get a publicly-trusted certificate for a hostname (e.g. loopback.example.com) for which they would later use DNS to point at 127.0.0.1. However, doing things this way requires putting the certificate’s private key in the service software on the client (where anyone can steal it). After that private key is extracted and released, anyone can abuse it to MITM connections to services using that certificate. In practice, this attack is of limited interest (it’s not useful for attacking traffic broadly) but compromise of a private key means that the certificate must be revoked per the rules for CAs. So that’s what happens. Over and over and over.
The inimitable Ryan Sleevi wrote up a short history of the bad things people do here after Atlassian got dinged for doing this wrong.
Prior to Atlassian, Amazon Music’s web exposure can be found here: https://medium.com/0xcc/what-the-heck-is-tcp-port-18800-a16899f0f48f
How to do this right? There’s a writeup of how Plex got HTTPS certificates for their local servers. See Emily Stark’s post to explore this further.
There exist WebRTC tricks to bypass HTTPS requirements.
—–
Notes: https://wicg.github.io/cors-rfc1918/#mixed-content
Andrew (@drewml) tweeted at 4:23 PM on Tue, Jul 09, 2019:
The @zoom_us vuln sucks, but it’s definitely not new. This was/is a common approach used to sidestep the NPAPI deprecation in Chrome. Seems like a @taviso favorite:
Anti virus, logitech, utorrent. (https://twitter.com/drewml/status/1148704362811801602?s=03)
Bypass of localhost CORS protections by utilizing GET request for an Image
https://bugs.chromium.org/p/chromium/issues/detail?id=951540#c28
Variant: Public HTTPS Server as a Cloud Broker
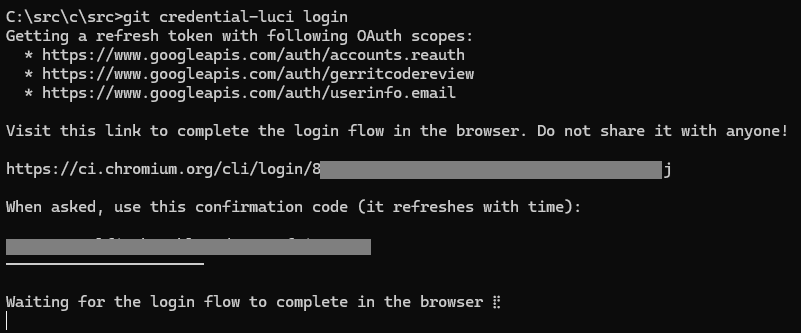
An alternative approach would be to communicate indirectly. For instance, a web application and a client application using HTTPS/WebSockets could each individually communicate to a common server on the public internet which brokers messages between them.
I think Chromium’s engineering system is currently using this during the authentication process:
HTML5 getInstalledRelatedApps()
While not directly an API to communicate with a local app, the getInstalledRelatedApps() method allows your web app to detect whether a native app is installed on a user’s device, allowing the web app to either suggest that users install the native client, or navigate the user to a web-based equivalent app if the native app isn’t installed. On Windows, this API only supports discovery of UWP Apps, not classic Win32 applications.
This mechanism attempts to provide better privacy and performance characteristics than the defunct mechanisms once offered by Internet Explorer (User-Agent string tokens or Version Vectors that could be targeted by that browser’s Conditional Comments feature).
Windows AppLinks aka AppURIHandlers
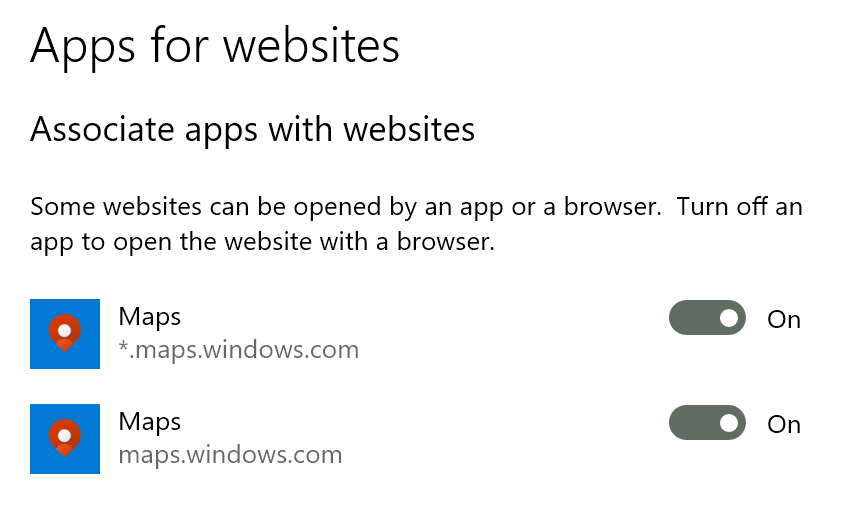
Allow navigation to certain namespaces (domains) to be handed off to a native application on the local device. So, when you navigate to https://netflix.com/, for instance, the Netflix App opens instead. Registered handlers can be found in the “Apps for websites” section of the Windows Control Panel:
This feature is commonly available on mobile operating systems (e.g. Android) and was supported briefly in Legacy Edge on Windows 10, where it caused a fair amount of user annoyance, because sometimes users really do want to stay in the browser. This feature is not supported in the new Edge, Chrome, or Firefox.
