All major browsers have a built-in password manager. So we should use them, right?
I Do
- I use my browser’s password manager because it’s convenient: with sync, I get all of my passwords on all of my devices.
- This convenience means that I can use a different password for every website, improving my security.
- This convenience means that my passwords can be long and hard to type, because I never have to do so.
- This means that I don’t even know my own passwords for many sites, and because I can rely on my password manager to only fill my passwords on the sites to which they belong, I cannot succumb to a phishing attack.
- Enabling the Microsoft Edge Password Manager enables security-improving features like Password Monitor (breach detection) and Password Generation (effortless strong passwords)
Should You?
The easy answer is “Yes, use your browser’s password manager!“
The more nuanced answer begins: “Tell me about your threat model?”
As when evaluating almost any security feature, my threat model might not match your threat model, and as a consequence, our security choices might be different.
Here are the most relevant questions to consider when thinking about whether you should use a password manager:
- Is a password manager available for your platform(s)?
- What sort of attackers are you worried about?
- What sort of websites do you log into?
- Do you select strong, unique passwords?
- Are your accounts protected with 2FA?
- What sort of attacks are most likely?
- What sort of attacks are possible?
- How do you protect your devices?
- What’s your personal tolerance for inconvenience?
- Are you confident in the security of your password manager’s vendor?
- If you sync passwords, are you confident in the security of the design of the sync system?
- Does the password manager offer advanced features like breach detection and automatic password generation?
The answers to these questions might change your decisions about whether to use a password manager, and if so, whether you want to use the built-in password manager or use a password manager provided by a third-party.
For instance, if you’re sharing a Windows/Mac OS login account with someone you don’t trust, you should stop. If you cannot or don’t want to, you should not use a password manager, because there are trivial ways for a local user steal your passwords one-at-a-time and simple mechanisms and tools to steal them all at once. Of course, even if you’re not using a password manager, a co-user can simply use a keylogger to steal your passwords one-by-one as you type them.
Lock (WinKey+L) your computer when you’re not using it.
Attacks
While browser passwords are encrypted on disk, they’re encrypted using a key available to any process on your PC, including any locally-running malware. Even if passwords are encrypted in a “vault” by a “Primary Password”, they’ll be decrypted when loaded in the browser’s memory space and can be harvested after you unlock the vault. Even keeping the Primary Password itself safe from locally-running malware is basically impossible.
Locally-running malware is particularly dire if your threat model includes the possibility of a worm running rampant within your enterprise– it could infect all of your employees’ machines and steal all of their passwords in bulk in seconds. (Yes, dear reader, I know that you’re thinking of clever mechanisms to mitigate these sorts of attacks. I assure you I can defeat every practical idea you have. It’s a fundamental law of computing.)
Password storage sync introduces another vector for theft– if an attacker can phish your sync service’s credentials, they could steal all of your passwords. If your password manager contains corporate creds, they could be stolen from your “personal” profile.
Primary Passwords: No Silver Bullet
Edge and Firefox offer a “Primary Password” mechanism to restrict autofill until you authenticate with Windows Hello (PIN/Fingerprint/etc) or supply a custom primary password.
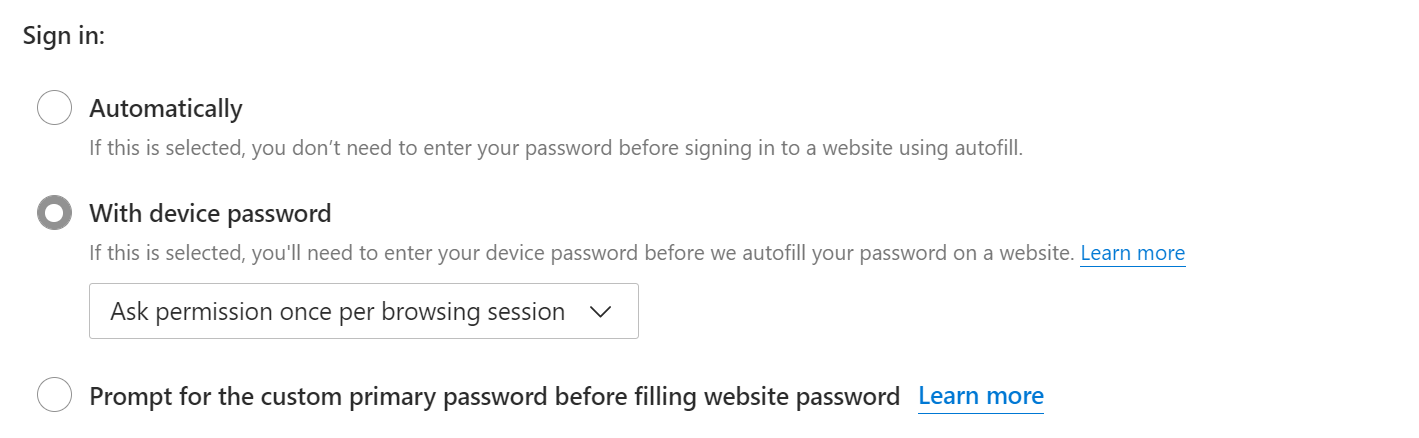
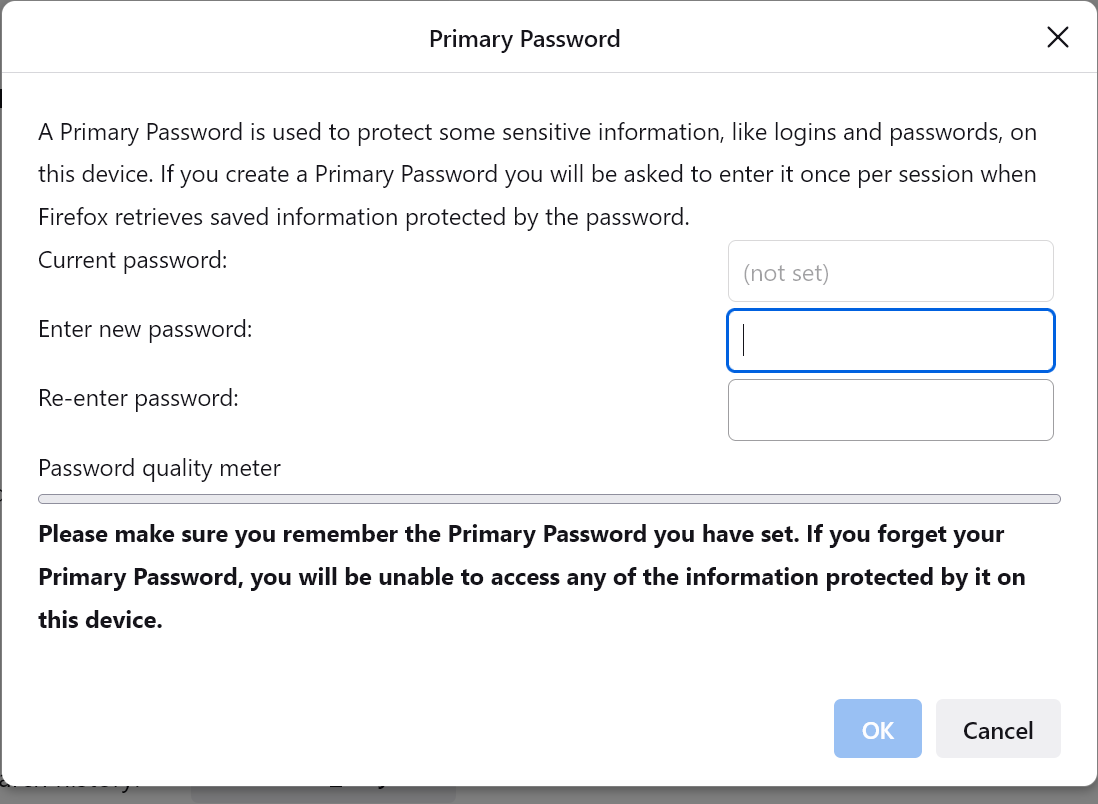
It is critical to understand that these mechanisms are a useful hurdle against opportunistic theft by an attacker without tools (e.g. your eight year old), not a security boundary.
