As we finish up the next release of Windows 10 (Fall 2018), my team is hard at work triaging incoming bugs.
Many such bugs take the form “Edge does the wrong thing for this page. ${Other_Browser} works okay.”
This post is designed to be an (ever-growing) index of some of the behavioral deltas that are the root cause of such issues:
Edge doesn’t allow navigation to DATA urls, even when they’d otherwise be converted to file downloads.
Using pushState or replaceState with |undefined| as the URL argument shows “undefined” in the Address box in Edge/IE but not Chrome or Firefox.
IE/Edge strip the Content-Encoding header from a compressed response; Firefox and Chrome leave the header in. For XmlHttpRequest’s getAllResponseHeaders, IE and Firefox maintain the case of HTTP Response header names while Chrome/Edge/Safari do not.
Chrome recognizes that a file with a .JSON extension has the type application/json (and vice versa) while IE/Edge only recognize that when the registry is configured with that mapping.
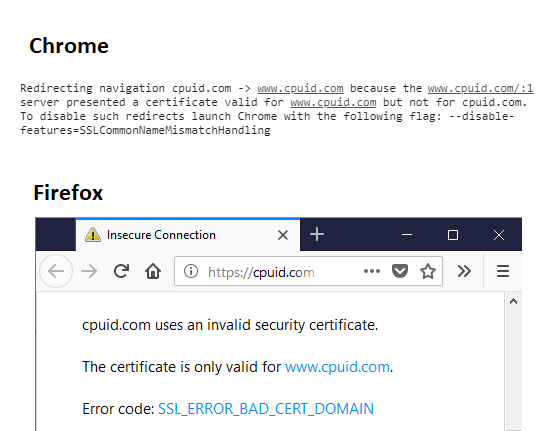
Chrome includes a hack that works around certificates that do not exactly match the domain on which they are served. Firefox, Edge, and IE do not include this hack, leading to a Certificate Name Mismatch Error when loading:
Edge does not fully support the URL standard, meaning that URLs of the form http:/example.com (note the missing slash) do not work as expected.
Edge and IE do not allow navigation to HTTP URLs containing a UserInfo component. Other browsers currently (reluctantly) allow this syntax.
Edge RS5 introduces support for Web Authentication specification (in order to support FIDO2 tokens). That specification extends the Credential Management API with new methods, so the navigator.credentials object now exists. However, Edge does not implement the navigator.credentials.preventSilentAccess() method and attempting to call it will cause an exception due to the missing method. (Edge always prevents silent access, so a future implementation of this method will simply fulfill the promise immediately).
When a server returns a HTTP/[301|302|303|307|308] response, Edge/IE are unable to read the response body if the server didn’t include a Content-Length header or Transfer-Encoding: chunked (HTTP/1.1). This turns out to break login to YouTube TV, where Google returns a response body over HTTP/2 (which does not require explicit content lengths thanks to its inherent message framing).
Edge supports most of CSP2 but currently does not support nonces on sourced script elements (only inline script and styles) [Test page]. This limitation significantly complicates deployment of CSP for sites that cannot easily enumerate their source locations in the Content-Security-Policy header (Edge does not support CSP3’s strict-dynamic directive yet either). A broad rule (e.g. script-src https: ) can be used as a workaround but this does increase attack surface.
IE and Edge begin immediately downloading the content of a SCRIPT SRC, not waiting until the SCRIPT element is added to this DOM. This means, for instance, that adding a |crossorigin| attribute to that element after setting its source does not result in an |Origin| header being sent on the request.
Continued over here in this post…
-Eric
 …but I end up on an error page:
…but I end up on an error page: