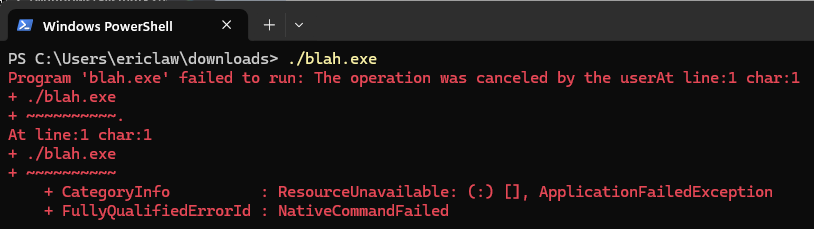
After you sign up on the Social Security Administration’s website, they’ll send you a yearly email inviting you to check out your benefits. Flipping through my Junk Mail folder this afternoon, I found the following email:
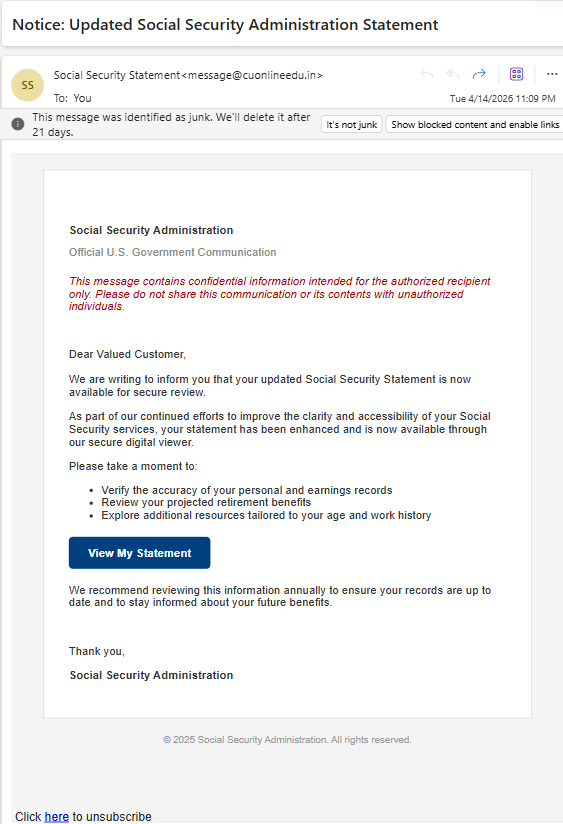
It looks reasonably plausible, except for the return address (cuonlineedu.in, a university in India). I’m always game to look at an attack, so I naturally clicked the “View my statement” link the bad guy hopes I’d click. This navigation results in redirecting through a page on the University’s website to go to a Spanish TLD:
GET http://delivery.cuonlineedu.in/UDFEKT?id=28719=c0oCVAtaBQlfGAQDA1YCAl4BAwZSBQVYUFwFAloGVgNRUFRTDFcHDAUAA1YMVgcFDA5LBj1cVhYRXFpXXXZcCkRbUw1VTFFXCxgBUQNVU1IBDQBXUgQCV1sKA0hQQkAVChkdAFwOW04DFklIVxYMDVRRWQYHVEJPClcbYXxwcS5kCVsARRQB&fl=WEJGFEpYHRcEAUMSXQcGCllLVREXXlhPAFZZGl1FGw==302 