When #MovingToHTTPS, the first step is to obtain the necessary certificates for your domains and enable HTTPS on your webserver. After your site is fully HTTPS, there are some other configuration changes you should consider to further enhance the site’s security.
Validate Basic Configuration
First, use SSLLab’s Server Test to ensure that your existing HTTPS settings (cipher suites, etc) are configured well.
SECURE Cookies
After your site is fully secure, all of your cookies should be set with the SECURE attribute to prevent them from ever leaking over a non-secure channel. The (confusingly-named) HTTPOnly attribute should also be set on each cookie that doesn’t need to be accessible from JavaScript.
Next, consider enabling HTTP Strict Transport Security. By sending a HSTS header from your HTTPS pages, you can ensure that all visitors navigate to your site via HTTPS, even if they accidentally type “http://” or follow an outdated, non-secure link.
HSTS also ensures that, if a network attacker were to try to intercept traffic to your HTTPS site using an invalid certificate, a non-savvy user can’t wreck their security by clicking through the browser’s certificate error page.
After you’ve tested out a short-lived HSTS declaration, validated that there are no problems, and ramped it up to a long-duration declaration (e.g. one year), you should consider requesting that browsers pre-load your declaration to prevent any “bootstrap” threats (whereby a user isn’t protected on their very first visit to your site).
The includeSubdomainsattribute indicates that all subdomains of the current page’s domain must also be secured with HTTPS. This is a powerful feature that helps protect cookies (which have weird scoping rules) but it is also probably the most common source of problems because site owners may “forget” about a legacy non-secure subdomain when they first enable this attribute.
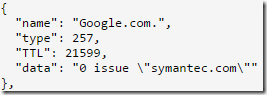
Certificate Authority Authorization (supported by LetsEncrypt) allows a domain owner to specify which Certificate Authorities should be allowed to issue certificates for the domain. All CAA-compliant certificate authorities should refuse to issue a certificate unless they are the CA of record for the target site. This helps reduce the threat of a bad guy tricking a Certificate Authority into issuing a phony certificate for your site.
The CAA rule is stored as a DNS resource record of type 257. You can view a domain’s CAA rule using a DNS lookup service. For instance, this record for Google.com means that only Symantec’s Certificate Authority may issue certificates for that host:
Configuration of CAA rules is pretty straightforward if you have control of your DNS records.
Public Key Pinning (HPKP)
Unfortunately, many CAs have made mistakes over the years (e.g. DigiNotar, India CCA, CNNIC CA, ANSSI CA) and the fact that browsers trust so many different certificate authorities presents a large attack surface.
To further reduce the attack surface from sloppy or compromised certificate authorities, you can enable Public Key Pinning. Like HSTS, HPKP rules are sent as HTTPS response headers and cached on the client. Each domain’s HPKP rule contains a list of Public Key hashes that must be found within the certificate chain presented by the server. If the server presents a certificate and none of the specified hashes are found in that certificate’s chain, the certificate is rejected and (typically) a failure report is sent to the owner for investigation.
Public Key Pinning powerful feature, and sites must adopt it carefully—if a site carelessly sends a long-life HPKP header, it could deny users access to the site for the duration of the HPKP rule.
Free services like ReportUri.io can be used to collect HPKP violation reports.
HPKP is supported by some browsers. 2023UPDATE: “Dynamic” PKP support, whereby sites can opt-in via HTTPS response headers has been removed from most browsers as it was found to be a “foot-gun” leading to unintentional self-inflected denial-of-service mistakes. Chromium-based browsers have a tiny built-in list of pins as a part of their HSTS preload list and now consider Certificate Transparency the right way to go.
Certificate Transparency
Certificate Transparency is a scheme where each CA must publicly record each certificate it has issued to a public, auditable log. This log can be monitored by site and brand owners for any unexpected certificates, helping expose fraud and phony domains that might have otherwise gone unnoticed.
Site owners who want a lightweight way to look for all CT-logged certificates for their domains can use the Certificate Transparency Lookup Tool. Expect that other tools will become available to allow site owners to subscribe to notifications about certificates of interest.
Since 2015, Chrome has required that all EV certificates issued be logged in CT logs. Future browsers will almost certainly offer a way for a site to indicate to visiting browsers that it should Expect or Require that the received certificate be found in CT logs, reporting or blocking the connection if it is not.Update: What actually happened is that in 2018 browsers began requiring CT logging of all certificates. See my later post for details on an easy way to monitor certificate transparency logs.
I called out the fact that while SHA1 certificates were verboten, “SHA1 file digests are still allowed (heck, MD5 digests are still allowed!)”.
