One of the more common problems reported by Enterprises is that certain Edge/Chrome policies do not seem to work properly when the values are written to the registry.
For instance, when using the about:policy page to examine the browser’s view of the applied policy, the customer might complain that a policy value they’ve entered in the registry isn’t being picked up:
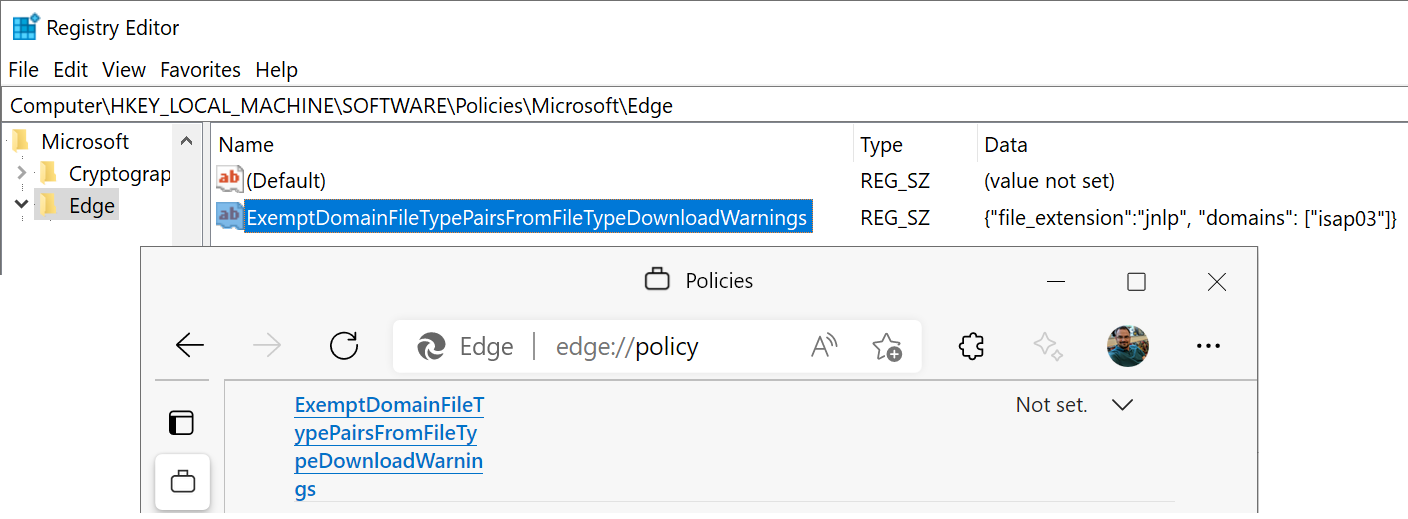
In a quick look at the Microsoft documentation for the policy: ExemptDomainFileTypePairsFromFileTypeDownloadWarnings, the JSON syntax looks almost right, but in one example it’s wrapped in square brackets. But in another example, the value is not. What’s going on here?
A curious and determined administrator might notice that by either adding the square brackets:

…or by changing the Exempt…Warnings registry entry from a REG_SZ into a key containing values:

…the policy works as expected:
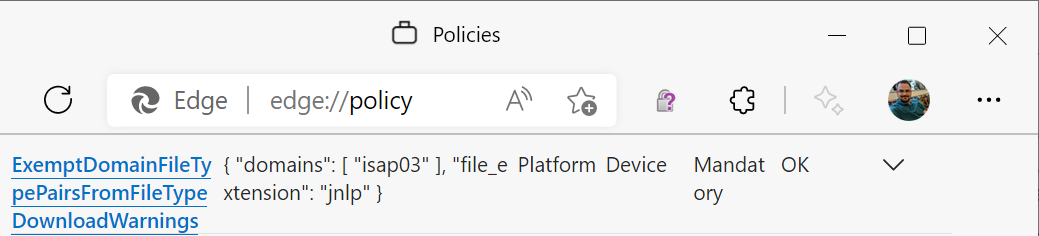
What’s going on?
As the Chromium policy_templates.json file explains, each browser policy is implemented as a particular type, depending on what sort of data it needs to hold. For the purposes of our discussion, the two relevant types are list and dict. Either of these types can be used to hold a set of per-site rules:
* 'list' - a list of string values. Using this for a list of JSON strings is now discouraged, because the 'dict' is better for JSON.
