In Windows 10 RS5 (aka the “October 2018 Update”), the venerable XSS Filter first introduced in 2008 with IE8 was removed from Microsoft Edge. The XSS Filter debuted in a time before Content Security Policy as a part of a basket of new mitigations designed to mitigate the growing exploitation of cross-site scripting attacks, joining older features like HTTPOnly cookies and the sandbox attribute for IFRAMEs.
The XSS Filter feature was a difficult one to land– only through the sheer brilliance and dogged persistence of its creator (the late David Ross) did the IE team accept the proposal that a client-side filtering approach could be effective with a reasonable false positive rate and good-enough performance to ship on-by-default. The filter was carefully tuned, firing only on cross-site navigation, and in need of frequent updates as security researchers inside and outside the company found tricks to bypass it. One of the most significant technical challenges for the filter concerned how it was layered into the page download pipeline, intercepting documents as they were received as raw text from the network. The filter relied evaluating dynamically-generated regular expressions to look for potentially executable markup in the response body that could have been reflected from the request URL or POST body. Evaluating the regular expressions could prove to be extremely expensive in degenerate cases (multiple seconds of CPU time in the worst cases) and required ongoing tweaks to keep the performance costs in check.
In 2010, the Chrome team shipped their similar XSS Auditor feature, which had the luxury of injecting its detection logic after the HTML parser runs, detecting and blocking reflections as they entered the script engine. By throttling closer to the point of vulnerability, its performance and accuracy is significantly improved over the XSS Filter.
Unfortunately, no matter how you implement it, clientside XSS filtration is inherently limited– of the four classes of XSS Attack, only one is potentially mitigated by clientside XSS filtration. Attackers have the luxury of tuning their attacks to bypass filters before they deploy them to the world, and the relatively slow ship cycles of browsers (6 weeks for Chrome, and at least a few months for IE of the era) meant that bypasses remained exploitable for a long time.
False positives are an ever-present concern– this meant that the filters have to be somewhat conservative, leading to false-negative bypasses (e.g. multi-stage exploits that performed a same-site navigation) and pronouncements that certain attack patterns were simply out-of-scope (e.g. attacks encoded in anything but the most popular encoding formats).
Early attempts to mitigate the impact of false positives (by default, neutering exploits rather than blocking navigation entirely) proved bypassable and later were abused to introduce XSS exploits in sites that would otherwise be free of exploit (!!!). As a consequence, browsers were forced to offer options that would allow a site to block navigation upon detection of a reflection, or disable the XSS filter entirely.
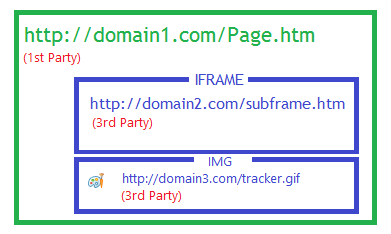
Surprisingly, even in the ideal case, best-of-class XSS filters can introduce information disclosure exploits into sites that are free of XSS vulnerabilities. XSS filters work by matching attacker-controlled request data to text in a victim response page, which may be cross-origin. Clientside filters cannot really determine whether a given string from the request was truly reflected into the response, or whether the string is naturally present in the response. This shortcoming creates the possibility that such a filter may be abused by an attacker to determine the content of a cross-origin page, a violation of Same Origin Policy. In a canonical attack, the attacker frames a victim page with a string of interest in it, then attempts to determine that string by making a series of successive guesses until it detects blocking by the XSS filter. For instance, xoSubframe.contentWindow.length exposes the count of subframes of a frame, even cross-origin. If the XSS filter blocks the loading of a frame, its subframe count is zero and the attacker can conclude that their guess was correct.
In Windows 10 RS4 (April 2018 update), Edge shipped its implementation of the Fetch standard, which redefines how the browser downloads content for page loads. As a part of this massive architectural shift, a regression was introduced in Edge’s XSS Filter that caused it to incorrectly determine whether a navigation was cross-origin. As a result, the XSS Filter began running its logic on same-origin navigations and skipping processing of cross-origin navigations, leading to a predictable flood of bug reports.
In the process of triaging these reports and working to address the regression, we concluded that the XSS Filter had long been on the wrong side of the cost/benefit equation and we elected to remove the XSS Filter from Edge entirely, matching Firefox (which never shipped a filter to begin with).
We encourage sites that are concerned about XSS attacks to use the client-side platform features available to them (Content-Security-Policy, HTTPOnly cookies, sandboxing) and the server-side patterns and frameworks that are designed to mitigate script injection attacks.
-Eric Lawrence