With Windows 10 build 14316, things have changed again. It appears that SHA-1 file digests are now forbidden too, at least in the download codepath of Edge and Internet Explorer. This interrupts the download of Firefox, Opera, Fiddler, and other programs:
As with the earlier lockdown, if you examine the signature in Windows Explorer, it’ll tell you that everything is “OK.”
To resolve this, you should dual-sign your binaries using both SHA-1 and SHA-256. It appears that the same Windows 10 14316 build has a bug whereby a signature containing only a SHA256 file digest will cause the download in IE/Edge to hang at 99%.
Enough malware researchers now depend upon Fiddler that some bad guys won’t even try to infect your system if you have Fiddler installed.
The Malware Bytes blog post has the details, but the gist of it is that the attackers use JavaScript to probe the would-be victim’s PC for a variety of software. Beyond Kaspersky, TrendMicro, and MBAM security software, the fingerprinting script also checks for VirtualBox, Parallels, VMWare, and Fiddler. If any of these programs are thought to be installed, the exploit attempt is abandoned and the would-be victim is skipped. This attempt to avoid discovery is called cloaking.
This isn’t the only malware we’ve seen hiding from Fiddler—earlier attempts use tricks to see whether Fiddler is actively running and intercepting traffic and only abandon the exploit if it is.
This behavior is, of course, pretty silly. But it makes me happy anyway.
Preventing Detection of Fiddler
Malware researchers who want to help ensure Fiddler cannot be detected by bad guys should take the following steps:
Do not put Fiddler directly on the “victim” machine, instead run it as a remote proxy. – If you must install locally, at least install it to a non-default path.
To run Fiddler as a proxy server external to the victim machine (either use a different physical machine or a VM). – Tick the Tools > Fiddler Options > Connections > Allow remote computers to connect checkbox. Restart Fiddler and ensure the machine’s firewall allows inbound traffic to port 8888. – Point the victim’s proxy settings at the remote Fiddler instance. – Visit http://fiddlerserverIP:8888/ from the victim and install the Fiddler root certificate
Click Rules > Customize Rules and update the FiddlerScript so that the OnReturningError function wipes the response headers and body and replaces them with non-descript strings. Some fingerprinting JavaScript will generate bogus AJAX requests and then scan the response to see whether there are signs of Fiddler.
ZIP is a great format—it’s extremely broadly deployed, relatively simple, and supports a wide variety of use-cases pretty well. ZIP is the underlying format beneath Java (.jar) Archives, Office (docx/xlsx/pptx) files, Fiddler (.saz) Session Archive ZIP files, and many more.
Even though some features (Unicode filenames, AES encryption, advanced compression engines) aren’t supported by all clients (particularly Windows Explorer), basic support for ZIP is omnipresent. There are even solid implementations in JavaScript (optionally utilizing asmjs), and discussion of adding related primitives directly to the browser. 2024 Update: I made a simple WebApp for zipping files.
I learned a fair amount about the ZIP format when building ZIP repair features in Fiddler’s SAZ file loader. Perhaps the most interesting finding is that each individual file within a ZIP is compressed on its own, without any context from files already added to the ZIP. This means, for instance, that you can easily remove files from within a ZIP file without recompressing anything—you need only delete the removed entries and recompute the index. However, this limitation also means that if the data files you’re compressing contain a lot of interfile redundancy (duplicated data across multiple files), the compression ratio does not improve as it would if there were intrafile redundancy (duplicate data in a single file).
This limitation can be striking in cases like Fiddler, where there may be a lot of repeated data across multiple Sessions. In the extreme case, consider a SAZ file with 1000 near-identical Sessions. When that data is compressed to a SAZ, it is 187 megabytes. If the data were instead compressed with 7-Zip, which shares a compression context across embedded files, the output is 99.85% smaller!
In most cases, of course, the Session data is not identical, but web traffic sessions on the whole tend to contain a lot of redundancy, particularly when you consider HTTP headers and the Session metadata XML files.
The takeaway here is that when you look at compression, the compression context is very important to the resulting compression ratio. This fact rears its head in a number of other interesting places:
brotli compression achieves high-compression ratios in part by using a 16 megabyte sliding window, as compared to the 32kb window used by nearly all DEFLATE implementations. This means that brotli content can “point back” much further in the already-compressed data stream when repeated data is encountered.
brotli also benefits by pre-seeding the compression context with a 122kb static dictionary of common web content; this means that even the first bytes of a brotli-compressed response can benefit from existing context.