Redirect to https://bestideiasbruno.com.es/GET https://bestideiasbruno.com.es/download.php?url=aHR0cHM6Ly9hcm9taXNiZC5jb20vd3AtY29udGVudC9nZW4ubXNp&name=eStatement455378357_pdf.msi200 (application/octet-stream)GET https://www.ssa.gov/myaccount/statement.html200 (text/html)
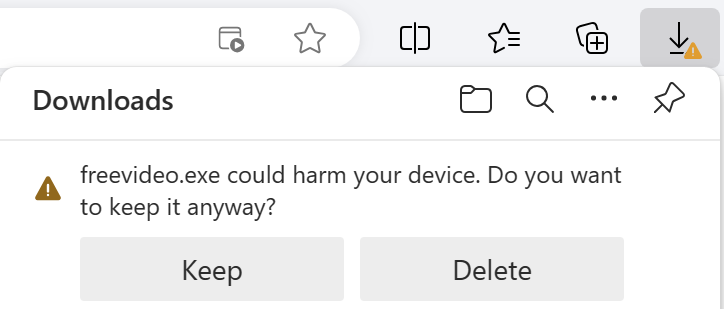
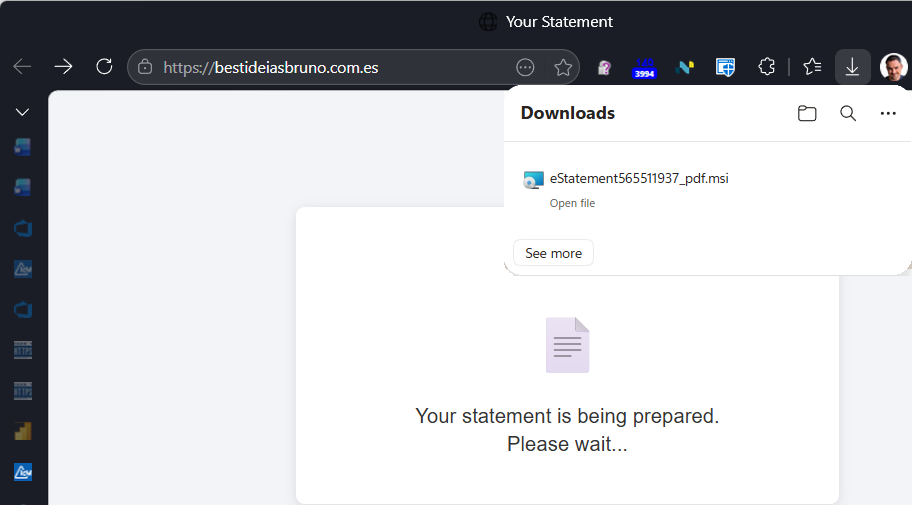
When that page loads, it claims that your “statement is being prepared” and a file download appears. The file download, named (eStatement####_pdf.msi) is an Windows Installer package named to make it look like a PDF file.
For contrast, the legitimate download would’ve looked like this:
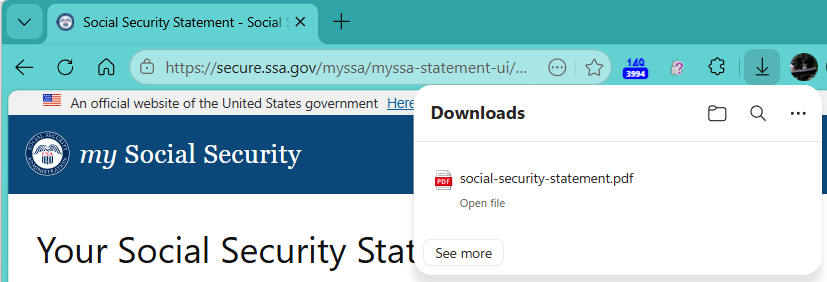
After kicking off the MSI file download, the attack site navigates to a legitimate page on the Social Security site.