- https://blogs.windows.com/windowsdeveloper/2016/10/14/web-to-app-linking-with-appurihandlers/
- https://docs.microsoft.com/en-us/windows/uwp/launch-resume/web-to-app-linking
Android AppLinks
Basically the same as Windows AppLinks: your app’s manifest declares ownership over URLs in your HTTPS domain’s namespace. Learn more.
Android Intents
Very similar to App Protocols, a web page can launch a native Android application to handle a particular task. See this blog paul.kinlan.me/launch-app-from-web-with-fallback/ and learn more and more and more and more.
Windows .NET ClickOnce
Internet Explorer, Edge Legacy, and the new Edge support a Microsoft application deployment technology named ClickOnce. A website can include a link to a ClickOnce .application file, and when the client uses DirectInvoke to spawn the ClickOnce app, it will pass the full URL, including any query string arguments, into that app.
Other browsers (e.g. Firefox and Chrome) will download the .application and launch it, but any querystring arguments on the download URL will not be passed to the application unless you install a browser extension.
Android Instant Apps
Basically, the idea is that navigating to a website can stream/run an Android Application. Learn more.
Legacy Plugins/ActiveX architecture
Please no!
Characteristics: Support has been mostly removed from nearly all browsers. Bi-directional communications. Detectable. Generally not available on mobile. One of the biggest sources of security risk in web platform history.
Browser Devs Only: Site-Locked Private APIs
Browser vendors have the ability to expose powerful APIs to only a subset of web pages loaded within the browser.
Chromium has a built-in facility to limit certain DOM APIs to certain pages, mostly to enable powerful APIs to certain built-in chrome:// pages. However, this capability can also be used to lock an API to a list of https:// sites. For instance, Microsoft Edge Marketing webpages have the ability to direct Edge to launch certain user-experiences, and the Edge New Tab Page has access to some JavaScript APIs that allow web content from the New Tab Page website to interact with native code in the browser.
Site-Locked Private APIs are expensive to build and have serious security and privacy implications (an XSS on an allow-listed site would allow an attacker to abuse its Private API permissions). Even without a site vulnerability, most pages can be modified by many browser extensions, such that a private API could be abused by any extension with the ability to modify a page that is allowlisted by a privileged API.
Furthermore, these Private APIs sometimes have implications for Open Standards and legal regulations that can make them very difficult to build.
Site-Locked Private APIs are not typically something that Web Developers or the public in general can add or make use of– these are typically only available for the developer of the browser itself.
Browser Devs Only: Native Url Protocols
In a similar vein, browser developers have the ability to add new Native URL Protocols to the browser, allowing the browser to send and receive data from a custom URL scheme whose code is a part of the browser itself. (Internet Explorer allowed any code to supply the implementation, a huge security nightmare).
Native URL protocol functionality is used, for example, by the edge: URL scheme to return the web content that implements Edge’s settings pages.
Adding new native URL protocols is very expensive and has serious security implications. I wrote a post where you can learn more about the implications of adding protocol schemes to Chromium.
Browser Devs Only: NavigationThrottles and ResourceThrottles
Browser developers have the ability to introduce custom behaviors when performing navigations or downloading resources from websites. Commonly, this might entail adding custom HTTP request headers or setting cookies when navigating to particular websites. Within Chromium there exist throttles (NavigationThrottles and ResourceThrottles) which easily expose this power to the browser developer.
For example, browsers might add authentication tokens in cookies or headers sent when navigating to login pages to avoid asking users for their passwords; this is how a Single Sign On mechanism works. Similarly, Edge sends a custom HTTP request header (PreferAnonymous) when navigating to the user’s default search engine while the user is in InPrivate mode so that the website can respect that privacy expectation.
FootGun: Cookie Database Manipulation
Native App Developers have a lot of power — their code runs at full-trust and generally can see most all files on the system. Feeling clever, some app developers have thought to themselves: “Hey, the browser stores its cookies in a SQLite database on disk. I can just open that and add cookies to it which the browser will send the next time the user visits a site I want to communicate with.” For example, the Bing Wallpaper app tried to set a cookie that would let the Bing website know to stop asking the user to install the native app.
Do not do this.
The problem is that modifying browser cookie databases on disk is not supported, and not supportable. The schema for cookie databases changes from time-to-time, and browsers have started opening the database with an exclusive lock, causing a loss of all cookies if the browser opens while your app has a handle on the database.
Beyond those insurmountable challenges, there are more obvious ones that also preclude similar approaches. For example, a user may use any of dozens of browsers, and they may have multiple profiles for each browser — how do you decide where to write the cookie? Do you write it in every profile of every browser?







 On a whim, I searched around to see whether maybe I could buy a new overlay to stick atop the old panel.
On a whim, I searched around to see whether maybe I could buy a new overlay to stick atop the old panel.