SDCH compression achieves high-compression ratios by supplying a carefully-crafted dictionary of strings that result in an “ideal” compression context, so that later content can simply refer to the previously-calculated dictionary entries.
Adding context introduces a key tradeoff, however, as the larger a compression context grows, the more memory a compressor and decompressor tend to require.
While HTTP/2 reduces the need to concatenate CSS and JS files by reducing the performance cost of individual web requests, HTTP response body compression contexts are still per-resource. That means that larger files tend to yield higher-compression ratios. See “Bundling Improves Compression.”
Compression contexts can introduce information disclosure security vulnerabilities if a context is shared between “secret” and “untrusted” content. See also CRIME, BREACH, and HPACK. In these attacks, the bad guy takes advantage of the fact that if his “guess” matches some secret string earlier in the compression context, it will compress better (smaller) than if his guess is wrong. This attack can be combatted by isolating compression contexts by trust level, or by introducing random padding to frustrate size analysis.
Want to learn much more about ZIP files? Check out these twogreat posts; or you can learn more about the author of PKZIP in this great (sad) video.
To help protect the user and their device, Windows and its applications will often treat files originating from the Internet more cautiously than files generated locally. The Windows Security Zones determination process is most directly implemented by the MapURLToZone API; that API accepts a URL or a file path and returns the correct Zone for the file.
An obvious problem arises, however– content downloaded from web browsers or email programs resides on the local disk, but originated from the Internet.
Windows uses a simple technique to keep track of where downloaded files originated. Each downloaded file is is tagged with a hidden NTFS Alternate Data Stream file named Zone.Identifier. You can check for the presence of this “Mark of the Web” (MotW) using dir /r or programmatically, and you can view the contents of the MotW stream using Notepad:
Within the file, the ZoneTransferelement contains a ZoneIdelement with the ordinal value of the URLMon Zone from which the file came1. The value 3 indicates that the file is from the Internet Zone2.
Aside: One common question is “Why does the file contain a Zone Id rather than the original URL? There’s a lot of cool things that we could do if a URL was preserved!” The answer is mostly related to privacy—storing a URL within a hidden data stream is a foot gun that would likely lead to accidental disclosure of private URLs. This problem isn’t just theoretical—the Alternate Data Stream is only one mechanism used for MotW. Another mechanism involves writing a <!--saved from url=http://example.com> comment to HTML markup; that form does include a raw URL. A few years ago, attackers noticed that they could use Google to search for files containing a MOTW of the form <!--saved from url(0042)ftp://username:secretpassword@host.com –> and collect credentials. Oops.Update: Microsoft later decided the tradeoff was worth it. Windows 10+ includes the referrer URL, source URL and other information in the Zone.Identifier stream.
Browsers and other internet clients (e.g. email and chat programs) can participate in the MOTW-marking system by using the IAttachmentExecute interface’s methods (preferred) or by writing the Alternate Data Stream directly. Chrome uses IAttachmentExecute and thus includes the URL information on Windows 10. Firefox writes the Alternate Data Stream directly (and as of February 2021, it too includes the URL information).
Handling Marked Files
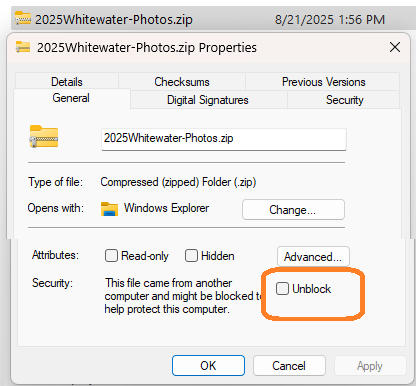
The Windows Shell and some applications treat Internet Zone files differently. For instance, examining a downloaded executable file’s properties shows the following notice:
More importantly, attempting to run the executable using Windows Explorer or ShellExecute() will first trigger evaluation using SmartScreen Application Reputation (Win8+) and any registered anti-virus scanners. The file’s digital signature will be checked, and execution will be confirmed with the user, either using the older Attachment Execution Services prompt, or the newer UAC elevation prompt:
Notably, MotW files invoked by non-shell means (e.g. cmd.exe or PowerShell) do not trigger security checks or prompts.
Smart App Control
While SmartScreen only checks the reputation of the entry point program, Windows 11’s Smart App Control goes further than SmartScreen and evaluates trust/signatures of all code (DLLs, scripts, etc) that is loaded by the Windows OS Loader and script engines.