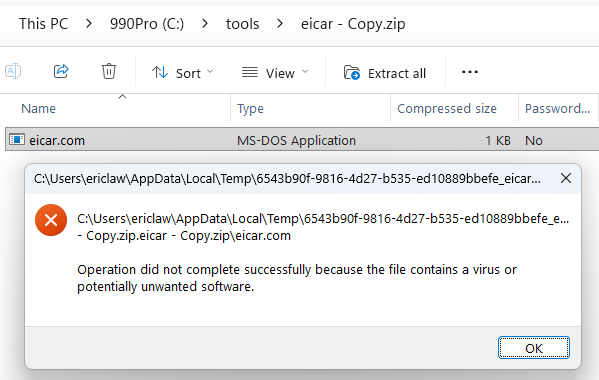
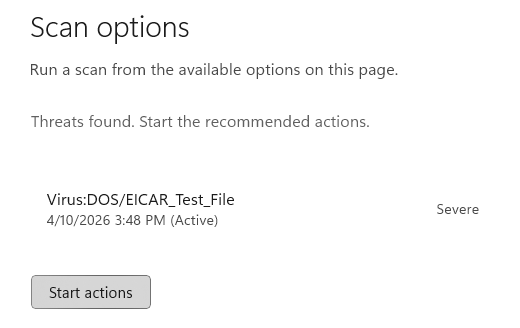
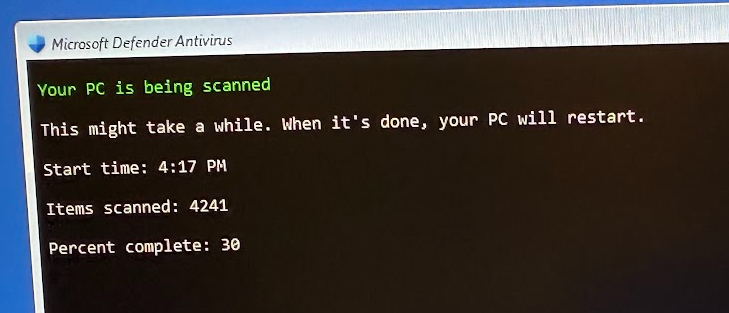
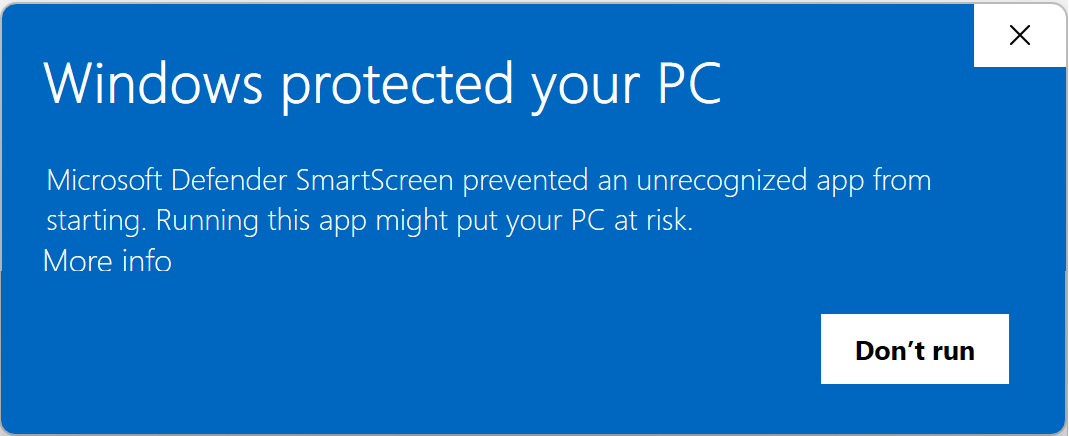
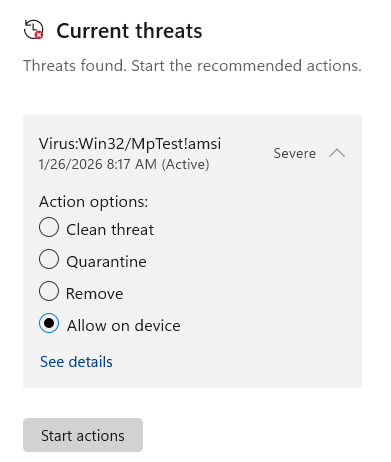
Okay, so the fake site dropped a file hoping we’d open it, and we can be pretty sure that a file delivered this way is going to be some form of malware. But it’s very concerning that neither SmartScreen or Microsoft Defender Antivirus complained about the file. Let’s take a closer look.