* 'dict' - perhaps should be named JSON. An arbitrarily complex object or array, nested objects/arrays, etc. The user defines the value with JSON.When serializing these policies to the registry: dict policies use a single REG_SZ registry string, while the intention is that list policies are instead stored in values of a subkey. However, that is not technically enforced, and you may specify the entire list using a single string. However, if you do represent the entire JSON list as a single string value, you must wrap the value in [] (square brackets) to represent that you’re including a whole array of values.
In contrast, if you encode the individual rules as numbered string values within a key (this is what we recommend), then you must omit the square brackets because each string value represents a single rule (not an array of rules).
Group Policy Editor
If you use the Group Policy Editor rather than editing the registry directly, each list-based policy has a Show... button that spawns a standalone list editor:
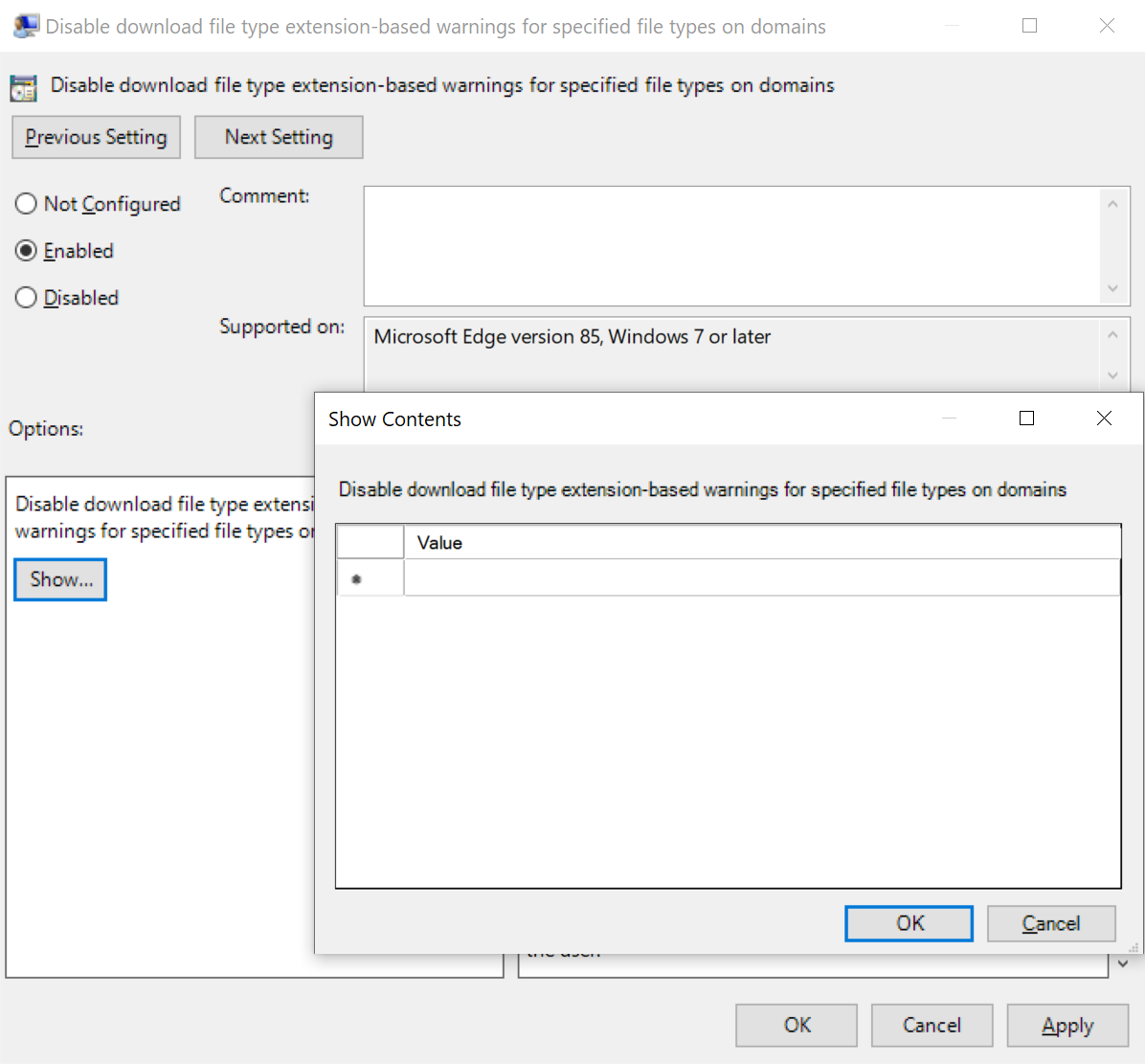
In contrast, when editing a dict, there’s only a small text field into which the entire JSON string should be pasted:

To ensure that a JSON policy string is formatted correctly, consider using a JSON validator tool.