SmartAppControl blocks a downloaded JS file from running
The current list of SAC-blocked-if-MotW extensions is .appref-ms, .appx, .appxbundle, .bat, .chm, .cmd, .com, .cpl, .dll, .drv, .gadget, .hta, .iso, .js, .jse, .lnk, .msc, .msp, .ocx, .pif, .ppkg, .printerexport, .ps1, .rdp, .reg, .scf, .scr, .settingcontent-ms, .sys, .url, .vb, .vbe, .vbs, .vhd, .vhdx, .vxd, .wcx, .website, .wsf, .wsh.
Office
Microsoft Office documents bearing a MotW open in Protected View, a security sandbox that attempts to block many forms of malicious content, and starting in 2022, macros are disabled in Internet-sourced documents.
Other Apps
As of October 2024, the Microsoft Management Console will refuse to load a .msc file from the Internet Zone (with a slightly misformatted prompt):
Some other applications inherit protections against files bearing a MotW, but don’t have any user-interface that explains what is going on. For instance, if you download a CHM with a MotW, its HTML content will not render until you unblock it using the “Always ask before opening this file” or the “Unblock” button:
What Could Go Wrong?
With such a simple scheme, what could go wrong? Unfortunately, quite a lot.
Internet Clients must participate
The first hurdle is that Internet clients must explicitly mark their downloads using the Mark-of-the-Web, either by calling IAttachmentExecute or by writing the Alternate Data Stream directly. Most popular end-user download clients will do so, but support is neither universal nor comprehensive.
For instance, for a few years, Firefox failed to mark downloads if the user used the Open command instead of Save. Similarly, in the past, browser plugins might have allowed attackers to save files to disk and bypass MotW tagging.
Microsoft Outlook (tested v2010) and Microsoft Windows Live Mail Desktop (tested v2012 16.4.3563.0918) both tag message attachments with a MotW you double-click on an attachment or right-click and choose Save As. Unfortunately, however, both clients fail to tag attachments if the user uses drag-and-drop to copy the attachment to somewhere in their filesystem. This oversight is likely to be seen in many different clients, owing to the complexity in determining the drop destination.
There are many ways to download files to a Windows system that do not result in writing a MotW to the file. For example, you can use the copy of CURL that ships in Windows, bitsadmin, a script that calls into WinINET or WinHTTP or System.NET objects (including from PowerShell), or you can use any of various binaries that offer downloads as a side-effect. The fact that these tools do not apply MotW is by-design — these are not common vectors for distribution of socially-engineered malware, and other security checks (e.g. Defender AV) still run.
Update: In the summer of 2024, a security update to File Explorer in Windows began adding a MotW to files copied to the local computer from untrusted network shares. When performing a file copy, File Explorer checks if the source file’s zone is Internet or Untrusted and, if so, it then evaluates URLACTION_SHELL_EXECUTE_HIGHRISK for the source file’s Zone. If that URLAction’s result is not set to URLPOLICY_ALLOW, then the destination file has a MotW added to it. A Group Policy was added to turn off the new behavior if desired.
Target file system must be NTFS
The Zone.Identifier stream can only be saved in an NTFS stream. These streams are not available on FAT32-formatted devices (e.g. some USB Flash drives), CD/DVDs, or the ReFS file system in Windows 8 / Server 2012 (support was later added to ReFS in Windows 8.1).
If you copy a file tagged with a MotW to a non-NTFS filesystem (or try to save it to such a file system to start with), the Mark of the Web is omitted and the protection is lost.
Originating location must be Internet or Restricted Zone
The IAttachmentExecute:Save API will not write the MotW unless the URL provided in the SetSource method is in a zone configured to write it (because that Zone’s setting for Launching applications and unsafe files is set to Enable):
Thus, by default, a MoTW can be written for Trusted, Internet or Restricted Sites zones. However, things get pretty weird for the Trusted Zone; a MotW is written only for a download from the Trusted Zone if there’s a Referrer and that Referrer is not Local Machine Zone1.
Normally, Windows will howl if an unsafe “Enable” configuration is set for the Internet Zone, but there’s a registry key that turns off the “Your security settings are unsafe” warning bar shown:
Policy must not disable the feature
Writing of the MoTW can be suppressed in the AttachmentExecuteServices API via Group Policy. In GPEdit.msc, see Administrative Templates > Windows Components > Attachment Manager > Do not preserve zone information in file attachments.
In the registry, the REG_DWORD SaveZoneInformation controls the behavior.
A value of 1 will prevent the MoTW from being written to files. (No, this isn’t an intuitive constant. For this policy, 1 means disabled, while 2 means enabled.)