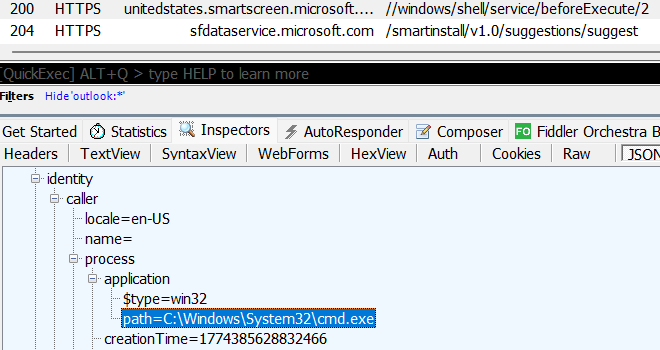
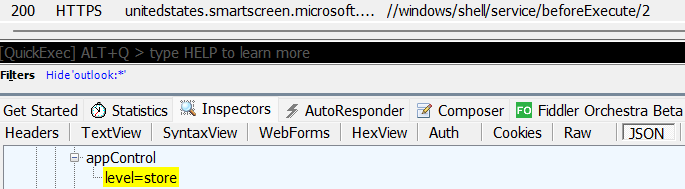
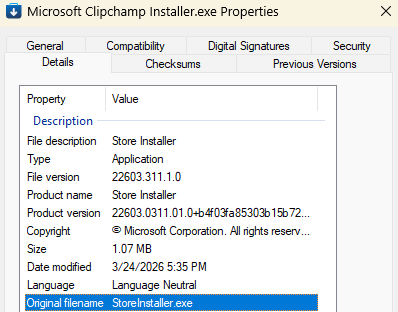
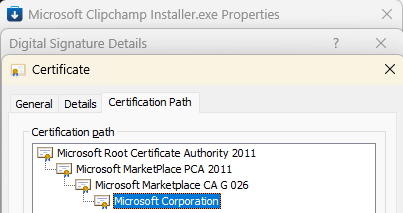
The first thing to note is that the file is Authenticode-signed:
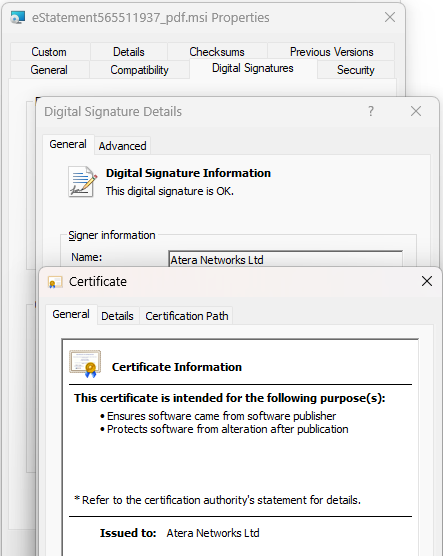
The MSI file is signed by a legitimate company and after uploading it, we see that it’s “Clean” on VirusTotal. (Update: Shortly after this post, the attackers changed to a new installer, also “Clean” on VirusTotal).
Hrm. Maybe the company got hacked and someone stole their certificate to sign malware? Looking more closely at the file information, we see that it was signed on April 13th and the file information looks legitimate “This installer database contains the logic and data required to install AteraAgent.” rather than what an attacker might pick (e.g. “You’re Social Security Info is inside. Open me hurry hurry hurry.”)
At this point, I had a strong hint that I knew what was going on, but in this AI-hyped world, I wondered whether Copilot would give me good advice.