Bonus Policy Trivia
Encoding
While JavaScript allows wrapping string values in ‘single’ quotes, JSON and thus the policy code requires that you use “double” quotes. Footgun: Make sure that you’re using plain-ASCII “straight” quotation marks (0x22) and not any “fancy/curly” Unicode quotes (like those that some editors like Microsoft Word will automatically use). If you specify a policy using curly quotes, your policy value will be treated as if it is empty.
Non-Enterprise Use
The vast majority of policies will work on any computer, even if it’s just your home PC and you’re poking the policy into the registry directly. However, to limit abuse by other software, there are a small set of “protected” policies whose values are only respected if Chromium detects that a machine is “managed” (via Domain membership or Intune, for example).
The kSensitivePolicies list can be found in the Chromium source and encompasses most, but not all (e.g. putting a Application Protocol on the URLAllowlist only works for managed machines) restrictions.
You can visit about:management on a device to see whether Chromium considers it managed.
Case-Sensitivity
Chromium treats policy names in a case-sensitive fashion. If you try to use a lowercase character where an uppercase character is required (or vice-versa), your policy will be ignored. Double-check the case of all of your policy names if the about:policy page complains about an Unknown Policy.
WebView2
The vast majority of Edge policies do not apply to the WebView2 control which is built atop the internal browser engine; only a tiny set of WebView2-targeted policies apply across all WebView2 instances. That’s because each application may have different needs, use-cases, and expectations.
An application developer hosting WebView2 controls must consider their customer-base and decide what restrictions, if any, to impose on the WebView2 controls within their app. They must further decide how those restrictions are implemented, e.g. on-by-default, controllable via a registry key read by the app on startup, etc.
For example, a WebView2 application developer may decide that they do not wish to ever allow DevTools to be used within their application, either because their customers demand that restriction, or because they simply don’t want anyone poking around in their app’s JavaScript code. They would then set the appropriate environment flag within their application’s code. In contrast, a different WebView2 host application might be a developer testing tool where the expectation is that DevTools are used, and in that case, the application might open the tools automatically as it starts.
Refresh
You might wonder when Edge reads the policy entries from the registry. Chromium’s policy code does not subscribe to registry change event notifications (Update: See below). That means that it will not notice that a given policy key in the registry has changed until:
- The browser restarts, or
- Fifteen minutes pass, or
- You push the
Reload Policiesbutton on theabout://policypage, or - A Group Policy update notice is sent by Windows, which happens when the policy was applied via the normal Group Policy deployment mechanism.
Chromium and Edge rely upon an event from the RegisterGPNotification function to determine when to re-read the registry.
Update: Edge/Chrome v103+ now watch the Windows Registry for change notifications under the HKLM/HKCU Policy keys and will reload policy if a change is observed. Note that this observation only works if the base Policies\vendor\BrowserName registry key already existed; if it did not, there’s nothing for the observer to watch. For Dev/Canary channels, a registry key can be set to disable the observer. Update-to-the-Update: The watcher was backed out shortly after I wrote this; it turns out that it caused bugs because the way that Group Policy updates work is the old registry keys are deleted, some non-zero time passes, and then the new keys are written. With the Watcher in place, this was causing the policies to be reapplied in the middle, turning off the policies for some time. This caused side-effects like the removal and reinstallation of browser extensions.
Note that not all policies support being updated at runtime; the Edge Policy documentation notes whether each policy supports updates with the Dynamic Policy Refresh value (visualizing the dynamic_refresh flag in the underlying source code).
-Eric