For example, if the source of the download is a data: URI the browser has no great way to know what marking to put on the file. For data URIs or other anonymous sources, writing a default of about:internet is a common conservative choice to ensure that the file was treated as if it came from the Internet Zone. In Chrome v130, Chrome changed to begin storing the request_initiator for data: URL downloads.
Chromium stores about:internet rather than the real urls when saving downloaded files in Private Mode instances:
A url of about:untrusted would cause the file to be treated as originating from the Restricted Sites Zone.
blob: scheme URIs have a similar issue, but because blob URIs only exist within a security context (https://example/download/file.aspx can create blob:https://example/guid) the client can write that security context’s origin as a URL (e.g. https://example/ in this case) into the MoTW to help ensure proper handling.
Origin-Laundering via Archives
One simple trick that attackers use to try to circumvent MotW protections is to enclose their data within an archive like a .ZIP, .7z, or .RAR file, or a virtual disk like a .iso file. Attackers may go further and add a password to block virus scanners; the password is provided to the victim in the attacking webpage or email.
In order to remain secure, archive extractors must correctly propagate the MotW from the archive file itself to each file extracted from the archive.
Despite being one of the worst ZIP clients available, Windows Explorer gets this right:
In contrast, 7-zip does not reliably get this right. Malware within a 7-zip archive can be extracted without propagation of the MotW. 7-zip v15.14 will add a MotW if you double-click an exe within an archive, but not if you extract it first. The older 7-zip v9.2 did not tag with MotW either way.
A file’s Zone.Identifier stream can be lost if the file is copied to a drive that does not support alternate streams (e.g. a FAT32-formatted USB key), or if it is copied via a tool that does not copy alternate streams (e.g. Remote Desktop, various cloud file-synchronization utilities).
SmartScreen & the User may unmark
Finally, users may unmark files using the Unblock button on the file’s Properties dialog in Windows Explorer, or by unticking the “Always ask before opening this file” checkbox on the pre-launch security prompt. The HideZoneInfoOnProperties policy can be used to hide these UIs from the user.
Similarly, on systems with Microsoft SmartScreen, SmartScreen AppRep itself may unmark the file (actually, it replaces the ZoneId with an (undocumented) field of AppZoneId=4). Update March 2022: SmartScreen now seems to have changed to write a separate SmartScreen alternate stream from Edge, rather than modifying the Zone.Identifier stream. Update Feb 2023: When executing a program from the Windows Shell in Win11, the Zone.Identifier stream is removed from the file after the AppRep check.
File Opener/Launcher must participate
In order for a MotW to have an impact, the application that opens the file must check the zone of the file.
When launching a file, to have the MotW consulted, use ShellExecuteEx. The CreateProcess API does not care about the MotW.
ShellExecuteEx() callers may ignore the mark by passing SEE_MASK_NOZONECHECKS.
An environment variable named SEE_MASK_NOZONECHECKS with value 1 will disable the Zone checking inside ShellExecute().
1 This is an oversimplification. The ZoneIdvalue written is the least-privileged zone of the calculated zones for the caller-supplied Source URL and the Referrer URL. Interestingly, this means that if you download a Trusted Zone file from a link on an Internet Zone webpage, it will be treated as if it had originated from the Internet Zone.
There are other (surprising) nuances as well.
First, if either the Source or Referrer is not supplied, it is treated as “Local Machine Zone”; a caller can pass about:internet as a generic “Internet Zone” URL, or about:untrusted as a generic “Restricted Sites” URL. Using a generic URL can be necessary if the file is sourced from a non-basic URL like blob: or one that is over 2083 characters (INTERNET_MAX_URL_LENGTH).
Second, the determination of what zone is “least-privileged” diverges from the standard order for Windows Security Zones. The MoTW code orders the Zones as Untrusted < Internet < Intranet < Local Machine < Trusted. The standard ordering in URLMon is Untrusted < Internet < Trusted < Intranet < Local Machine.
Third, the Zone Marking code is hard-coded to avoid writing a MoTW to a file whose “least-privileged” zone is Local Machine. This seems reasonable (otherwise copying a file from the local computer to the local computer could add a MoTW), but, coupled with the non-standard ordering of Zones, results in a surprising outcome. To wit, if you call the API with a Source URL in the Trusted Zone, but do not supply a Referrer URL (say, because the user entered the URL in the address bar, or the download link has a rel=noreferrer attribute), no MoTW is written to the file (test case).
2 The Windows Zone identifier constants are Restricted Zone=4, Internet=3, Trusted Zone=2, Intranet=1. The Local Machine Zone is 0, but the API will not write a Zone.Identifier stream for a file whose ZoneId is 0.