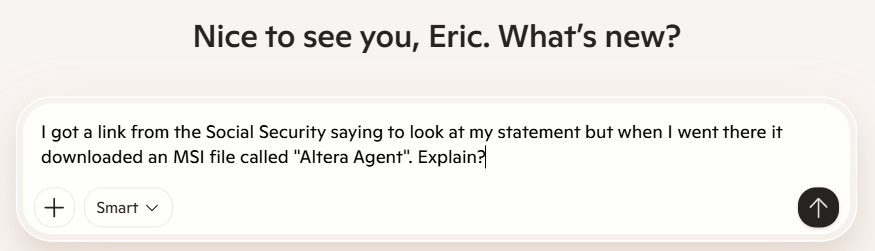
Microsoft Copilot correctly recognizes that it’s a scam, but it gets the details wrong:

Let’s ask Google’s Gemini:
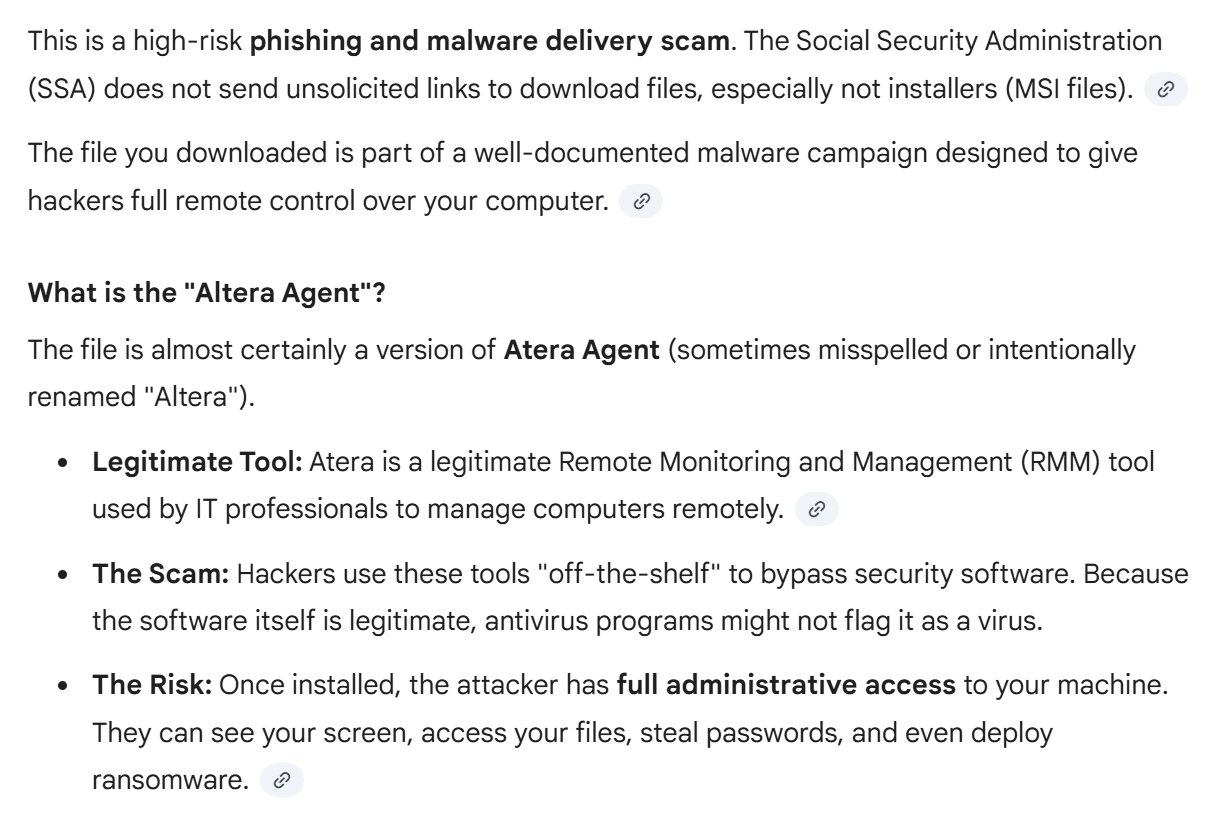
Gemini gets it right — the file is legitimate, but it’s being abused by an attacker. The Atera Agent is a piece of software that is categorized as a Remote Monitoring and Management (RMM) tool, which might be referred to by another name: a backdoor.
