A few years back, I wrote a short explainer about User Gestures, a web platform concept whereby certain sensitive operations (e.g. opening a popup window) will first attempt to confirm whether the user intentionally requested the action.
As noted in that post, gestures are a weak primitive — while checking whether the user clicked or tapped a key is simple, gestures poorly suit the design ideal of signaling an unambiguous user request.
Hijacking Gestures
A recent blog post by security researcher Paulos Yibelo clearly explains a class of attack whereby a user is enticed to hold down a key (say, Enter) and that gesture is treated as both an acceptance of a popup window and results in activating a button on a target victim website. If the button on that website performs a dangerous operation (“Grant access”, “Transfer money“, etc), the victim’s security may be irreversibly compromised.

The author calls the attack a cross window forgery, although I’d refer to it as a gesture-jacking attack, as it’s most similar to the ClickJacking attack vector which came to prominence in 2008. Back then, browsers vendors responded by adding defenses against ClickJacking attacks against subframes, first with IE’s X-Frame-Options response header, and later with the frame-ancestors directive in Content Security Policy. At the time, cross-window ClickJacking was recognized as a threat unmitigated by the new defenses, but it wasn’t deemed an especially compelling attack.
In contrast, the described gesture-jacking attack is more reliable, as it does not rely upon the careful positioning of windows, timing of clicks, and the vagaries of a user’s display settings. Instead, the attacker entices the user to hold down a key, spawns a victim web page, and the keydown is transferred to the victim page. Easy breezy.
Some folks expected that this attack shouldn’t be possible– “browsers have popup-blockers after all!” Unfortunately for their hopes and dreams, the popup blocker isn’t magical. The popup-blocker blocks a popup only if it’s not preceded by a user-gesture. Holding the Enter key is a user-gesture, so the attacker’s page is allowed to spawn a popup window to a victim site.
The Core of the Threat
As with many cool attack techniques, the core of this attack depends upon a built-in web platform behavior. Specifically, when you navigate to a URL containing a fragment:
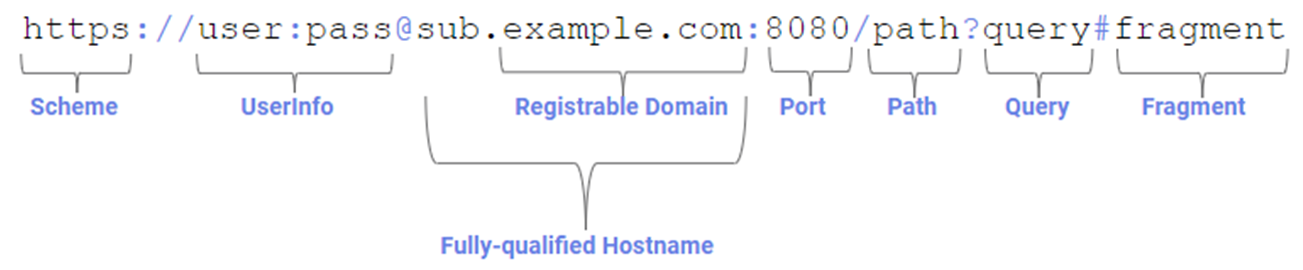
…the browser will automatically scroll to the first (if any) element with an id matching the fragment’s value, and set focus to it if possible. As a result, keyboard input will be directed to that element.
The Web Platform permits a site that creates a popup to set the fragment on its URL, and also allows it to set the size and position of the popup window.
Web Page Defenses
As noted in Paulos Yibelo’s blog post, a website can help protect itself against unintentional button activations by not adding id attributes to critical buttons, or by randomizing the id value on each page load. Or the page can “redirect” on load to strip off an unexpected URL Fragment.
For Chromium-based browsers, an additional option is available: a document can declare that it doesn’t want the default button-focusing behavior.
The force-load-at-top document policy (added as opt-out for the cool Scroll-to-Text-Fragment feature) allows a website to turn off all types of automatic scrolling (and focusing) from the fragment. In Edge and Chrome, you can compare the difference between a page loaded:
- Without the policy: https://webdbg.com/test/id.html#btn4
- vs. with the policy: https://webdbg.com/test/id.aspx#btn4
Browser support is not universal, but Firefox is considering adding it.
WebDev Best Practices
- Set
force-load-at-top(if appropriate) for your scenario, and/or removeidvalues from sensitive UI controls (e.g. for browsers that don’t support document policy) - Use
frame-ancestorsCSP to prevent framing - Auto-focus/make default the safe option (e.g. “Deny”)
- Disable sensitive UI elements until:
- Your window is sized appropriately (e.g. large enough to see a security question being asked)
- The element is visible to the user (e.g. use IntersectionObserver)
- The user has released any held keys
- An activation cooldown period (~500ms-1sec) to give the user a chance to read the prompt. Restart the cooldown each time a key is held, your window gains focus, or your window moves.
- Consider whether an out-of-band confirmation would be possible (e.g. a confirmation prompt shown by the user’s mobile app, or message sent to their email).
Beyond protecting the decision itself, it’s a good idea to allow the user to easily review (and undo) security decisions within their settings, such that if they do make a mistake they might be able to fix it before the damage is done.
Attacks on Browser UI
It’s not just websites that ask users to make security decisions or confirm sensitive actions. For instance, consider these browser prompts:
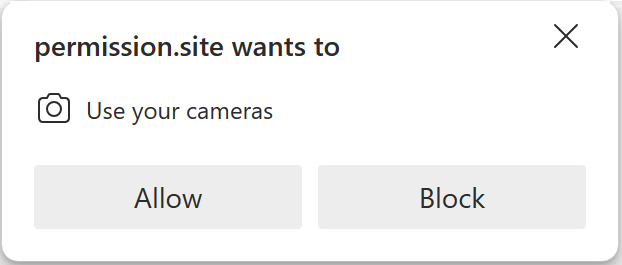

Each of these asks the user to confirm a security-critical or privacy-critical change.
As you might expect, attackers have long used gesture-jacking to abuse browser UI, and browser teams have had to make many updates to prevent the abuse:
- crbug.com/40057200
- crbug.com/40480283
- crbug.com/40059152
- crbug.com/40063023
- crbug.com/40063723
- crbug.com/40057030
- crbug.com/40056936
- crbug.com/40085079
Common defenses to protect browser UI have included changing the default button to the safe choice (e.g. “Deny”) and introducing an “input protection” activation timer.
Stay safe out there!
-Eric