Locally-running malware or a motivated malicious co-user can circumvent the protection using the mechanisms described in the previous section. The documentation contains similar caveats.
History
In the original incarnation of Chrome’s password manager, a local user could go to a page inside Chrome and freely see all of the passwords. Many users loudly demanded that this operation require some form of user proof, so the Chrome team very reluctantly added a “Users must provide their OS creds to see all the passwords at once” check, knowing that this was not a true security boundary and that some users might be misled into thinking that it was. Sure enough, they got more reports saying “Oooh, look at this, I can still steal passwords without knowing the Windows password”, which is entirely expected because of how the feature works: Passwords can still be stolen individually, or in bulk via Sync, or in bulk via reading the database directly.
For many years, the Chrome team declined to do anything to satisfy many users’ loud demands that the browser go further and prompt for some sort of user proof before filling an individual password in the page. The justification was largely the same—it could never be a security boundary and users might mistakenly think it was. Users howled “Look, I’m trying to keep my little sister out of my accounts, not defeat Kevin Mitnick!” but the Chrome team was unmoved. On the Edge side, we said “Hey, the little sister scenario is entirely reasonable, and we should offer users the option to require user proof on fill” so we did via the “Primary Password” feature. The immediate reason was to accommodate the “unmotivated attacker” user scenario, but the long-term reason was that if we, in the future, want to invest in building a real security boundary here, that real boundary will require the same UX flow, and we were curious to learn whether or not users would actually like/enable such a flow.
Security Baseline Recommendations
Concern about instantaneous bulk theft and egress of credentials has led the authors of security configuration guidance to recommend disabling browser password managers. For instance, the Edge Security Baselines (before version 114) and the Chrome STIG have historically suggested preventing users from using the password manager. I personally think this is a poor tradeoff that increases the higher risk of individual users getting phished, but I don’t write the configuration guidance, although I did advocate for the baseline change made in Edge 114.
Some tech elites advocate for using a 3rd-party password manager, and some users really like them. Most 3rd-party password managers are designed with broader feature sets to help satisfy alternative threat models, including using a “primary password” to help protect against limited local attackers. Importantly, however, no password manager is able to operate securely on a PC compromised by malware (as explored here). Many password managers include additional conveniences like automatic generation of strong passwords and roaming of passwords to mobile platforms and apps.
On the other hand, many external password manager applications are themselves a source of security vulnerabilities, and these products often end up growing extremely complicated due to the “Checkbox Wars” endemic to the security products industry.
Hacking expert Tavis Ormandy recommends using the Password Manager built into your browser, and he explains why, in depth.
Parting Advice
Passwords are a poor security mechanism, and should be phased out wherever possible. In particular, have a lot of optimism about the upcoming PassKeys feature.
When that’s not yet possible (because you don’t control the website): choose strong passwords, use a password manager if it satisfies your threat model, and enable 2FA if available — especially on your email accounts used for Password Sync and to which password recovery emails are sent. If a site offers a choice of 2FA methods, prefer FIDO over HOTP/Authenticator and HOTP/Authenticator over SMS Text messages.
-Eric
PS: Back in 2017, there was a bunch of press excitement about a privacy threat whereby autofilled credentials from the password manager might allow a website to identify a visitor before the user clicks the Login button. See this post for an exploration of this threat and its mitigations.