If you run the file (in a sandbox, obviously), you just get a simple install screen:
After the install has proceeded for a while, the following dialog box is shown:
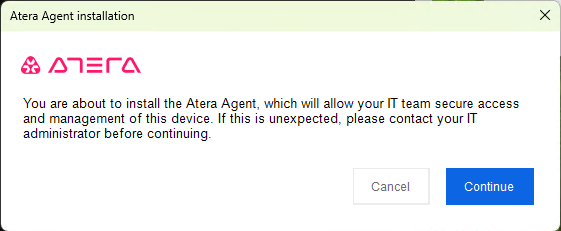
If you hit the big blue Continue button, the service is started:
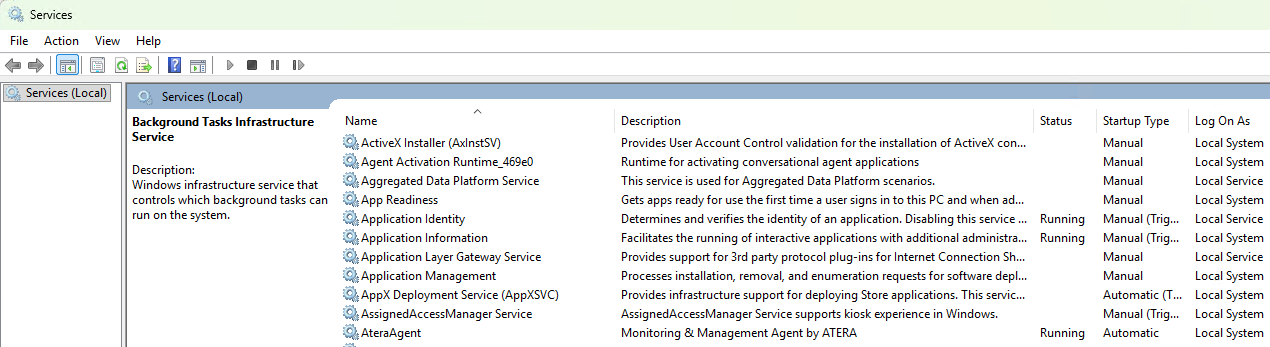
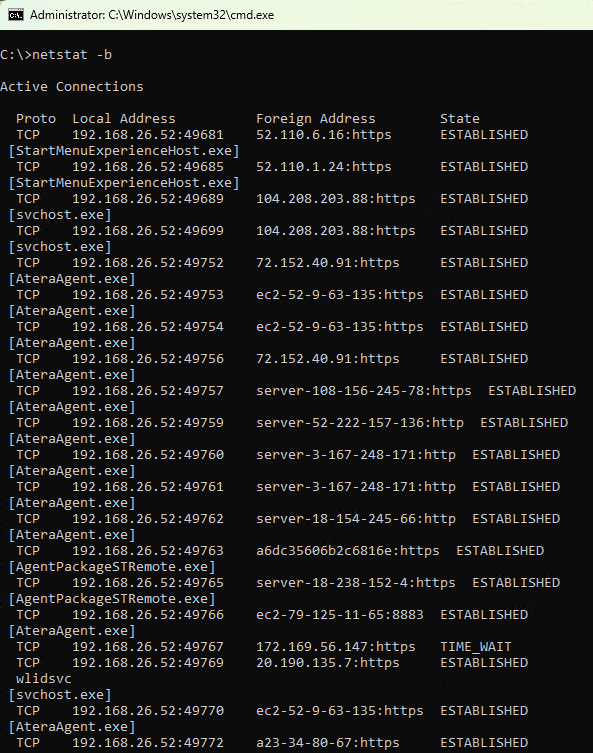
…and your device immediately sets up connections to the infrastructure that will allow the attacker to take control of your device:
Tools and Weapons
(Note: Microsoft President Brad Smith wrote a book with this title).
This attack demonstrates one of the most challenging parts of cybersecurity: many tools can be turned into weapons simply by using them maliciously. The dominant use of the AteraAgent is legitimate, but in the hands of an attacker, the impact on the victim is the same as if they had installed malware on their device.
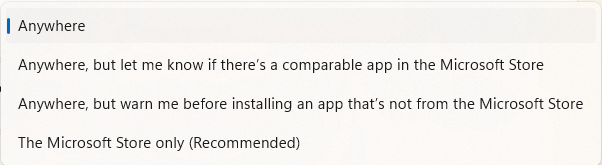
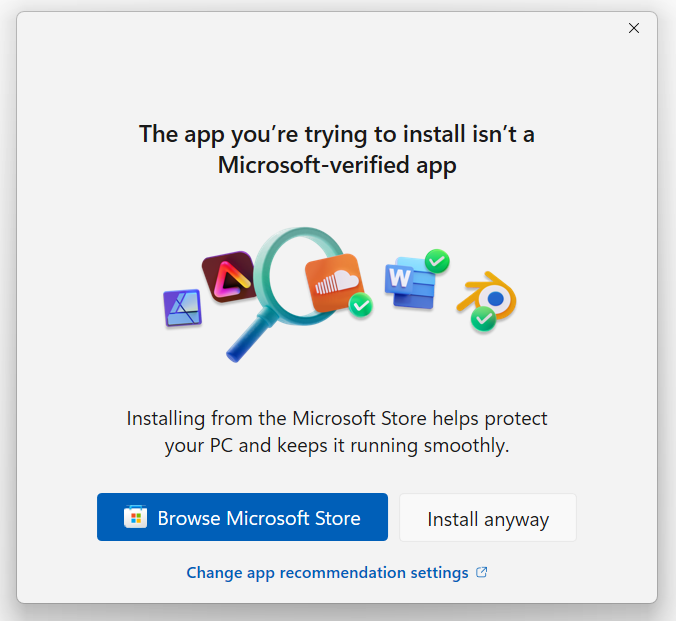
Now, what can Atera do about the abuse of their tool? They’ve done at least the bare minimum thing (added a notification screen during the install), but they could do more. For example, the screen doesn’t clearly explain the threat, and there’s no button to “Report Abuse to Atera.” An unanswered two year old thread on Reddit suggests these Atera-powered attacks have been going on for quite some time, and there have been high-profile attacks in the past. Hopefully they are keeping a close eye on their “Trial” customers — attackers love to abuse free trials to attack victims.
What can a normal computer user do to protect against this attack? Not a ton. Certainly, they should take care when interacting with their PC: aka don’t be me. Don’t go trolling around in the Junk Mail folders to click on links, take care with file downloads, keep an eye out when asked to make decisions, be paranoid.
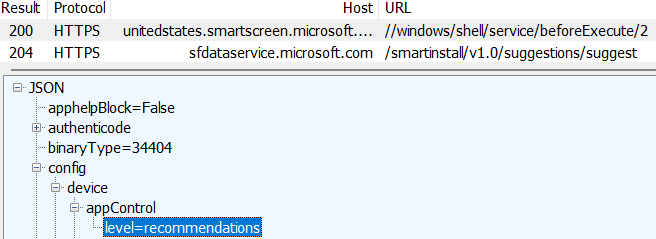
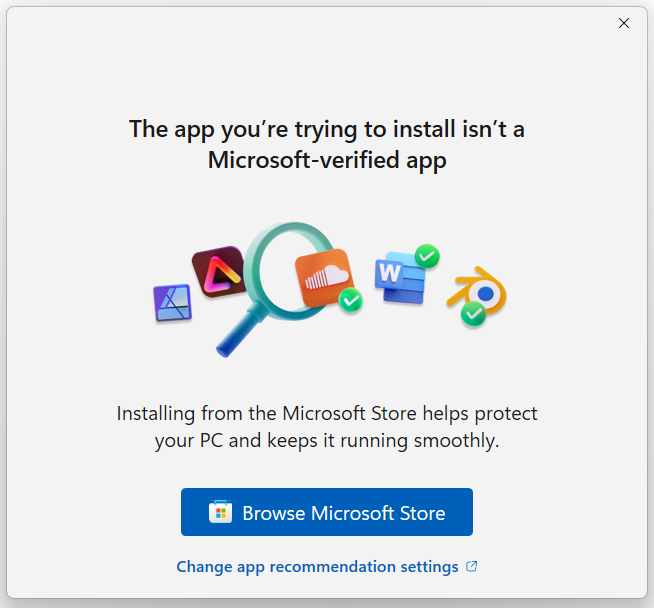
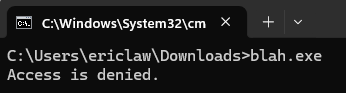
A security-conscious Enterprise might block an attack like this by using Application Control software to block all (or unexpected) RMM tools on their devices. Beyond protecting against campaigns like this one, such protections can also help inhibit Tech Scams where users are enticed to download a legitimate RMM tool to give an attacker access to their PC.
-Eric
PS: See also this post on Microsoft’s Security Blog.
PPS: Note that Windows itself ships with an RMM tool called “QuickAssist”, and sadly it has nothing to say about scams in its UI: